
https://youtu.be/SpfIwlAYaKk
2023-10-14 21:19:03
PostgreSQL Tutorial for Beginners

Welcome to this comprehensive video course about Postgres , QL , one of the world's most advanced and robust open source relational database systems , whether you're a beginner , looking to start your first database or a seasoned developer , aiming to scale and optimize complex data structures .
This course has something valuable for you dive in as Alex unpacks the essentials , advanced features and best practices to harness the full power of post graph QL in your applications .
Welcome to the exciting world of Post SQL .
If you like me and you're eager to unlock the power of one of the most robust and versatile relational database management systems in existence , you've come to the right place in today's data driven landscape .
Positive SQL stands as a pillar of reliability , scalability and extensibility , whether you are a citizen database professional looking to enhance your skills or like me , a newcomer intrigued by the possibilities of managing and querying data efficiently .

This course is our gateway to mastering Post SQL over the course of our program , we will embark on a comprehensive journey through the fundamentals and advanced aspects of FRE SQL .
From setting up our further database to tim complex queries will equip ourselves with the knowledge and practical skill needed to work with data effectively .
I am dedicated to guide you every step of the way ensuring that we not only grasp the core concepts but also gain hands on experience to practical exercises and real world scenarios .
By the end of this course , we you'll be proficient in designing databases , leveraging progress , SQL , uh advanced features and solving real world challenges .
Whether you're pursuing a career in data management , web development or simply looking to boost our database expertise .

Postgres SQL is a mass note and so join us on this educational journey and let's explore the dynamic world of Postgres SQL together , get ready to unlock the potential of your data and open doors to wide array of career opportunities .
Hello everyone , welcome to the installation and setup leisure in this video , we're going to install Postgres SQL and PG admin .
Now you may be wondering what are those ?
Let's start with Postgres SQL , also known as Postgres which is an open source relational database management system L DB MS that is known for its robustness , reliability and advanced features .
It provides a powerful and scalable platform for managing large volumes of structured data post gray could supports a wide range of data types , indexing options and query optimization techniques making it suitable for various applications .

It offers ac ad autom consistency , isolation and durability , compliance and supports transaction which ensure data integrity and reliability with its extensibility and support for various programming languages .
Positive SQL is widely used in enterprise environments and by developers for building high performance data driven applications .
Now , what is PG admin ?
PG admin is a free open source administration and develop platform for managing post grade SQL databases .
It provides a graphical using an interface that allows users to interact with the database and perform various administrative tasks .
Pg Admin offers a range of features including database object management such as creating tables , views and indexes , query and editing data monitoring , database activity and managing server settings .

It provides a user friendly environment for database administration and developers to efficiently work with progress SQL databases allowing them to visually design database schemas , write any queries and monitor database performers .
PG admin is available for multiple operating systems and is widely used as a primary tool for post grade database administration .
A shorter definition for what positive SQL and PG admin is , is that positive SQL is the engine that sorts data and read queries and returns information .
And the PG admin is a graphical user interface for connecting with post SQL note .
Please make sure to follow each step in order carefully .
Common confusion points do not open the DVD rental data file directly .
And also another very important thing is to not forget the Postgres SQL password .

So this is very important to have in mind and uh to help avoid any missteps .
I've numbered them and I'll present them in order in the correct order for you .
So let's get started .
Step one , let's download and install post SQL .
So open a browser and type post grass SQL presenter .
And we need to go to this page where it says Postgres SQL dot org .
Click on this link and this page may change from time to time .
But the important thing here is to go to the downloading page and we can go to the downloading page by clicking on this button or by clicking up here on download .
I'm gonna click up here on download and here we have different versions for different operating systems like Linux , Mac X and Windows .
I have Windows .
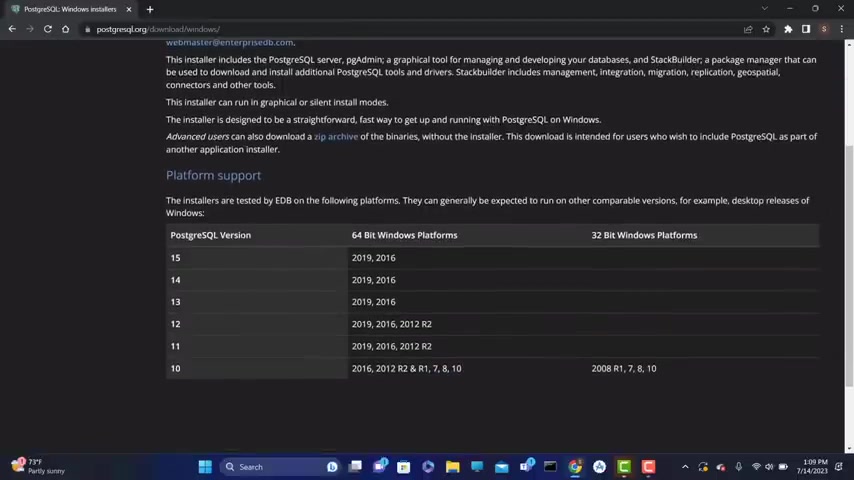
So I'm gonna select Windows for uh me and down here we have pods spl versions and we have the versions for a 64 bit of windows .
And as you can see down here , uh there is also a version for a 32 bit version of windows .
So if you have a 32 bit version of Windows , you need to download this version that you see here .
Alright , now I will go up and I will click download the installer and I will go on the right hand side here down here where it says Windows X 886 64 .
I'm gonna click on this button and now post sequel is gonna be downloading as you can see down here .
And if you have a different browser , you'll see this in a different place .
All right , once the downloading is finished , just open this file .
So I'm gonna open this file .
Let's close the browser because we don't need the browser anymore .
And if the file didn't open for you for you , like in my case , just go to downloads or to the folder where you downloaded the the file is go to download .
Let's double click on post gray sequel .
He knows it's going to open .
Click on .
Yes .
It's asking us if you're allowed to have to make changes to a device .
Click on .
Yes .
All right .
Here we have it the installation window of post graph SQL and here we need to click on next .
Here is the location .
What is gonna be installed ?
I'm gonna click on next .
I'm gonna keep the default location .
These are uh the software that's gonna be installed with uh post graph SQL .
I'm gonna keep the default selection .
So click on next .
Next .
We have the data directory and here I'm going to keep the default directory .
So I'm going to click on next .
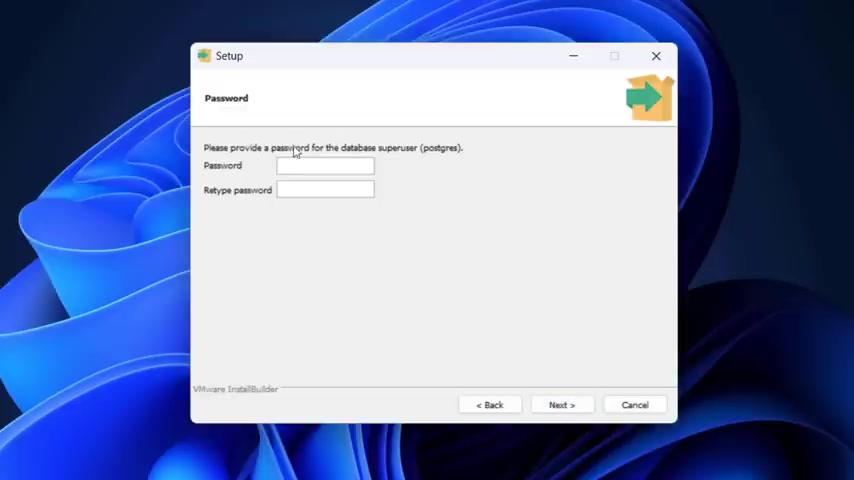
And now we need to create a password and this is extremely important to not forget the , do not forget the password that we type here .
So I'm gonna type here password as the password .
Click on next and here we have the port you , you and uh this is the default , as you can see here is just 5432 .
Then I'm gonna click on next here and here we have select the local to be used by the new database cluster .
I'm gonna keep the default lo click on next , gonna click on next , next again , click on next again .
And now pore sequel is going to be installed on my computer .
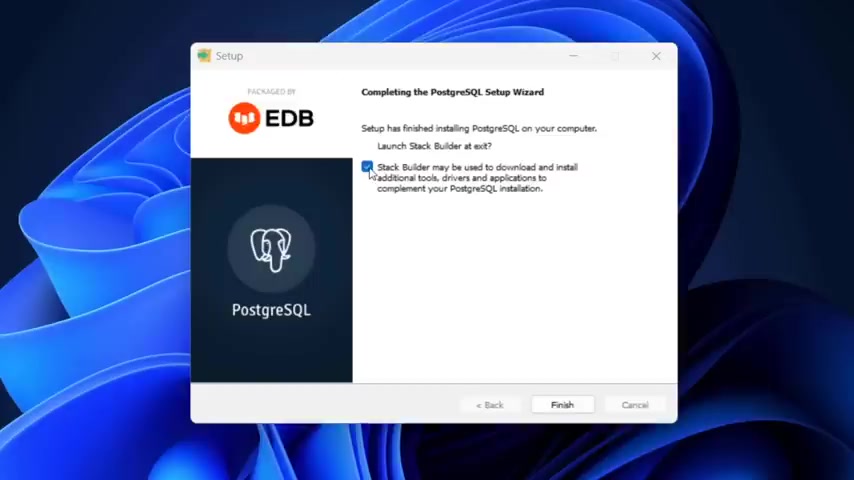
All right , once the installation is finished , just uncheck this stack builder because you don't need to open that and click on finish .
Now , we're going to move to step two , which is to download and install PG admin .
So I'm gonna type PG admin .
Need to go .
Here is PG admin dot org .
Click on this link .
Let's click on , agree .
You go to download and we a re gonna select here , Windows .
If you have a different , you have some vendors here of uh Linux and we have uh I'm gonna select Windows for because I have windows .
So let's click on windows .
As you can see there is also no , then they no longer have version three .
But uh we're gonna use BPG admin four .
So click on windows and here we have different versions .
I'm gonna click on this version for V 74 .
So click on that and here we need to download this executable file .
So I'm gonna click on this executable file and now PGR is going to be done on my computer .
Once the downline thing is finished , just open this file , let's close the browser again .
If it doesn't open the file for you like in my case , go to the folder where you downloaded pard , go to downloads and we have here to be jasmine .
I'm gonna double click on it .
I'm gonna click here .
Install for me .
Only recommended .
I'm gonna click on next .
I'm going to accept the license agreement .
I'm gonna click on next and this is the location where it's going to be installed .
I'm gonna click on next and now I'm gonna click here on next to install PJ admin .
So click on next and install now .
The installation is finished .
Let's click on finish .
Let's move to step three , step three , download but do not directly open DVD rental data file and DVD rental data file .
It's a data , it's a compressed version of a database that you're gonna use throughout this course .
And uh in downloads , if I go in downloads , I already have this file downloaded .
As you can see here , we have DVD rental .
So do not try to open that .
And uh what uh I need you to do is to go to this particular video under resources , click on resources and you'll see DVD rental uh file and click on the f the , the file and that file is gonna be downloading our computer .
This is what you need to do .
And after that step four is to restart your computer .
So let's restart our computer .
Step number five , restore the database and there is a quick note here and that is to ignore the F AC code if it appears and this can appear because it will think that you restore the database uh twice .
So let's open PGR domain .
So I'm gonna type PGR .
Let's click on run as administrator .
It's not asking us if you allow this have to make changes to a device .
Click on .
Yes .
Is it starting PG four ?
Right ?
It says loading PGLM four V 74 and this is not , this is not going to work .
It will show this loading PGA min uh indefinitely .
And th th this happens because when we installed the post grade sequel , we also installed PG admin four .
And after that , I installed , I installed the PG admin again .
And uh because of that , that generates an error and it cannot uh open the PG admin .
So what you need to do is to go to control panel .
So go to control panel , go to uninstall a program .
Let's search for for post gra SQL .
Let's click here , let's uninstall it .
And we're going to uninstall specifically PG admin four because that is the , the problem that is what generates the error .
So let's select individ individual components , click on next and make sure to check PG admin four and click on next .
Now we we wait a little bit , right ?
The installation is completed .
Now , let's close this , let's type PG admin PG admin and let's run it as an administrator as you can see here .
You can uh run it because you have it installed twice .

So run it as an administrator click on this because it's asking us if you allow this app to make changes to a device is just starting PG admin for .
And here you need to create a master password and uh note that this password can be anything you want .
And uh this is the password for the PG admin , not for post grade SQL .
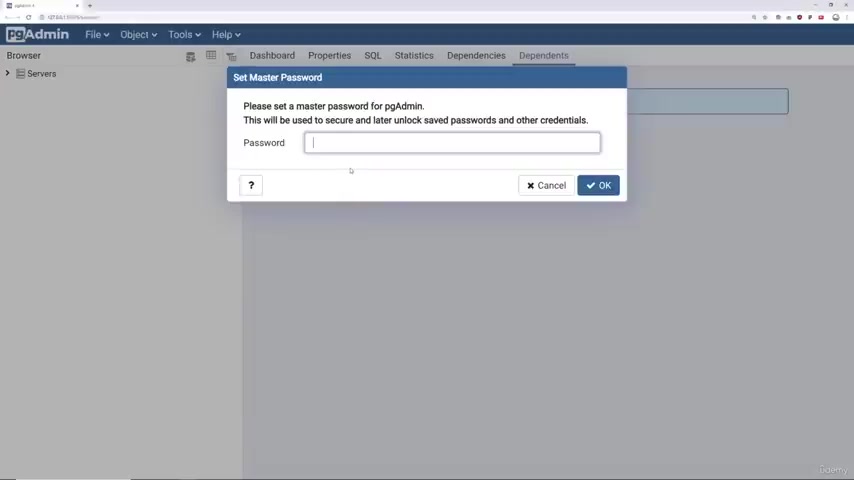
And I'm gonna type uh as the password password and they're not gonna click on .
Ok .
Then on the left hand side , we have servers and I'm gonna click on servers and now you see this pop up and you don't need to type the password that we created when we install post grade SQL .
So I'm gonna type here password and click on .
Ok .
And that is gonna open this I already have here .
Uh um Actually I don't have the database .
What I'll need to do next is to right , click here .
Go to create actually above create database .
Let's call it DVD rental .
Let's click on save .
So now we have a database DVD rental .
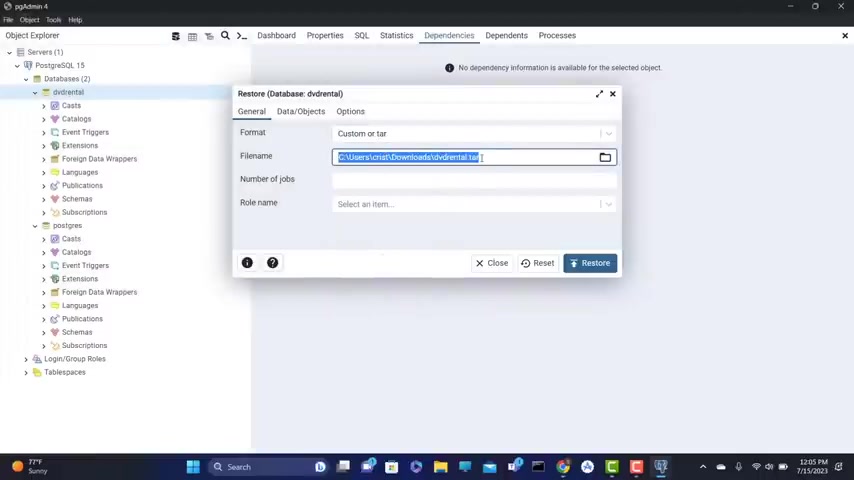
Now , what we need to do here is right click and uh go to restore and now we're going to reference our dividend rental tar files .
I'm gonna click here and for , instead of custom files here , select all files go to downloads and here we have DVD rental or you can copy this uh location directly from uh where it is in your PC and paste it here and click on restore .
And now it's gonna restore the database , which is gonna have some information .
So which you gonna have some data that you're gonna use uh to explain many things .
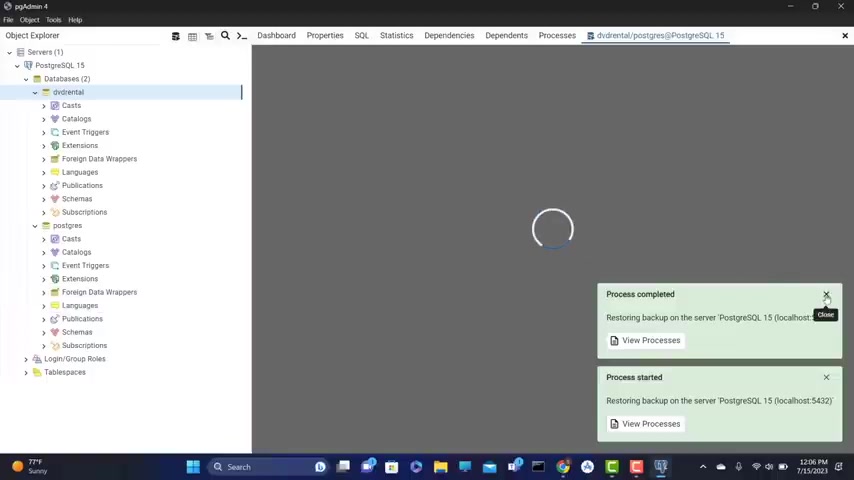
So let's click on restore and it says process started restoring back on several progress SQL .
And it says process completed .
That means everything worked fine .
Let's give it a refresh .
So let's click on refresh .
Now .
The next very important thing is to right .
Click here , go to query tool and now the dust is gonna open a window here .
You can close those and let's test our database .
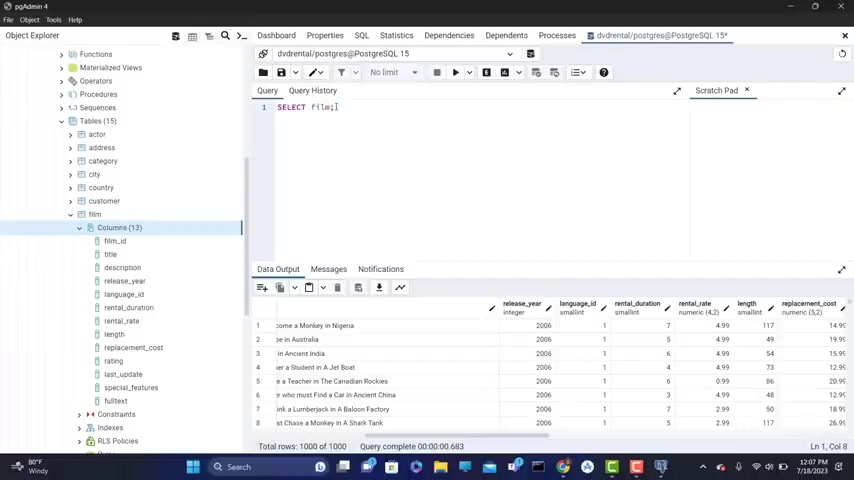
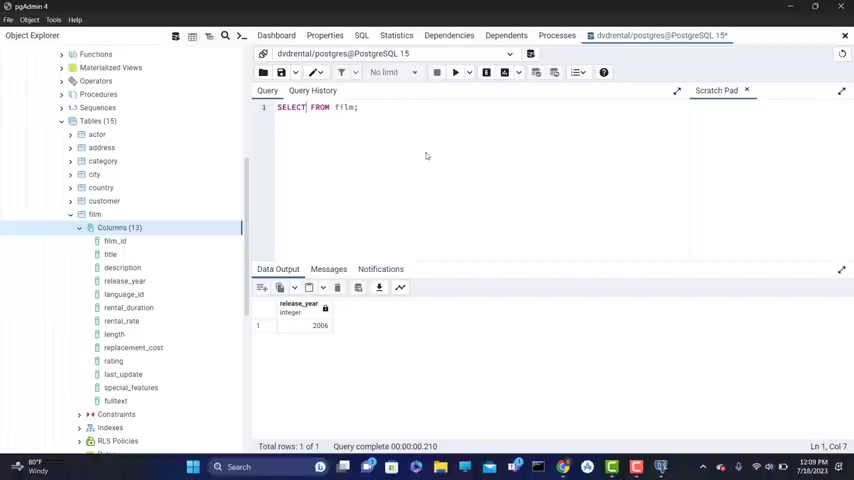
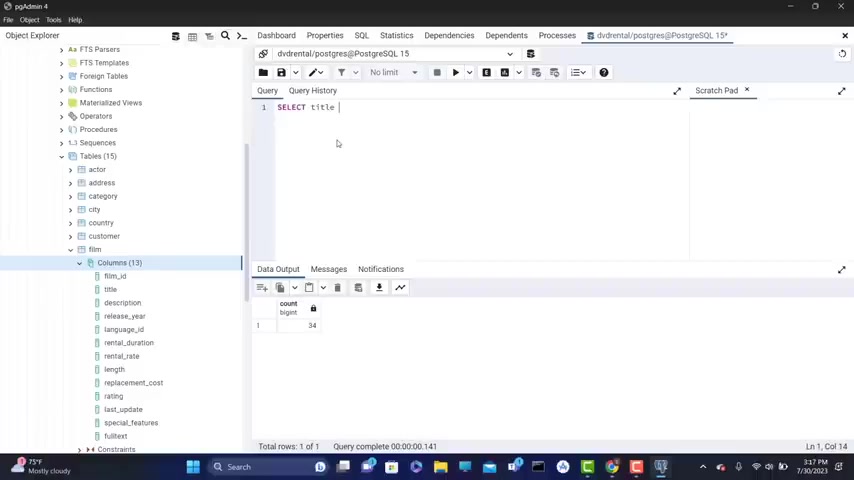
So I'm gonna type here select , gonna look at all of those in more detail in the next videos , asterisks from and I type film semi colon .
Again , I'm gonna explain all of this in the next videos and click on this round button .
I now have data being outputted down here as you can see .
So everything works fine .
Welcome back .
Now it's time to start a discussion about the select statement .
So what is the select statement ?
The select statement is used to retrieve data from one or more database tables .

It allows you to specify the columns , you want to retrieve the tables from which you want to retrieve the data and any conditions that must be met for the data to be included in the result set .
Later we learn how to combine select statement with other SQL select statements to perform more complex queries .
Here is how the syntax of select statement looks like .
So we have select , then we have the column name , then we have the keyword from and the table name .
And uh now this is a , this is how uh this will look , let's say that we have uh a few tables which a re I created here , a few tables which a re populated with data .
And let's say that you want to retrieve some data from those tables based on what I uh told you what you need to do here is to type select first .
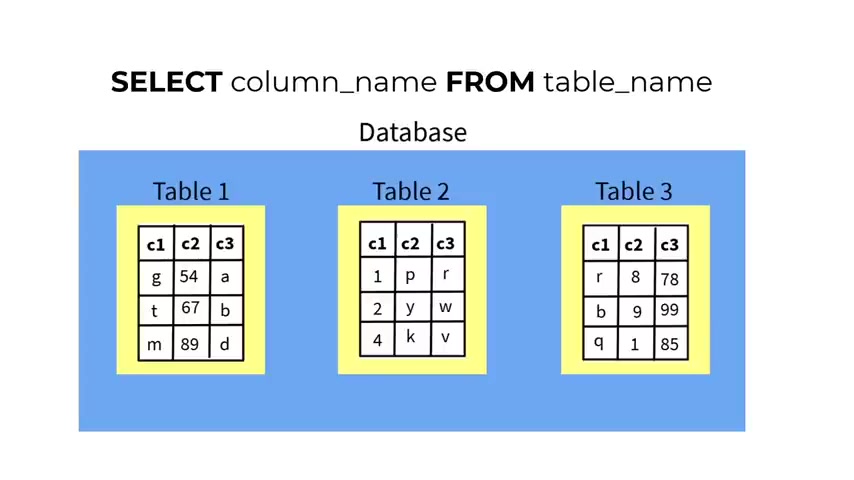
But , but first of all , you need to think about um what from what table you want to retrieve the data .
So the table name , let's say that I want to retrieve that , that data from the table one .
So with that in mind , you type the select keyword , the column name , let's say C one and it will retrieve all the data in the column , C one from the table table one .
So in this way , you will get all the data for , for uh for , for the column one , C one in from the table one .
Now let's say that you want to retrieve two columns , you can do that by putting comma .
So you can , you can type again , select you , you type the column name , let's say C one comma and C two and that now it , it will return back all the data from the uh column one and column two from the C one and C two .
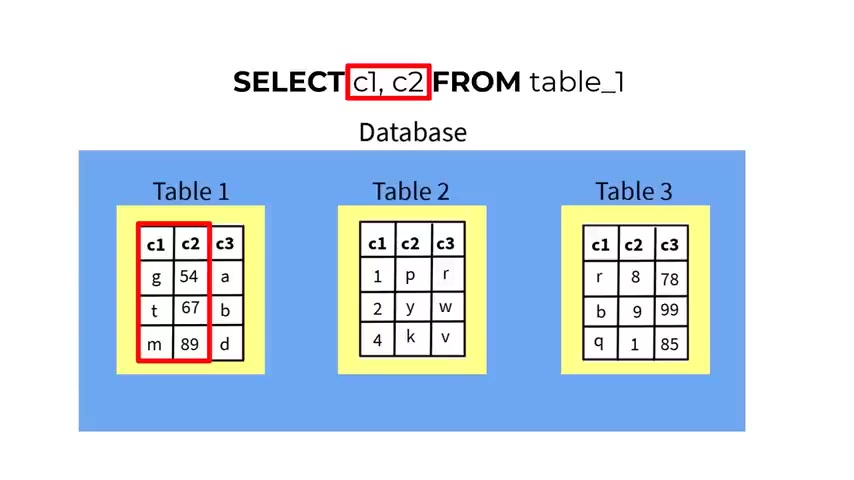
Let's say that you want to retrieve data from a different table .
Not just do that .
If you go again , type select , let's say C one and C two .
Again , we , we , we get those , the , the , the data from data for those columns .
And now we change the table na me , we , we type , let's say table three .
Now let's say that you want to retrieve all the data from a table .
Of course , that you can type select and you type the , the column name , C one , C two and C three from the table name .
But uh what if you have uh hundreds or thousands of tables in that way in that uh in the , in the because of that , you will not be , it will not be practically possible to type all of that .
And in order to get the data from all the columns , you need to type select asterisks from and the table name , table one .
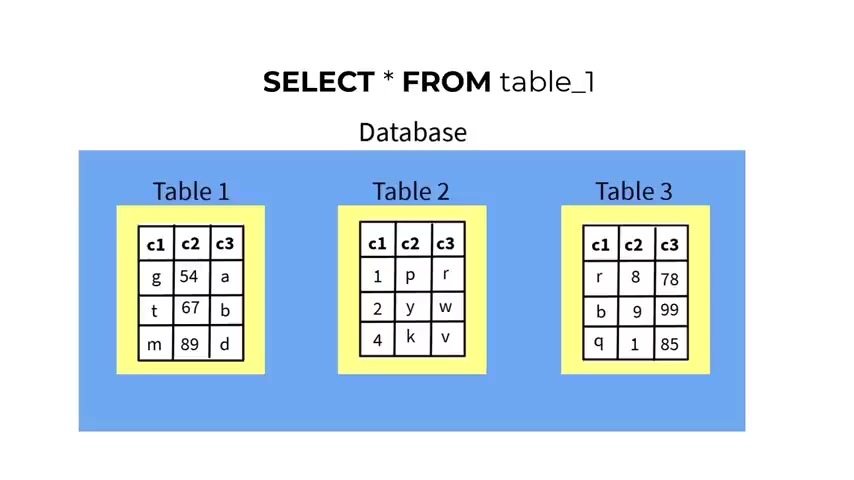
And that is gonna return all the data from the uh table one , all the columns .
So this is what uh uh it will do .
No one more thing .
The select keyword is used to specify as I said , the columns you want to retrieve and you can specify individual column names separated by commas as I said , or you can use an asterisk to select all the columns from the specified tables .
But um uh in uh practice , it's better not to use uh the asterisk when you don't need to use the asterisk because it will uh get a lot of data and uh it will uh make the communication between the database and the , the software that you're using uh slower .
Alright .
Now let's mo move to post SQL and let's type some se uh select statements .
All right .
So I'm gonna open PG admin run as administrator .
Click on , we wait a little bit until uh PG admin starts , right ?
PJ admin opened .
Let's click on here on this Great R in front of servers .
Now it's asking us for the password .
Let's type password and let's click here to save puzzle .
Do not type it again .
Every time we open the server now it's going to open the server .
We have our database here .
I'm gonna click there and we have DVD rental the database that we created and post the database that was provided in place for us .
Now , let's say that I want to query and I want to query .
So I'm gonna right , click on the database that I want to query , go to query tool that is gonna open the query window , right ?
And now here I can type a S A statement .
But first before I do that , let's go to schema to see how our uh how the structure of our database looks .
So click on schemas .
Go to , let me see tables to see what tables we have .
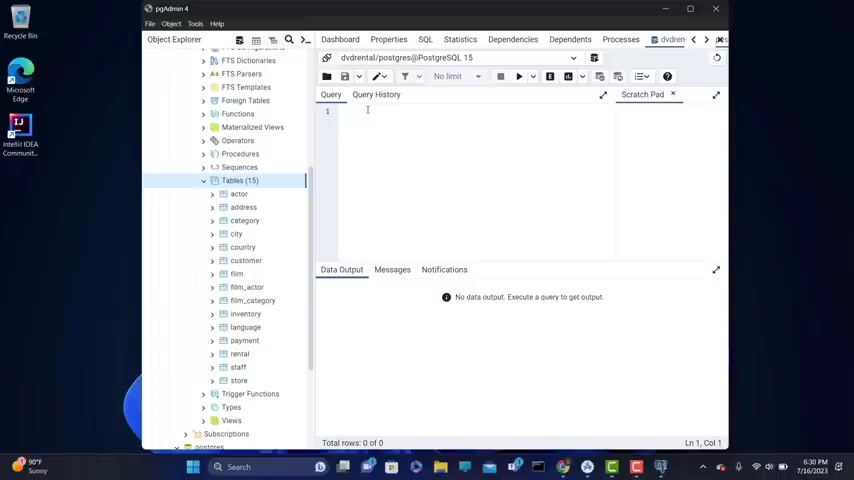
And as you can see here , we have the tables , actor address C category , city country and so on .
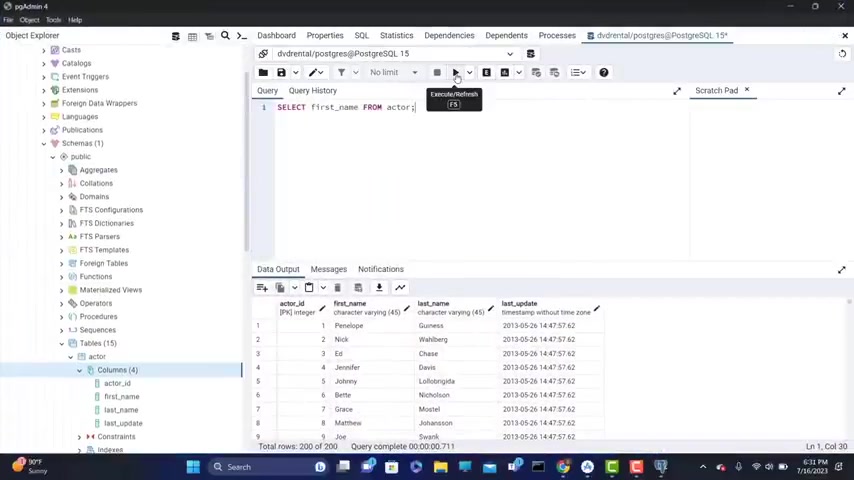
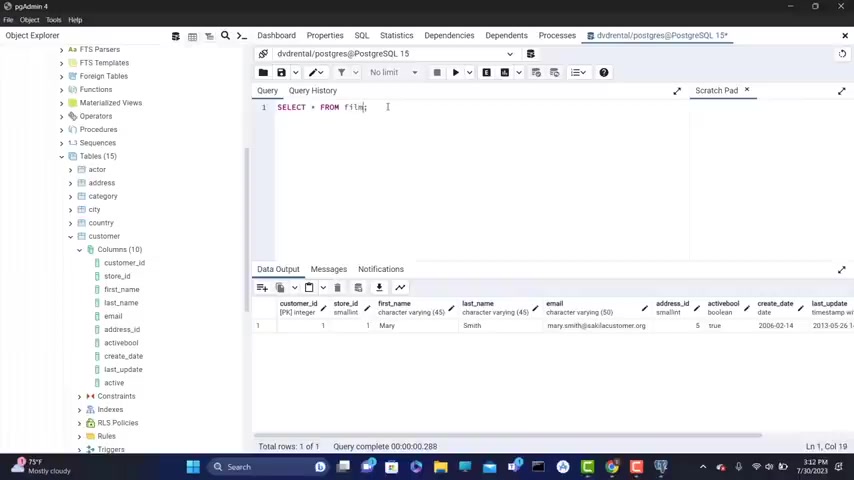
Now , let's say that I want to select all the columns from the table actor .
Why I select with capital letters from actor semi colon .
Now let's run this and now it's returning all the actors from uh from uh so it's returning all the actors from the table actor .
Now , let's say that I want to get only the first name and the last name in order to do that , I'm gonna delete this .
I'm gonna type and uh to see what kind of structure the table has , you can right click in front of it and you'll see you have what columns it has has actor ID uh first NA me and last NA me .
So let's type first na me first underscore na me .
Come on and let's actually for only ask for the first na me from .
So you don't put the asterisks actor semi colon .
Let's increase this .
Let's click on and we get all the first NA mes of the all the actors in our uh table uh actor as you can see down here in the data output .
So everything works fine and you can put a comma here and you can get the last name too .
So the type last name because as you can see .
It also has a last name and if you on this .
All right .
Oh , I should put a camera there .
Let's run it again .
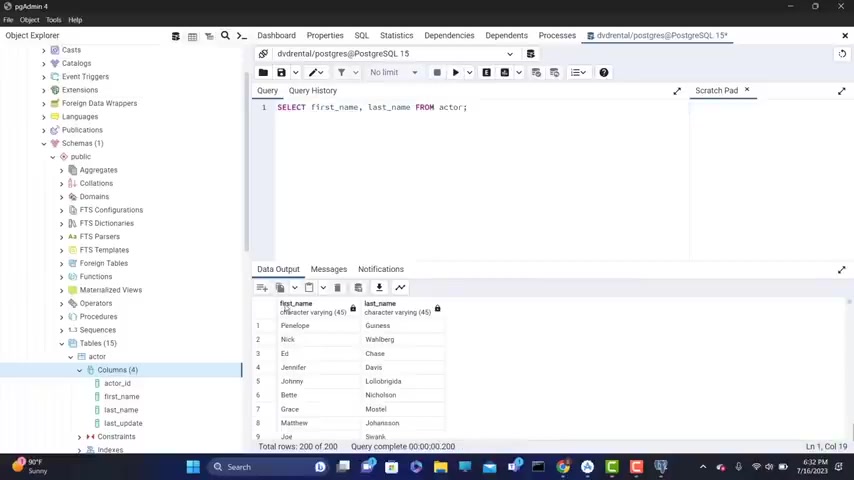
So you have the first name as you can see here and the last name .
So now it's returning the first name and the last name and they , they don't need to be in this order .
So , so the first name doesn't have to be , uh , before the last name , I can't have your last name , comma first name .
Now , if I could go on , this will still work .
So everything is quite is working the sa me now as uh you , you see here the S the SQL uh uh keywords , a re capitalised , but you c you can type them lower case letters and it will still work .
But uh it's a good convention to capitalise them to make sure that you have , you have uh you can see the distinction between the SQL uh statements and the column NA Mes , right ?
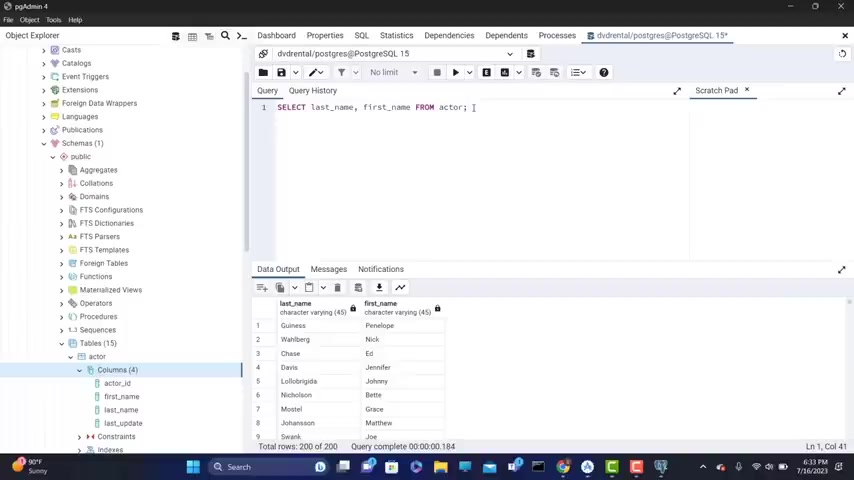
So always capitalise the SQL um he orders if you want to call or anything like that .
All right .
So this is our discussion for this video .
I hope a lot you enjoyed and see you on the next video .
Welcome back in this video .
We a re going to do a challenge with the select statement and here is how the challenge structure is gonna look like first , we're gonna have a business situation because often in uh when working with the eski databases , you will have a business situation and you need to translate to uh get that business situations and to translate it into a query .
So this is what uh we , we'll uh do first .
If you will see the business situation , then we have the challenge question .
And this is more uh about SQL and here gonna uh ask the , the actual challenge , the actual que question .
Next , we have the expected answer .

And here I'm gonna show you what the expected answer with the with go with the is gonna look like next we have the hints .
So I'm gonna give you some uh hints ab uh about uh the challenge .
So it will be easier for you to solve .
And finally , I'm going to show the solution .
So let's start with the first one , the situation .
So what we want to see is the payment date of our existing customers .
So this is the situation .
Next , we have the challenge .
You need to use the select statement to grab the customer id of every customer and the payment date and the , the payment date and the amount .
So you need to do this .
This is the challenge .

And uh if you already know how to use this , uh how to solve this challenge , you can uh jump in and uh try t try to , yeah , I identify the table from which you can get this data and uh run the , the , the run the query statement .
So this is what we're gonna do and now I'm gonna show you the expected answers .
And uh this is very important , this might not be displayed the exact SA me model because uh uh how uh SQL works is that it uh tries to return the data in the most efficient way .
But later , you will see how we can actually control uh how , how the data is ordered .
But we're gonna look at that in uh in uh the next videos .
Now we're not gonna do that here .
And next we have the hints .

So the hint is to use the payment table and you can use the table to drop down to view to , to drop down to view what columns are available .
So this is what you could do .
Next , we have the solution and the solution is let's open PG admin .
So let's open PG admin .
So let's open PG admin .
Let's run it as an administrator .
Click on .
Yes .
Now PJ is gonna start .
All right .
So PG have been started , let's open our server and now it's not asking us for the password because previously we saved the password and let's open the query tool because we're gonna type a query .
And uh if you figure out how to solve this challenge , write me in the comments .
The thing that you need to do is to go to payment because here we gonna have uh our columns .
I'm gonna click on this great out in front of columns .
And here we have customer ID amount and the payment date .
So in the challenge , I said that you need to get .
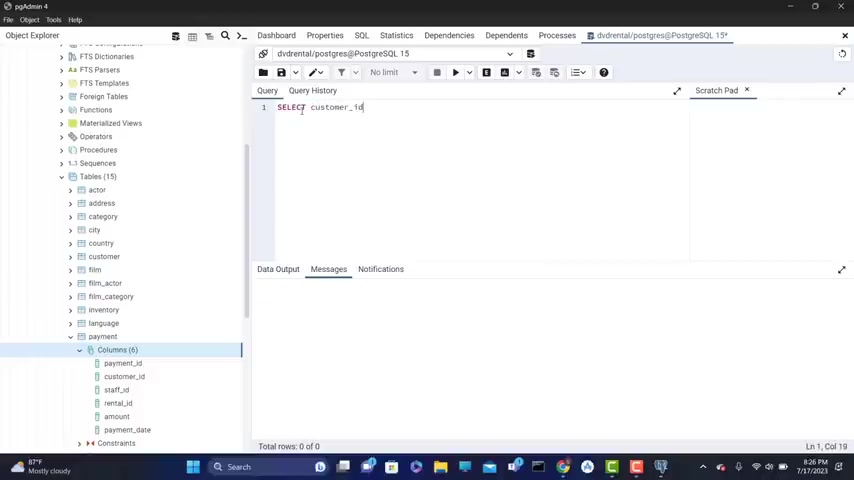
So I'm going to type select and I'll type cast the more ID comma amount comma and payment date from and the name of the table , which is payment payment .
And I'll put a semi colon to indicate that this is the end of the query , But it this can work uh also without the , the semi colon .
But I'm gonna put semi colon and let's run our query and we have the customer ID , we have as you can see customer ID , the amount and the payment date .
So everything works fine .
I hope that you figure out how to solve this challenge and see you on the next video .
Welcome back .

Now it's time to start a discussion about the select distinct statement in SQL .
So in SQL , the distinct statement is used to filter the result set of a query and retrieve only unique rows from the specified column or combination of columns .
It is particularly useful when you want to eliminate the duplicate records from the query results .
So this is uh what the distinct A is gonna do .
Now , the syntax for using the distinct statement is straightforward , you simply place the key distinct immediately after the select clause followed by the column name or names for which you want to retrieve the distinct values .
It is the basic syntax , you have select distinct column from and the table name .
So this is the syntax of the distinct statement .
Now , if you want to clarify which column the distinct is being applied to , we can also use parenthesis to for that .

So you can type select distinct parenthesis , the name of the column from and the table name .
In this way , you'll make it more clear what uh data you want to receive .
Now , let's break down how the distinct statement works .
First , the SQL query is executed as usual uh fetching the da data from the specified table or tables .
Secondly , the query engine then removes any duplicate rows from the result set based on the column specified after the distinct keyword .
And third only the first occurrence of each unique combination of values in the specified columns is returned in the result set .
So we will not have duplicates .
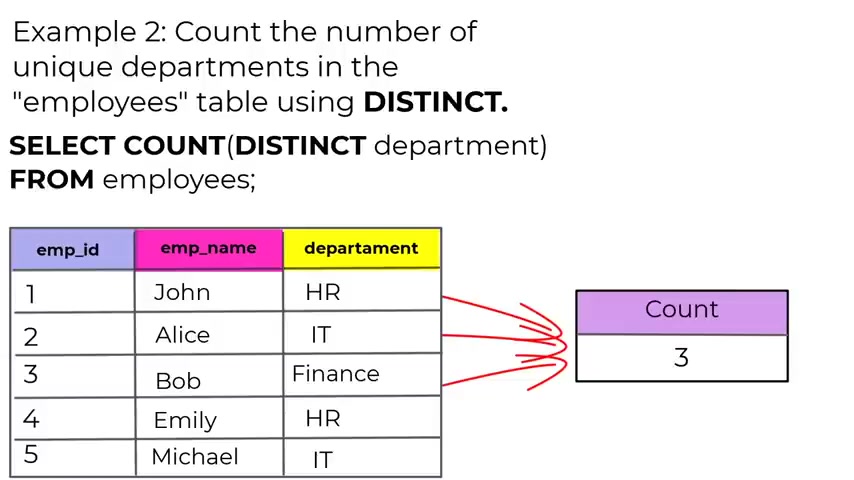
No , let's consider this table called employees with the following data .
So we have the employee ID , the first name , last name , the department .
And as you can see in this uh table , the , the John is uh present twice .
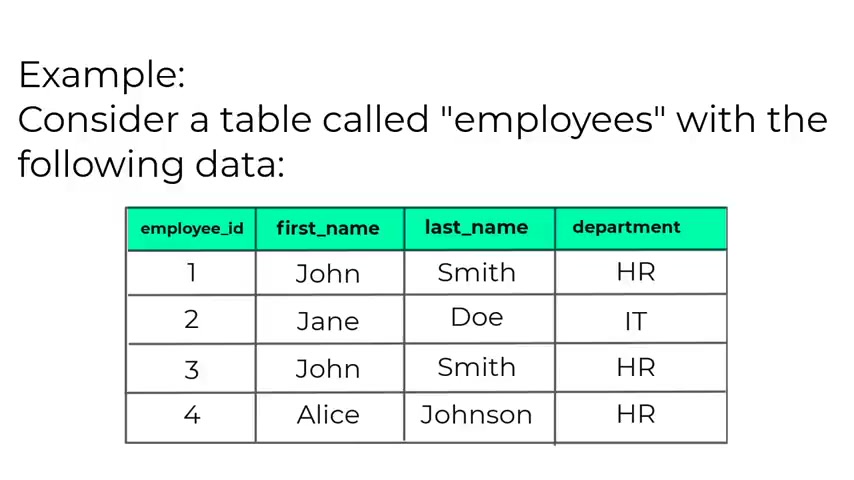
So we have John Smith , John Smith and we have the also the same department .
Now , this can be a duplicate but it can also not be a duplicate .
Maybe there are two persons with the same name working in the same department .
So what the distinct keyword is gonna do is it , it will uh answer to the question , what are the unique first names in the table ?
Let's say that you want to retrieve the first name and the last name .
So if you , if you use the distinct keyword , it will answer to the question , what are the unique first name and last names in the in the table ?
So this is what he is doing .
And um so uh as I said , given the , this example , we don't really know if the person with the same name , John was a duplicate entry or two different people with the same first name , last name and department .
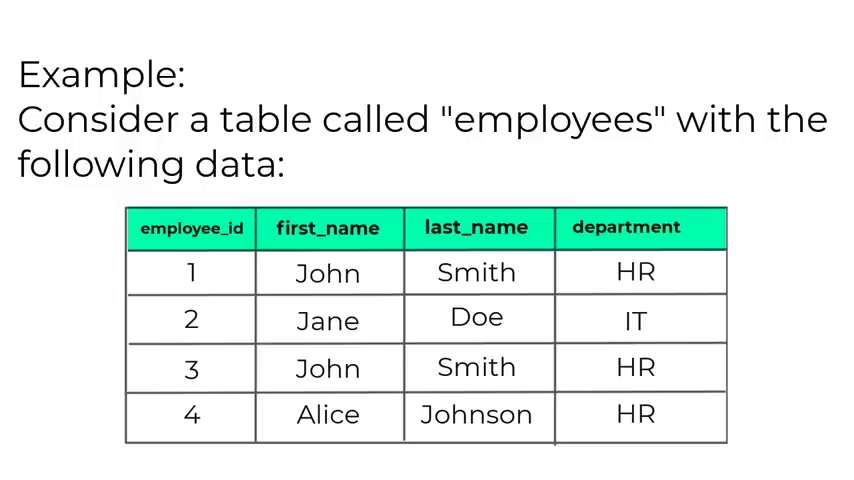
So uh again , the distinct returns uh only the unique entries .
So this is what distinct is doing now , if you run the following query , so you type select distinct first name , last name from employees .
This will be the result .
You have the first name John , last name Smith , you have Jane do , then you have first name for the Alice and Johnson .
So this will be the the result if you use the distinct uh statement .
All right , now let's move to Postgres equal to work with distinct statement .
So let's open PG admin , run it as administrator .
I , Jasmin will start in a short moment .
All right , let's open the server .

Let's open the cool tool quite all .
And I'll type here select .
So I'm gonna select all from the film table .
You can see the film table down here , literally go around as you can see , we have the film ID , the title and description .
And if you go to the right , we also have the release here , language ID , rental direct , all of this rental rate length , all of those columns .
And uh if you want , you take a note , what is the co what columns uh the film has here simply by uh clicking on this greater arrow , greater arrow here in front of columns and you sell the columns here .
Now , let's say that I want to select the release year .
So I want to see what a re the unique release years for uh all of our movies .
I can , I can type , let's delete .
Uh Also the that I can type a distinct release just to make sure this is the same as the table name year from the now Fran .
Alright , so I typed it strongly .
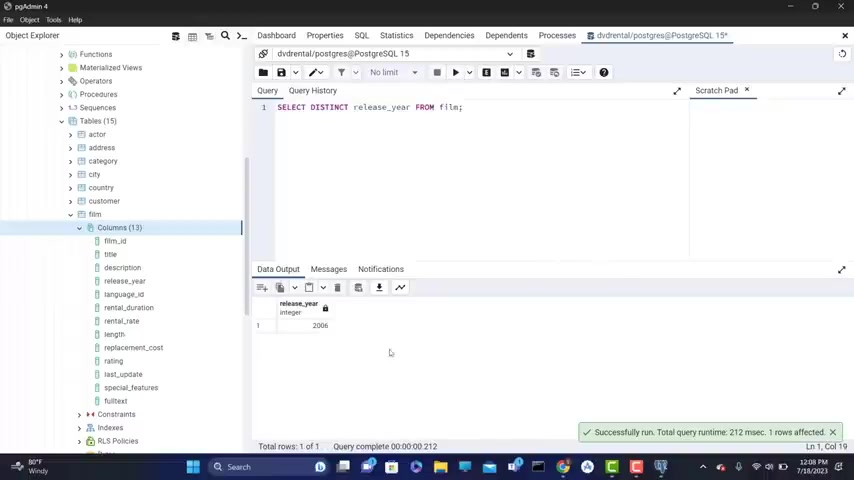
Let me see how it's release uh without the A here , let's try it again and we have only 2 , 2006 , only one occurrence of this uh yeah , oo of the year .
So we have only one occurrence , so one u unique year and on each one of the movies sort of published .
Now , we can also put parentheses , so we can put parenthesis around this and I can run this and I'll get the SA me output , right .
Let's also see how uh we can uh get the rental uh rate .
So release distinct legally that let's start here , select distant from , let's type .
Uh but let's type again , uh select f all from film because I want to see the columns .
So let's type again , let's run it .
Let's go to the right and we have rental uh rate .
So let's type here .
Let's do this , the type select .
So we , we're gonna see what uh how many r rental unique rental rates we have for this field rental underscore underscore eight from film based on this .
And we have all of those that you can see here .
So those a re the unique rental rates .
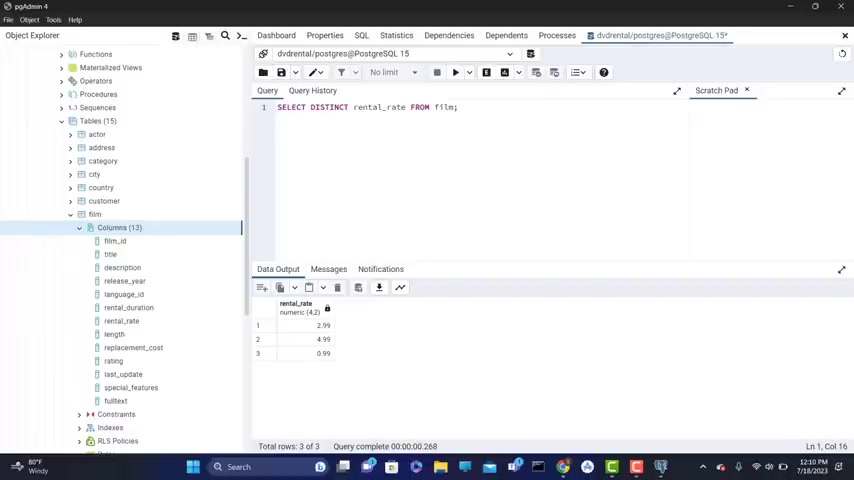
That's oh sorry , I forgot to put distinct because uh here we have uh as you can see uh duplicates type distinct Domini .
So let's start distinct .
Let's run it .
Alright .
So now we just re it returns the correct results .
So we have this one NNR rental rate , this one and this one , we have three rental , unique , three unique rental rates for all movies .
All right , I'm gonna need the video here and see you in the next video .
Welcome to the select distinct challenge in this challenge .
You're gonna follow the same structure as previously .
So when I have first the situation , they're not going to have the SQL challenge , they expect the results .
They're not going to give us some hints and finally we're going to have the solution .
So let's start with the situation .

Let's say that you are a data analyst working for some video rental store and the management has noticed that some customers have similar names and they want to identify the unique first names across all customers in the database .
So this is the situation that we're given .
The SQL challenge is to write a SQL query to retrieve all distinct first names of customers from the customer table .
So this is the challenge that we need to do .
Now , they expect the results .
Your SQL query should re result in a list of unique first names from the customer table .
Like you can see in this example without any specific sorting and the hints , we have the hints , use the select statement along with the distinct keyword to retrieve unique values and uh to select distinct value from a specific column , simply specify that column after the distinct keyword in the select clause .

So those a re the hints and the solution is this select distinct first name from customer .
So this is the solution to our challenge .
And in this challenge , we use the select statement with the distinct keyword to retrieve all unique first names from the customer table .
The query returns a list of distinct first names without any particular sorting , allowing the database to return the results in its natural order .
The database may retain the results in the order they were inserted or in any other internal order .
All right , I'm gonna win this video here and see you in the next video .
Welcome .
Back now , it's time to start a discussion about the count function .
But first , let's go through each aspect of the count function .
And SQL step by step using some simple tables to grasp the information better .
So the count function is equal .

The count function in SQL is an aggregate function that allows you to count the number of rows that match a specified condition within a table or a result set .
It tells a single value representing the count of rows that meet the criteria .
So this is what the count function is .
Why is count function useful .
The count function is valuable for various data analysis tasks .
It helps you to obtain statistical information about your data such as counting the number of records in a table , calculating the occurrence of a specific values in a column , finding the number of frauds that met certain conditions determining the number of unique values in a column when used with the distinct statement .
So this is why count uh function is useful for these reasons .
When to use the count function , you should use the count function .

When you need to determine the size of a table , the number of of rows , it contains count occurrences of specific values in a column .
Get the summary statistic statistic about your data .
So this is where you should use the count function , how to use the count function with the distinct statement .
This distinct keyword is used to eliminate , applicate draws from the result set .
When combined with count function , it allows you to count the number of unique values in a specific column .
Here is how we can use it .
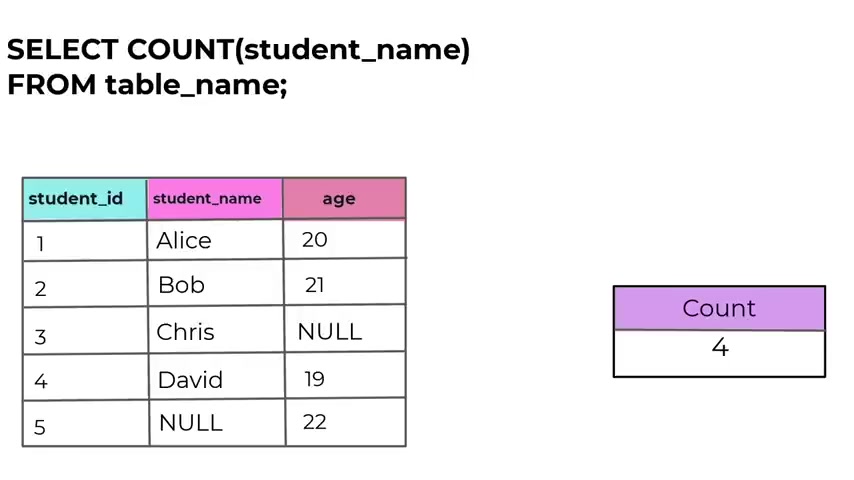
Let's consider a simple table called employees .
As you can see here , you have this table , you have the employee ID , the employee name , the department .
And uh and as you can see in this table , we have five rows and you have uh multiple departments but you have duplicated departments .

Uh As you can see here , we have the human resources twice and the , it also you have it twice .
Now , let's say that uh I want to count the number of uh employees in the table .
If I do that , the count is gonna return five and it's gonna return to five because you have , if you have 55 rows .
S so this is what uh that will .
Now example , two , let's count the number of unique departments in the employee table using distinct keyword .
So we're gonna type select count parenthesis , distinct department from employees .
And when you're gonna do that , the , the result is gonna be one because we have human resource two for finance and three for it .

So we have three unique departments in our department uh uh table uh on our depart department uh row .
So this is how we can use that .
And um let's wait in this example , we use the count function with a distinct statement to count the unique departments in the employee table , it returned the count as three because there are three unique departments , human resources , it and finance .
I hope that this example helps to illustrate the usage of uh the usage and usefulness of the count function .
And SQL particularly when combined with distinct statement , it allows you to perform various data analysis tasks and retrieve valuable information from your database .

All right .
Now let's move to post gray sequel to , to type some uh so called .
But before you open PG admin , let me first explain what is the difference between count with asterisks and count without asterisk .
So count with the column .
NA me and in SQL , the usage of count function with and without aster depends on what you want to count .
Let's explore the differences and when to use this form , count with parenthesis and asterisks .
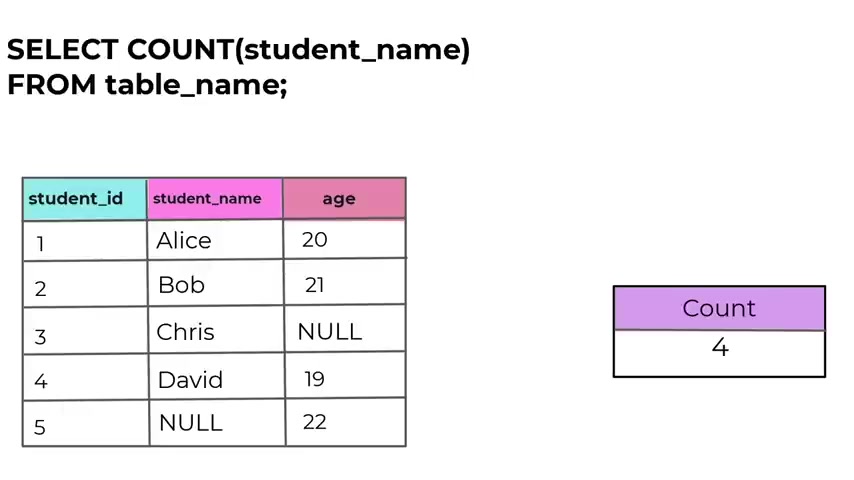
When you use count with parentheses and asterisks , it counts all the rows in the specified table regardless of the values in the columns .
Here is the syntax we have selected count parenthesis , asterisk from in the table name .

Now , let's see the usage use count with parenthesis and aster is when you want to count the total number of rows in a table , irrespective of whether there are null values or not , it counts all rows including those with null values in any column .
So this is what count acetic does .
Uh Let's consider an example .
Let's say that we have a um a table for the tables called students .
And we have the student that is to na me and age .
And as you can see for uh the student na me , we have right here , a null value .
So it do it do , it didn't provide uh a NA me now that it's not that is uh because by using count with asters , it will count even if you count it .

So lets say that you want to count uh the total uh numbers , the total number of uh of uh student na mes , it will count also the , the another one if you use count with AIS count with out asterisks .
So when to use count with the column name , so you specify a column name inside them inside the parenthesis of the count and it counts the number of non knu values in that particular column .
Here is the syntax .
So this is different .
This , this , this only counts the number of non null values usage .
You use count with column name .
When you want to count the occurrence of non null values in a specific column .
It ignores null values in the column and only counts non null entries example and continuing with the students table .
Let me show you all .
Let's wait a little bit .
If you type select count , let , let's make this .
So let me change something here .
If you type , select , count the student na me in parenthesis from students , the count is gonna return four because the count without asterisks is returning all the non null values .
So because the student na me five with the idea five is null is not gonna count , it's gonna return four .
So this is what uh count with the column , uh column name .
Uh uh He's doing alright .
Let's move to the next .
Now in this query count , student name only counts the annual values in the student name column , excluding the row with no name .

Hence , it returns the count of four when to use each form , use count without asterisks .
When you want to count all rows with , with asterisks , sorry , including those with no values or or when you want or when you don't have a specific column to count , but you still need to retrieve the total number of rows in the table .
Use count column name when you want to count the occurrences of non null values in a particular column , ignoring null entries .
This is useful when you want to analyze the distribution of frequency of non values in a specific attribute .
In summary , that the decision to use the count without or with or without assay depends on whatever you want to count all rows including nulls or you want to count only the occurrences of non null values in a specific column .

And you can choose the appropriate form based on your uh an analysis needs .
All right .
Let's move to the next slide in summary count with asterisks , counts all rows in the table including rows with null values in any column and count with column name counts .
The number of non null values in the specified column , ignoring rows with n null values in that column , choose the appropriate form of the count function based on your specific requirements .
If you want to count all the rows in the table , regardless of the null values , use count with asterisk if you want to count the number of non no values in a specified column , use count with the column name .
All right .
Now let's open PG admin .
All right , let's open PG admin .
Now let's run it as an administrator .
Let's open the server .
Let's open the curator in all time here .
Let's say that I want to get all the data from the payment table .
I will type select from payment semi colon .
Let's round this right now .
Let's say that I want to know the number of uh rows in this table .
What I can do is I can type here , select count aesthetics .
I'm gonna put parsis asterisks .
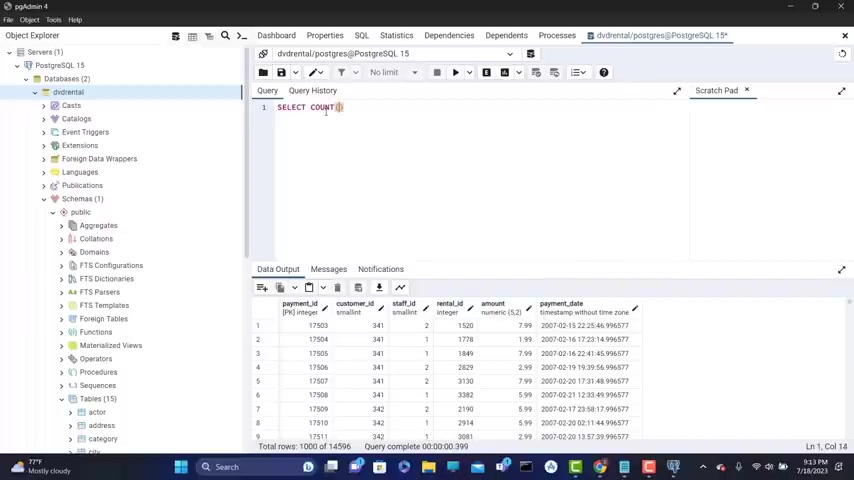
So parenthesis again , asterisks from payment and that is going to return the number of rows .
Let go the run and we have 40,596 .
Now you can do another way you can type here a mount , the name of , of a table .
Do not the na me of the , the , the , the na me of uh let me open this of a column and that will go , we're gonna return the sa me result .
As you can see here , everything works fine .
Now , next , let's say that I want to retrieve the actual number of the unique amounts .
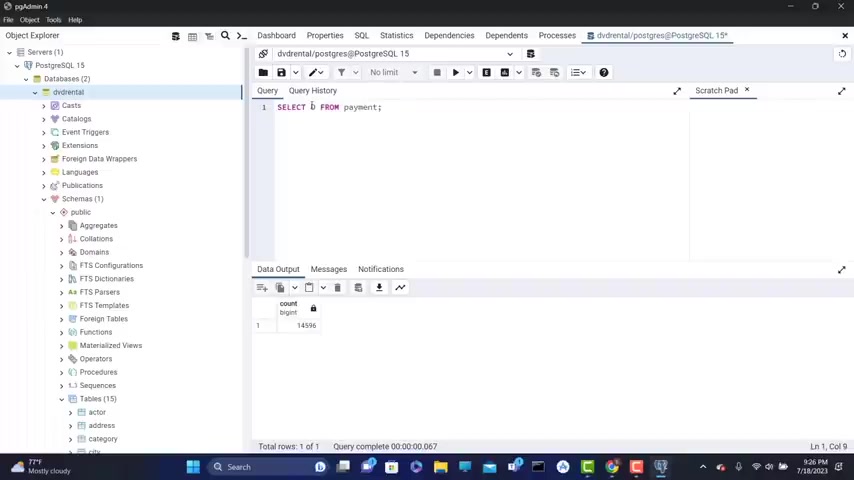
So I'm gonna type here select distinct a mount from payment .
So if you run this , we get our distinct A mounts .
Now , let's say that I want to get the number of th of those distinct A mounts .
How , how I'm gonna do that ?
This part is gonna return the number of distinct A mounts .
So we need to put here before count .
So that here count .
But this is we put our distinct inside the parenthesis , distinct A mount because that is gonna return the distinct A mount of uh uh payments .
And uh n now if this you get 19 and you can also put also this in parenthesis to make it more clear .
Another parent is here .
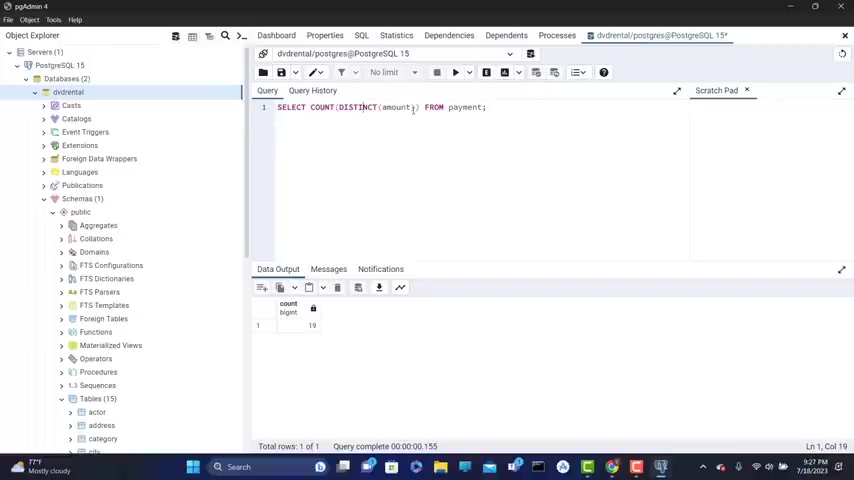
Hi Ferran get also 19 .
So this returns the number of unique amounts in our uh payment and the count is count is counting them .
So I'm gonna end this video here and see you in the next video .
Welcome back .
Now it's time to start a discussion about the select word statement in SQL .
So in SQL word statement is a crucial part of querying and filtering data in a relational database .
It allows you to retrieve specific rows from a table that match certain conditions in this detail step by step explanation .
I will cover everything you need to know about the SQL where statement basic syntax , the work clause is typically used in combination with the select statement to filter rows based on specific conditions .
The basic syntax is as follows .

Select the name of the column or the name of the columns from the name of the table where and then pass the the condition .
Next , select it specifies the columns you want to retrieve from the table from , indicates the name of the table that you're querying .
Where introduces the condition that filter the rows .
The condition , the condition is evaluated for each row in the table and only the rows that met the condition will be included in the result set .
So it's very important to have this in mind .
And now you may be wondering what is a condition ?
A condition is a logical expression that have rise to true or false in a slide for each row in the table .
The work clause uses those conditions to determine which rows to include in the result set .

Common operators using conditions include equal to not equal to greater than , less than greater than or equal to less than or equal to between a range of values inclusive .
And we have like for pattern matching in for uh which matches any value in a list , you have a small end or or not , or geological operators .
And we're gonna look at all of those in the next uh in the next minute .
Next , let's look at each operator step by step .
So let's start with the equal to operator .
The equal two operator checks whether two values are exactly equal .
It is used to filter rows where the specified column is equal to a given value .
Example , we have select from employees where department equals sales .
This query will retrieve all employees for the from the employees tables whose department is sales .
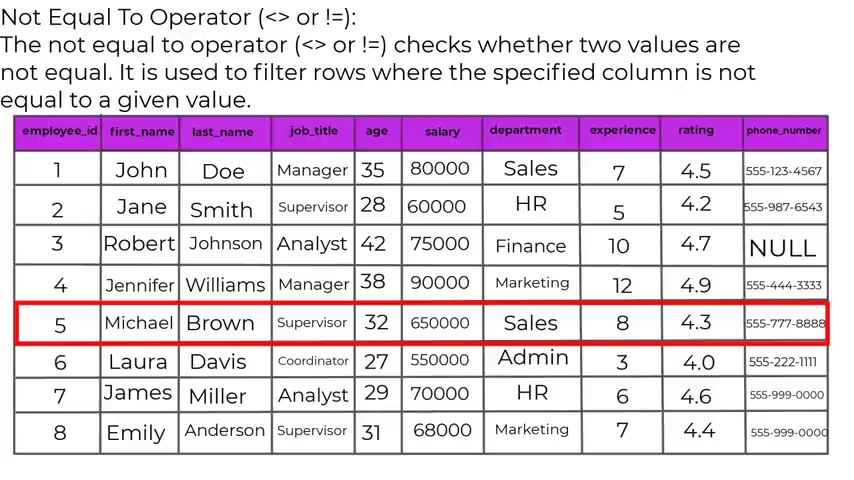
Next , we have the not equal to operator and the not equal to operator checks whether two values are not equal .
It is used to fill the rows where the specified column is not equal to a given value .
Example , we have select from employees where department is not equal to finance .
This query will retrieve all employees from their employees table whose department is not finance .
Next we have the greater then operator , the greater then operator checks .
If the left hand side value is greater than the right hand side value , it is used to filter rows where the specified column is greater than a given value .
Example .
And we have select from the employees where age is greater than 30 .
This query will retrieve all employees from the employees tables whose age is greater than 30 .
Next , we have less than operator .
And the less than operator checks to see if the left hand side value is less than the right hand side value .
It is used to filter rows where the specified column is less than a given value .
Example , we have select from employees where salary is less than 5000 , 500,000 .
This could retrieve all employees from the employees table whose salary is less than five 50,000 .
So , oh next we have greater than or equal to operator and the greater than or equal to operator checks to see if the left hand side value is greater than or equal to the right hand side value .
It is used to filter rows where the specified column is greater than or equal to a given value .
So it have example , select from employees where experience is greater than five .
This group will retrieve all of the employees from the employees tables whose experience is greater or equal to five years less than or equal to operator .
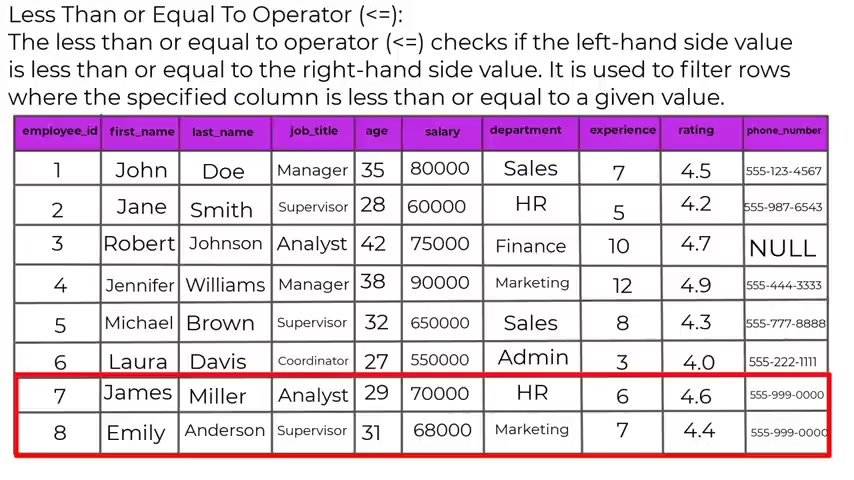
The less than or equal to operator checks to see if the left hand side value is less than or equal to the right hand side value .
It is used to filter rows where the specified column is less than or equal to a given value .
Example , we have select from employees where rating is less than or equal to 4.5 .
This query will retrieve all employees from the employee's table whose rating is less than or equal to 4.5 .
The between operator , the between operator checks .
If a value lies within a specified range inclusive , it is used to filter rules where the specified column value is within a range example , we have select from employees where age between 2040 .
This query will retrieve all employees from the employees table whose age is between 2040 inclusive .
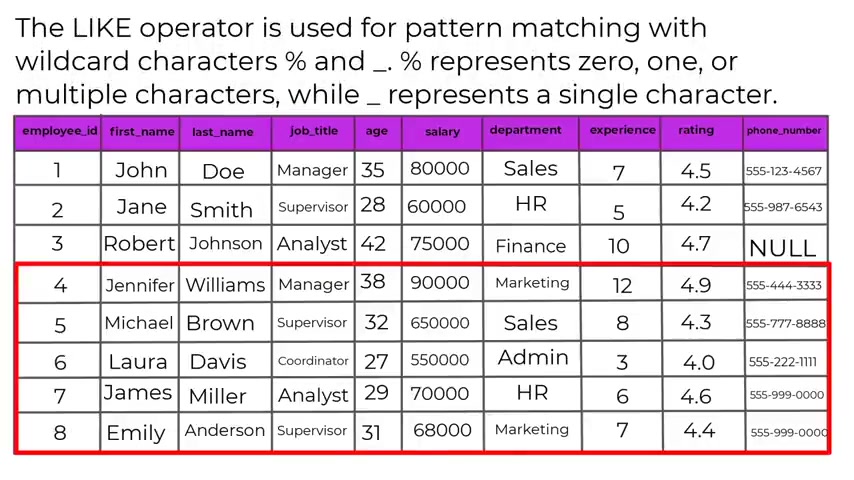
And this is very important inclusive like operator , the like operator is used for pattern matching with wild card characters like per and sign or underscore where per certain sign represents 01 or multiple characters .
While underscore represents a single character example , we have select from .
So select asterisks from employees were first name like and you put in a single quotation mark J and uh per person and sign this query will retrieve all employees from the employees table whose first name starts with the letter J , the in operator , the in operator checks .
If a value matches any value in a list of a specified values , it is used to filter rows where the specified columns value is one of the given values .
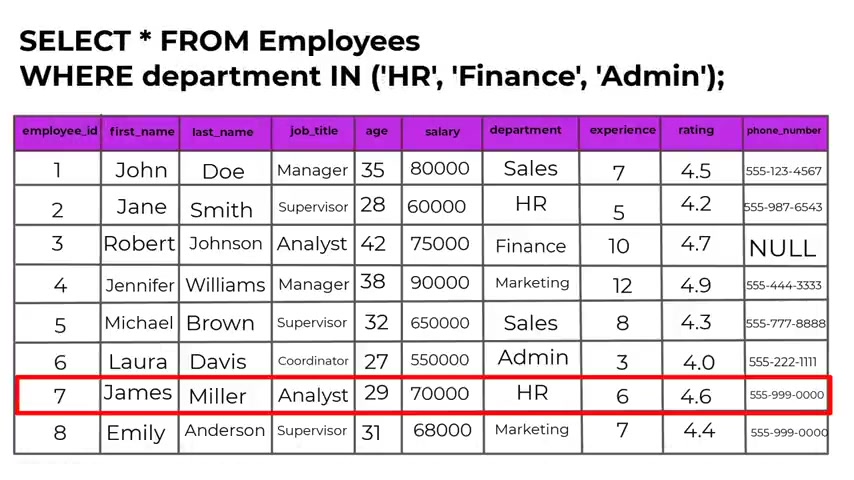
So we have for example , select asterisks from employees where department in human resource finance or admin .
And this query will retrieve all employees from the employees tables whose partner is either human resource finance or admin .
Next , we have the is NAL operator and the is a operator operator checks if a value is N no value , uh It is used to filter rows where the specified column value is null .
Example , select asterisks from employees where phone number is null .
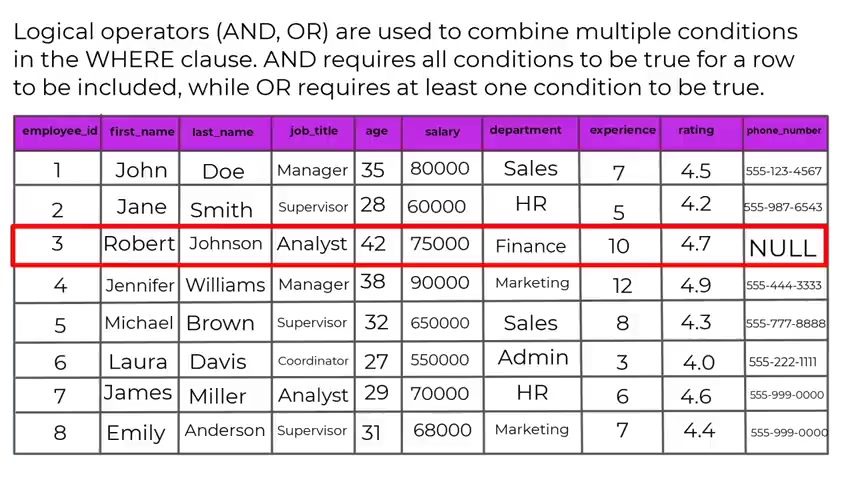
This query will retrieve all employees from the employees tables who have not provided a phone number where , where , where the phone number is not logical and , and the logical or operator , the logical logical operators and , and or are used to combine multiple conditions in the word clause and requires all conditions to be true for a role to be included while or requires at least one condition to be true .
Exa M we have select a ST for employees where department equals human resource and age is greater than 30 .
This query will retrieve all employees from the employees table whose department is human resource and the age is 30 or older .
So next we have select from employees where department equals finance or department equals marketing .
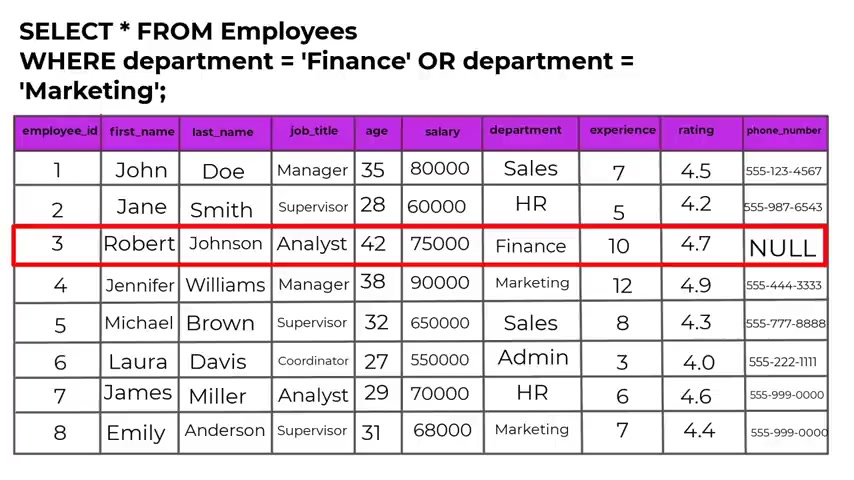
This query will retrieve all employees for the employees table whose department is either finance or marketing .
So these are all the operators that we can use in uh SQL .
I'm gonna end this video here and see you on the next video .
All right .
So now let's open PG admin and let's quote some examples using the select wire statement .
So let's open a PG admin .
I'm gonna run it as an administrator .
Now PJ is gonna start , we wait a little bit until it starting .
Alright , so P started , let's increase this window .
Let's go to servers .
We have positive sequel , we have our DVD rental and uh let's right click .
Let's go to war .
Could you all ?
And uh we have the customer table here .
And let's say that I want to get uh all the data from the customer .
So let's get all the data from the customer table from customer .
Send me call on now for and as you can see , have customer id , store , id , first name , last name me email have address , id and active bull .
And if uh the user is active or not uh created the last update and active and have one and zeros if it's not active .
Now , let's say that I want to filter the results .
What I can do is I can remove the semi colon .
I can , I can type here select from customer where first name , let's say that I want to get from the store , the person with the first name called Mary , you're gonna put equals single quotation marks , gonna type Mary .
So now if I uh and you can put this on the national if you want , so we can , I can type it like this I found .
So let me push it back .
Now , let's run it .
Let's we can put semi colon here .
If you want , it will still work without semi colon .
And we have , as you can see the first name uh Mary and the last name is Smith and I have the email ID active Bullen and so on .
So let's now explore the field table to , to , to show you how uh what , what else we can do with this word statements because we're gonna look also a t the logical uh we're gonna to look a T how we can bin combine condition with the logical and the war operator .
So let's just get change , you select from film .
So let's uh let's , you can increase this .
Let's see , the columns of the film .
Let's run it and you have title description , you have release your language , your rental duration , rental uh rate .
Let's say that I want to get from this film where , so where rental or a so rental rate is greater than four semi colon .
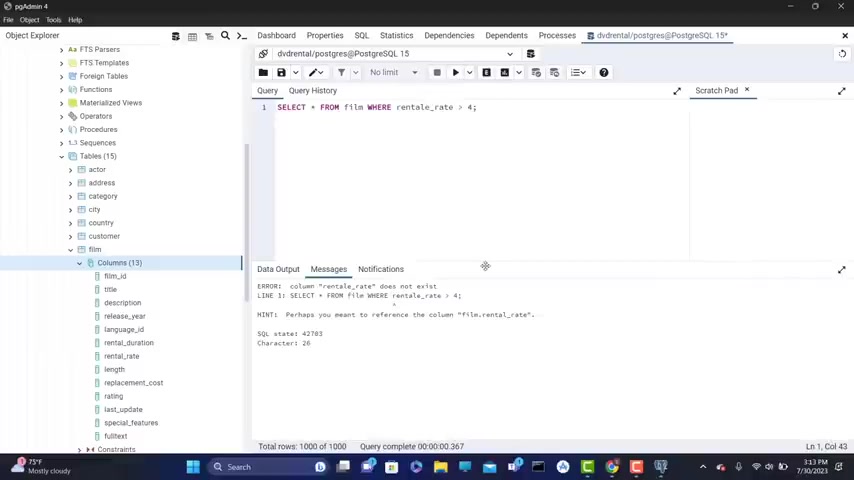
Hi front .
Oh , it should be a rental .
Let's write again and now I'm gonna get all the films , what the rental rate is greater than for us .
You can see here we have 4 99 4 99 4 99 .
Now , if I want to add more conditions here , I can use the logical end operators .
I can type where rental rate is greater than four and I can type a replacement .
Let's say that let's say that I want to filter to see what to see the ones which have a higher price for the replacement for the replacement cost .
So I'm gonna type replacement cost cast .
Make sure that you type that correctly is greater than equal to 90 99 semi colon .
If you want , let's run this .
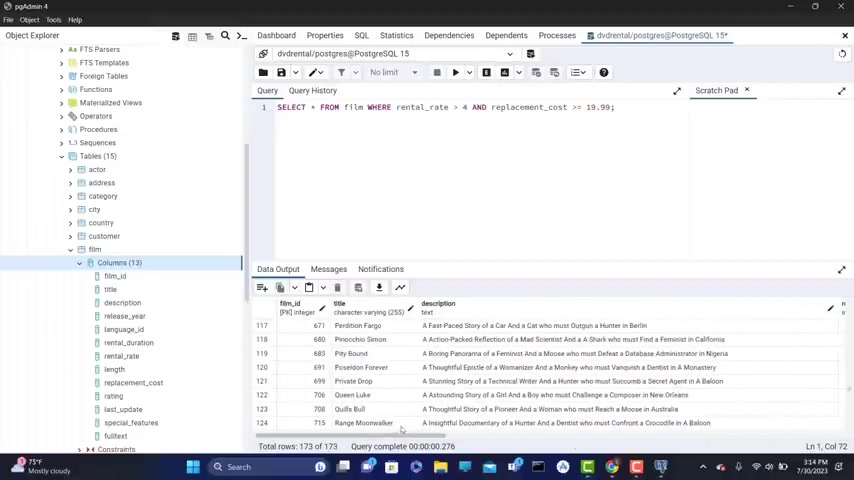
And if you got on the right here , you're gonna see that we have all the replacement cost bigger than 1999 .
So uh everything works fine .
This is how it's filtering our results .
Now , I can chain another condition here using the end operator .
And I don't need to type this word again because it will be applied to all the condition which I stick them together with the end operator .
So I can type I can type on the next line .
And another end , let's say that I want to get uh from film where the rental rate is greater than for the replacement con is greater than 8 , 1999 .
And let's say that I want to get all the movies which have the rating air .
So I'm gonna type rating R single quotation marks , single quotation marks are same color .
Now let's run this but first let me show you that .
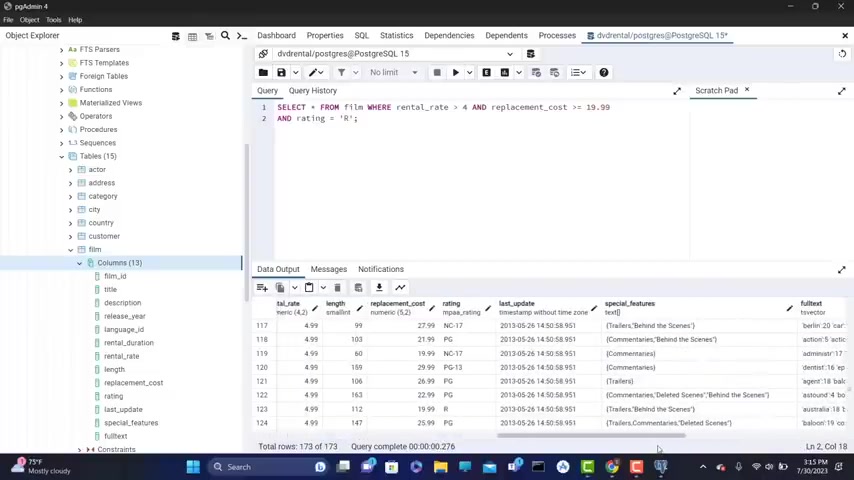
Uh now we have uh those which also don't have R because we don't have that condition .
Let me see what it is .
Alright .
So I was gonna see you have NNC 17 .
Uh you have PG , you have PG 13 .
But now if I run this , if I go on the ride , now we gonna have o only the movies which have the R rating as you can see here .
So only those movies a re returned back .
So this condition , this entire where is gonna return all the results for which this condition that we define , those conditions that a re defined here .
A re true for all .
So for , for uh for all of them .
All right .
So this is uh what we can do .
Now , let's say that uh I want to get , so let's say that I want to count how many movies are with the rating .
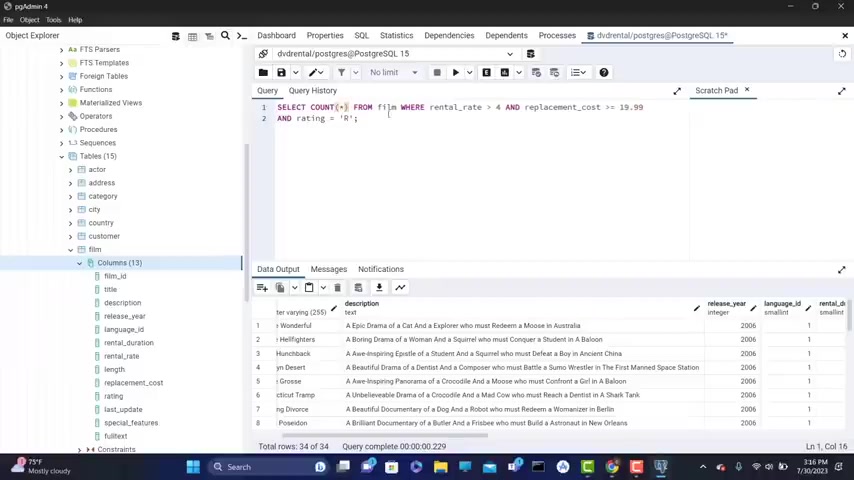
Uh are , so how many movies are , let's say with , with uh uh which match this particular condition ?
So I want to get all the movies .
So all the films for which this condition is true .
So I want to see how many there are .
So let's go around this and we get 34 .
So there are 34 movies which are , which are rating as r have the rent the greater than four and the replacement goes greater than 1999 .
And also we had uh again , I repeated mys , I repeat myself here rating I where the rating is , er , and you can also put here if you want um title , it will still work because it will return the four rows .
Alright .
So this is how you can use uh the C .
Now let's see how we can use uh the logical or operator .
So let's say that I want to just select , let's say uh uh let's type here title from feel where let me actually type select from film again because I want to see the columns from , so select from field because I want to see all the columns , let's run it and let's say that I want to get the ones which have the rating R MP G or the rating PG 13 .
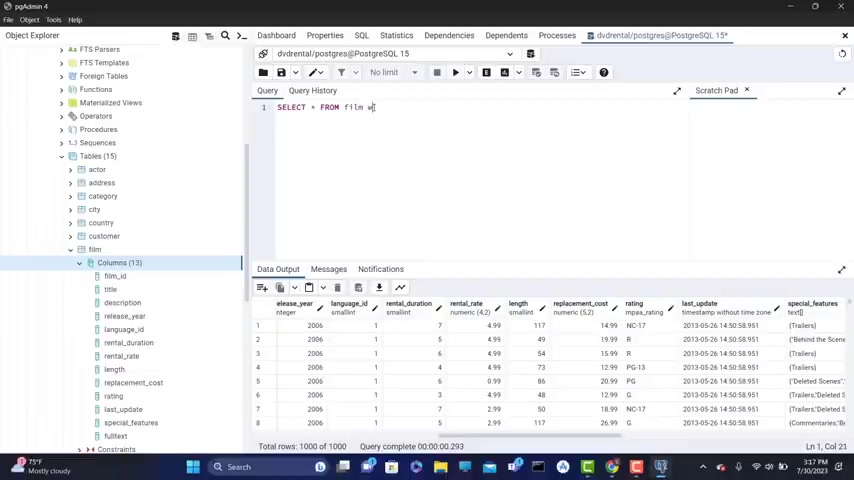
So I can type here where , where rating equals to R and it , or operator or rating , he could still PG dash 13 .
So let's run this and notice that I don't add the semicolon .
It still works if you don't want the semicolon .
And now we have all the movies which have the rating , either R or uh PG 13 And you can also use count here , count all the columns , I'm gonna put count because you know , you , you know this from the previous videos to see how many movies a re we have the rating R and or PG 13 .
So if you on this , we get 418 .

All right .
So these are discussions for the video and see you in the live video , Nelson do a challenge using the select word statement .
And in this video , like in the previous videos , we're gonna have the SA me structure .
So we're gonna have for the business situation , the expected result , the hints and finally we're gonna have uh the solution .
So let's start with our first challenge .
So channel number one , let's say that you're running a DVD rental store and want to find the titles of films which are released in or after the year 2000 that have a rating of PG 13 .
And you also need to know the replacement cost of those films .
So le let's see the expected results .
So this is what you will you see in the expected result , retrieve all the ties and replacement cost of films that were released in or after the year 2000 and have a rating of PG 13 .
So this is what you should see after running that uh particular query .

Now let's look at hints .
You need to filter the films based on their release year and rating and the rating columns , the rating column stores , the film's rating , the release year column store , the year a film was released .
So those a re the hints .
And now let me show you the solution .
The solution is to type select title replacement cost from film were released here is greater than equal 2000 .
And so the end operator rating equals to PG 13 .
So this is the solution .
Now let's move to channel number two .
Let's say that you want to see the titles of films which have a rating of PG and the replacement cost of $10.99 .
So let's see the expected result .

So the expected result is gonna tri the title of that have a rating of PG and the replacement cost of 10 I repeat and the replacement cost of 10 99 .
So this is gonna be the the expected result .
This also should , should see in uh the output .
All right .
Now let me show you the solution , not the solution .
Let me uh give you the hints you need to filter films based on the rating and replacement cost .
First , the rating column store the films rating and the replacement cost column represent the cost to replace the film .
So these a re the hints to solve this uh challenge .
Now the solution , the solution is to select title from film where rating is PG and replacement cost equals 10 99 .
And that is gonna solve our challenge .

Now let's move at challenge number three , challenge three is you want to find the titles of released either before the year 2000 or with a replacement cost less than 10 .
So you either the or uh now let's look a t the expected result and the expected result is gonna retrieve the title of that released before the year 2000 or have a replacement cost less than $10 .
So this is what we're gonna see in the output .
Now let's see the solution .
Uh So let's see the hints .
So you need to filter films based on their release year and replacement cost .
The release year column stores , the years , the year of film was released and the replacement cost column represents the cost of a to replace a film .
So those are the hands .
Now , let's see the solution .

The solution is to select title from film where release year is less than 2000 or replacement cost is less than 10 .
So I'm gonna end this video here and see you the next video .
Welcome back .
Now it's time to start a discussion about the count function .
But first , let's go through each aspect of the count function .
And SQL step by step using some simple tables to grasp the information better .
So the count function is equal .
The count function in SQL is an aggregate function that allows you to count the number of rows that match a specified condition within a table or a result set .
It tells a single value representing the count of rows that meet the criteria .
So this is what the count function is .
Why is count function useful .
The count function is valuable for various data analysis tasks .

It helps you to obtain statistical information about your data such as counting the number of records in a table , calculating the occurrence of a specific values in a column , finding the number of rows that met certain conditions , determining the number of unique values in a column when used with the distinct statement .
So this is why count uh function is useful for these reasons .
When to use the count function , you should use the count function when you need to determine the size of a table , the number of of rows , it contains count occurrences of specific values in a column , get the summary statistic statistic about your data .
So this is where you should use the count function how to use the count function with the distinct statement .
This distinct keyword is used to eliminate applicate draws from the result set .

When combined with count function , it allows you to count the number of unique values in a specific column .
Here is how we can use it .
Let's consider a simple table called employees .
As you can see here , you have this table , you have the employee ID , the employee name , the department .
And uh and as you can see in this table , we have five rows and you have uh multiple departments but you have duplicated departments .
Uh As you can see here , we have the human resources twice and the it will also you have it twice .
Now , let's say that uh I want to count the number of uh employees in the table .
If I do that , the count is gonna return five and it's gonna return to five because if you have , if you have 55 rows .
S so this is what uh that will return .

Now , example , two , let's count the number of unique departments in the employee table using distinct keyword .
So we're gonna type select count parenthesis , distinct department from employees .
And when you're gonna do that , the , the result is gonna be one because we have human resource two for finance and three for it .
So we have three unique departments in our department uh uh table uh on our depart department uh row .
So this is how we can use that .
And um let's wait in this example , we use the count function with a distinct statement to count the unique departments in the employee table .
It returned the count as three because there are three unique departments , human resources , it and finance .
I hope that this example helps to illustrate the usage of uh the usage and usefulness of the count function .
And SQL particularly when combined with distinct statement , it allows you to perform various data analysis tasks and retrieve valuable information from your database .
Alright .
Now let's move to post gray sequel to to type some uh so called .
But before you open PG admin , let me first explain what is the difference between count with asterisks and count without aster .
So count with the column .

NA me and in SQL , the usage of count function with and without aster depends on what you want to count .
Let's explore the differences and when to use this form , count with parentheses and asterisks .
When you use count with parentheses and asterisks , it counts all the rows in the specified table regardless of the values in the columns .
Here is the syntax we have selected count parenthesis , asterisk from and the table name .
Now let's see the usage use count with parenthesis and asters when you want to count the total number of rows in a table .
Irrespective of whether there are null values or not , it counts all rows including those with null values in any column .
So this is what counter acetic does .
Uh Let's consider an example , let's say that we have uh uh a table for the tables called students and we have the student that is to na me and age .
And as you can see for uh the student na me , we have here a null value .
So you do , you do it didn't provide uh a na me now that it is not , that is uh because by using count with asters , it will count even if you count .
I say that you want to count uh the total uh numbers , the total number of uh of uh student NA mes , it will count also the , the N one if you use count with asterisk count with out asterisks .

So when to use count with the column name , so you specify a column name inside them inside the parenthesis of the count and it counts the number of non knu values in that particular column .
Here is the syntax .
So this is different .
This , this , this only counts the number of nonn values usage .
You use count with column name .
When you want to count the occurrence of non null values in a specific column .
It ignores null values in the column and only counts non null entries example and continuing with the students table .
Let me show you , let's wait a little bit .
If you type select count , let , let's make this .
So let me change something here .
If you type , select , count the student na Me in parenthesis from students the count is gonna return four because the count uh without asterisks is returning all the non null values .
So because the student na me five with the idea five is null , is not gonna count , it's gonna return four .
So this is what uh count with the column , uh column name .
Uh uh He's doing alright .
Let's move to the next .
Now in this query count , student name only counts the annual values in the student name column excluding the row with N name .
Hence it returns the count of four .
When to use each form , use count without asterisks .

When you want to count all rows with , with asterisks , sorry , including those with no values or , or when you want or when you don't have a specific column to count , but you still need to retrieve the total number of rows in the table .
Use count column name when you want to count the occurrences of non null values in a particular column , ignoring null entries .
This is useful when you want to analyze the distribution of frequency of non values in a specific attribute .
I summary that the decision to use the count without or with or without assay depends on whatever you want to count all rows including nulls or you want to count only the occurrences of non null values in a specific column .
And you can choose the appropriate form based on your uh an analysis needs .

All right , let's move to the next slide in summary count with asterisks , counts all rows in the table including rows with null values in any column and count with column name counts .
The number of non null values in the specified column , ignoring rows with N null values in that column , choose the appropriate form of the count function based on your specific requirements .
If you want to count all the rows in the table , regardless of the null values , use count with asterisk .
If you want to count the number of non no values in a specified column , use count with the column name .
All right .
Now let's open PG admin .
All right , let's open PJ admin .
Now let's run it as an administrator .
Let's open the server .
Let's open the curator in all time here .
Let's say that I want to get all the data from the payment table .
I will type , select from payment semi colon .
Let's round this right now .
Let's say that I want to know the number of uh rows in this table .
What I can do is I can type here , select count asterisks .
I'm gonna put parenthesis , asterisks .
So parenthesis again , asterisks from payment and that is gonna return the number of rows , basically go on the run and we have 40,596 .
Now you can do another way you can type here a mount , the name of uh of a table .
Do not the na me of the , the , the , the na me of , uh , let me open this , of a column and that will go , we're gonna return the sa me result .
As you can see here , everything works fine .
Now , next , let's say that I want to retrieve the actual number of the unique amounts .
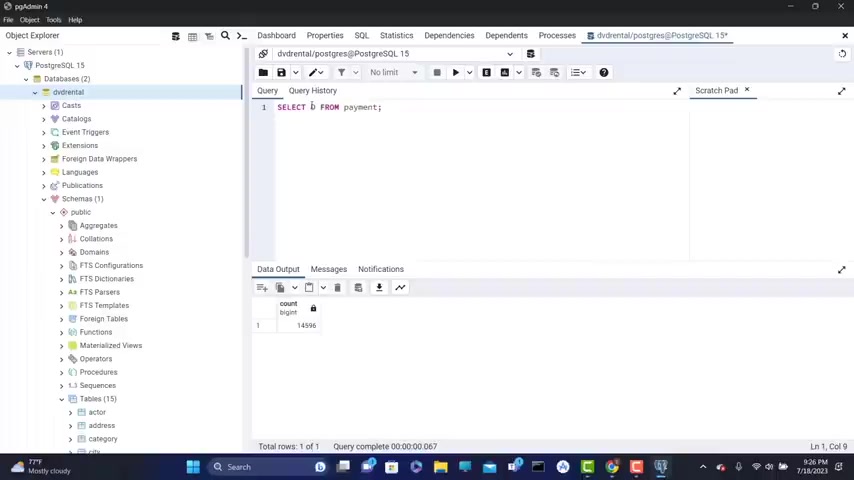
So I'm gonna type here select distinct A mount from payment .
So if you run this , we get our distinct A mounts .
Now , let's say that I want to get the number of th of those distinct A mounts .
How , how I I'm gonna do that .
This part is gonna return the number of distinct A mounts .
So we need to put here before count .
So not that here count parenthesis .
We put our distinct inside the parenthesis , distinct A mount because that is gonna return the distinct A mount of uh uh payments .
And uh n now if this , you get 19 and you can also put also this in parenthesis to make it more clear another parenthesis here .
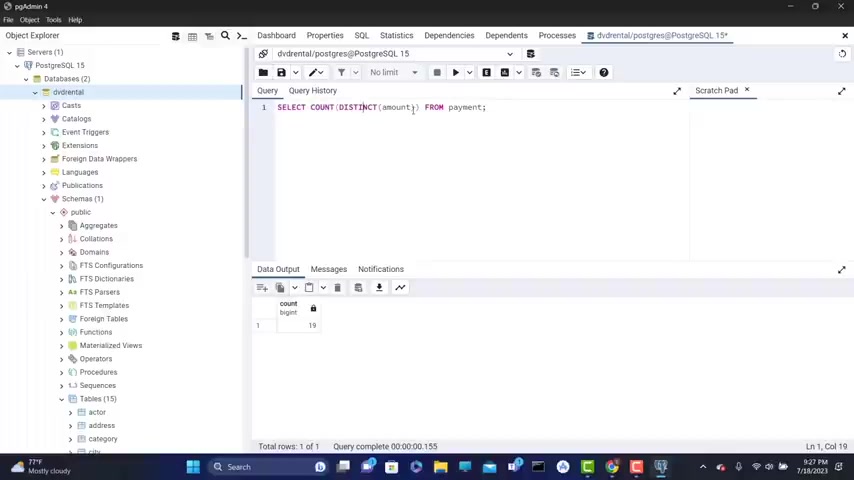
Now Fran this get also 19 .
So this returns the number of unique amounts in our uh payment and the count is count is counting them .
So I'm gonna end this video here and see in the next video .
Now it's time to start a discussion about the order by clause .
So the order by clause impose graph sequel is used to sort the result set of a query in a specified order .
It is used when you want the query output to be presented in a particular sequence based on one or more columns values .
This can be crucial for making query results more meaningful and easier to interpret .
Now , why do we need to use the order ?
By first we have data presentation .
So when displaying query results to us that it is often important to have data presented in a logical and readable order .
For example , if you're displaying a list of products , you might want to show them in a sending or descending order of price .

Second , we have analysis in cases where you're performing data analysis sort , the results can help you identify trends , outliers or patterns more easily .
For instance , when analyzing sales data sorting by the date , he help identify sales patterns over time .
Next , we have pagination .
So pagination is when dealing with large data sets , you might want to implement pagination to show only a subset of data on each page .
Proper sorting is essential to ensure data consistency between pages .
So uh this is now usage of order by the sins of the order by close .
This house is far , we have select , we have the column or the columns from where can put a condition if you want .
And we type order by and we sort by a , a column and we define the order being a sending or descending and can uh also use an two columns if you want .
So this is uh the syntax of the order by .

Now , here is what each component does .
So select specify the columns you want to retrieve from the table from species , the table from which you're retrieving data where is option , it's an optional condition to fill all the rows before sorting order by specify the columns by us .
The resources should be sorted .
You can sort by one or more columns .
And for each column , you can specify as sending which is the default or descending order .
So now let's look at an example in pr PG admin .
Now let's work with some examples in Pr and for this purpose , I'm gonna use the customer table .
I'm gonna select everything from the customer table .
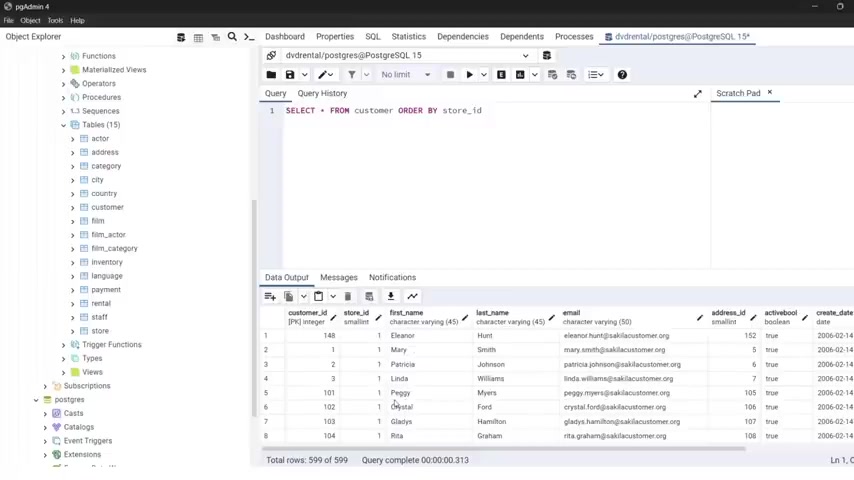
So I'm gonna type select from customer and the option of the semicolon .
Let's run this and you see , you see in the data output , we have the customer ID , id , first name , last name , email address and active bull and created .
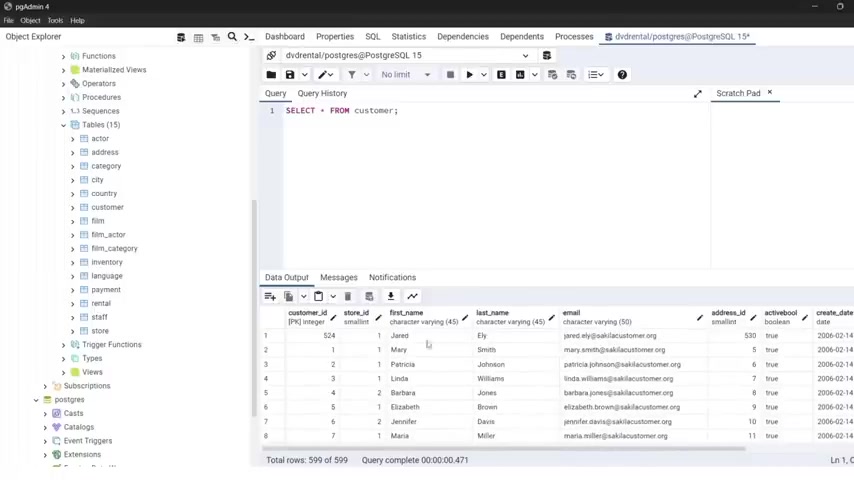
So , but now the data is not being the entries a re not being uh displayed in any particular order .
Let's say that I want to display all the customers uh inin this table and I want to order them by their first na me in order to do that , I go a t the end of our statement or on the next line if you want .
But I'm gonna go here , I'm gonna type order by and now I'm gonna specify the column when you gonna w with which you're gonna s uh perform the order when I first underscore NA me and the optional semi column , let's put seal on .
Now let's run this .
And now you can see they a re uh sorted ascending by their first Na Me .
As you can see how A and we have N now we have the NA Me .
So starting with the B and so on and we have this uh store ID .
Keep in mind uh this story ID because we're gonna use this with uh another Exa Mples .
But now let me show you that here , you can type as sending order .
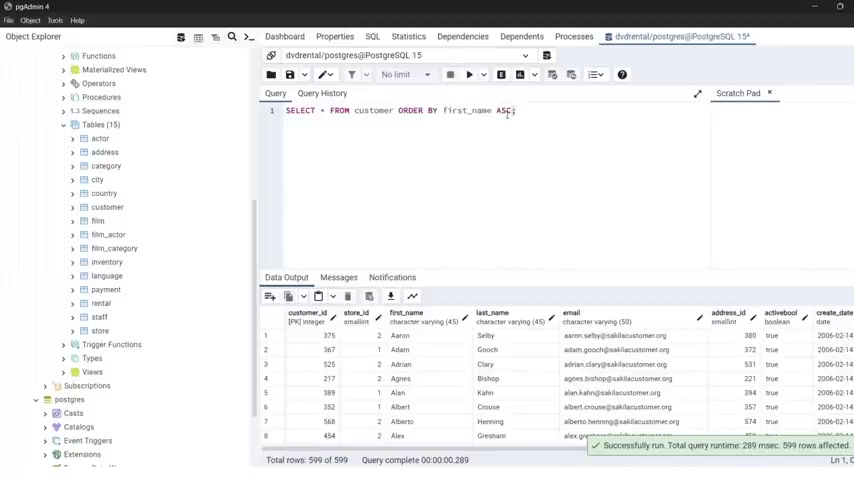
But uh as I , as I said , this is by default uh the order used if you don't specify in any order .
Um Now you may be wondering why you should uh type this .
If this is by default , use this uh can be helpful if say someone who else comes to look A T your code and you'll , you'll see that uh you want specifically in uh uh your order to be in ascending order and you can specify descending order .
So it a here descending the .
Now , if you run this , as you can see now , starting from Z and have WVT and so on .
So you can uh do this if you want .
Now , let's , let's say that I want to have uh to have our uh our uh customer being stored , being the being sorted by the store ID .
What I can , I can I order by store ID so store right there and the semi colon if you want or you can delete that because to still work , let's run it .
So now they are ordered by the store ID .
But as you can see , we have , uh , you , you have , uh , so on and if you s keeps rolling , eventually we get to store ID two .
So we have here , we have store ID two .
As you can see .
Now , starting now they a ren now they a re sorted by the S uh , so the store ID .
But , uh , the problem now is they a re not sorted within the store ID .
No , not within the store within the , the store because as you can see , you have uh , multiple , uh , uh , customers belonging to , to the same store .
So I can , I can do here .
I can type order by store ID and also order by first underscore name semi colon if you want .
So let's run this .
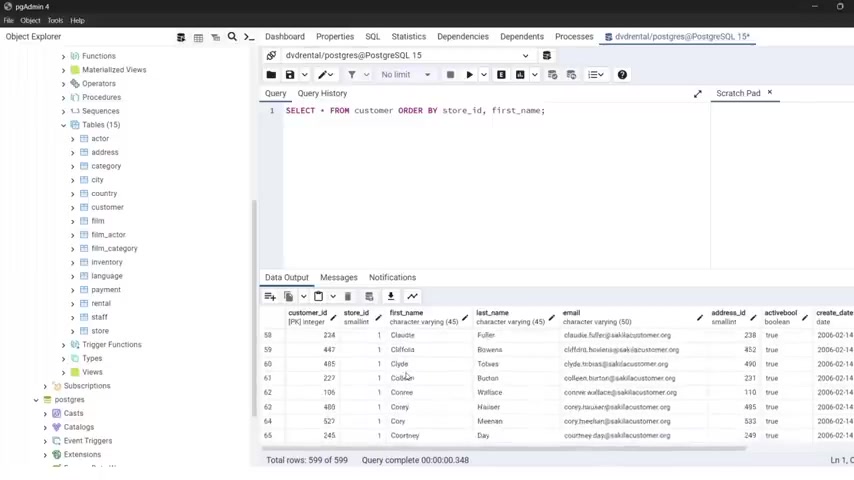
Now we have one and , uh , now they a re uh , also sorted within the store .
So they a re ST sorted for by the store ID and then by the first na me , as you can see here , we have one and we have , uh A and then b so everything works fine .
Let's keep scrolling and we're gonna see the number two being , uh , shown as you can see here now , so everything works fine .
Now , let's see that I want to get in our select uh statement , only the store ID .
So only the store , the first name in the last name , right ?
So let's run this .
Let's put this on the next line .
Let's push it uh only this .
Alright , let's run it now , in case we have the store id , first name and last name .
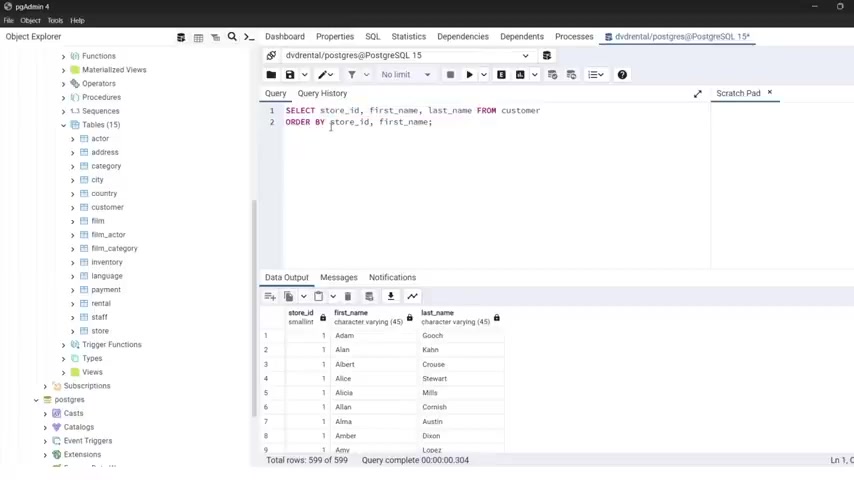
So now we're getting the those columns that we specify in the select statement and we get the data , we order it by the store id and then by the first na me .
And you can specify here ascending and here , let's say descending if you want .
So let's type with uppercase letters , let's run it .
And now they a re sorted as you can see here first ascending .
So the idea is ascending .
So we have one , then two as you can see here , let's scroll , we have two .
Now if I go back as you can see , you have uh the first na me sorted , so sorted uh and they sorted descending , started from this .
So let's also type here also ascending .
So let's run it .
So now we have one a and so on .
So now everything is uh is fine .
11 more thing that we can do is that if you don't specify in our select statement uh column , let's say , but I start using that column , it will still work .

So if you run this as you can see the store ID is not present in the select statement , but it's uh it's present here in the water , buy and it's ordered by the store ID and everything works fine .
All right .
This is our discussion about the order by and see you in the next video .
Welcome back .
Now .
It's time to start a discussion about the limit command impose GRA SQL .
So what is the limit command ?
Impose SQL ?
The limit command impose GRA SQL is used to restrict the number of rows returned by a query .
It allows you to specify a maximum number of rows to be included in the result set .
This can be particularly useful and we have a large data set and only need to retrieve a subset of the data for analysis for display purposes .
So this is what the limit command does .
Now here is how the limit command works .
You have to select uh keyword specify the column , column , one , column two from the table name and we have limit and the number of rows .
So we specify the number of rows that you want to have return .

So in this uh SQL query , we have the column on column two .
This the column you want to retrieve the data from next , you have the table name , the name of the table you want to query and the number of rows and the maximum number of rows you want to retrieve .
For example , if you have a table name employees and you want to retrieve the 1st 10 employee , you will use the following query .
So if I select first name , last name from employees limit 10 , so this is gonna retrieve only the 1st 10 entries from the table .
Now , the limit command is important for several reasons .
First , we have performance optimization when dealing with large data sets , fetching all rows can consume significant resources and slow down your database .
Using limit allows you to fetch only the necessary amount of data improving query performance .
Second , we have pagination and web application .
You often need to display data in chunks such as in pages .
By combining limit with offset crows , you can implement pagination easily .

The offset specifies where to start fetching rows from resources .
Next we have resources management .
So three by limiting the number of rows returned , you can reduce the memory and network resources required to process and transmit the query results .
So these a re the three .
Now what is pagination ?
I also showed you in the last video I think uh I I uh spoke about pagination but I didn't say what is .
So pagination pagination is a technique using web application and databases to display and navigate through large sets of data in small or manageable chunks of pages .
It involves breaking down a large data set into smaller smaller subsets typically with a fixed number of items per page to improve user experience and performance .
When you encounter a web page with a list of items such as search result , blog posts or products , you often see links or buttons at the bottom to navigate between the pages of the list .
This navigation is a form of pagination .

Each page typically displays the subset of the total data , make it easier for users to browse browse to their content without being over real .
So pagination basically means to fetch only a limited amount of data and this can be useful .
Let's say that we have a list and you want to display some data on that list , you will display uh let's say uh uh specific item of a specific number of items in that list .
And when the user reaches the bottom , you'll request to face some more data and when to reach again , the bottom , you'll uh bottom , you'll uh uh request to , to find some more data and so on .
So this in this way , you don't uh fetch the whole data at once .
You , you get only the , you get only chunks of data when and we get the , the data when the users reaches the bottom of the list .
So this is what pagination basically is .
It's a very powerful uh uh thing very , which is very used in programming .
All right .
Next .
Now let's select everything from the payment table .
So I'm gonna type , select everything from payment semi colon .
Let's run it .
All right .
And we have the payment ID , the customer ID stuff ID , rental amount and payment date .
Now let's say that I want to get everything from payment but ordered by the payment date .
So I can here select everything from payment order by and I can I your payment underscore date and here we can specify ascending or descending .
Let's uh let the ascending .
Let's click on a run .
And now I was going to have everything uh ordered by the most recent uh uh payment date .
BB by the payment date .
Now , I can write this this ending if I want .
So I can de this res descending if I want .
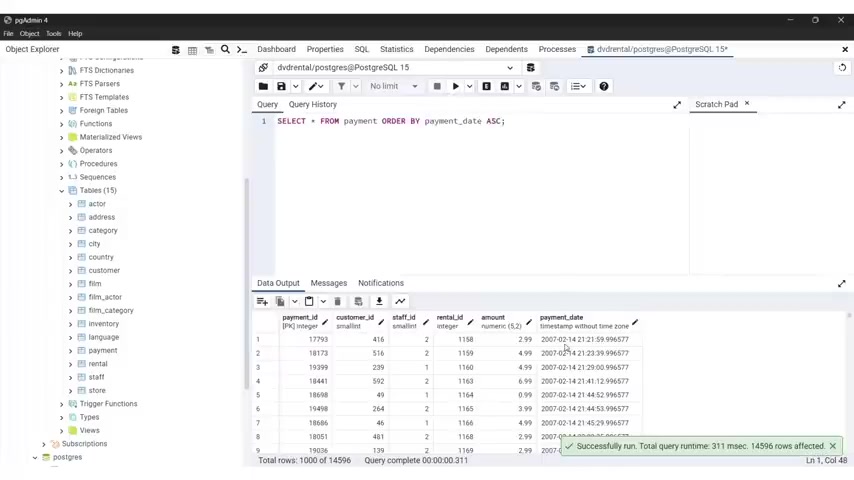
So now if you run this now , because we have the 5 14 and previously , let me go back to standing lowercase letters , let's run now we have 2 14 .
So this is the month , month and this is the date .
Uh So uh this is what we can do .
Now , let's see how we can use the limit function .
Let's say that I want to retrieve only the last most , last 10 , most recent payments .
So uh in order to achieve that I need to go here and I can type here limit .
You can type this on the same line or on the next line limit and let's put them and you can put an option on the semi colon if you want .
Now , if you're on this now , as you can see , we have uh uh we have our data but we only have 10 entries now .
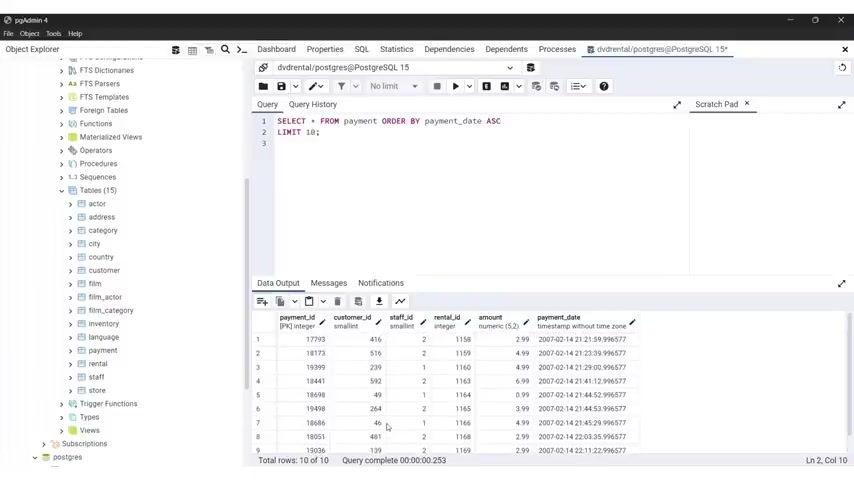
So we have only the most uh recent 10 payments based on the payment date .
Now , let's say that , uh , as you can see here , uh , let me check , uh , the amount run the payment amount here .
We have 09 .
let's , uh , check , let's put here another , uh , statement and , uh , I'm gonna go up here and before the words are by , I'm gonna type where amount it's not equal to zero .
So now if you on this , we get , uh , our data and now uh everything works fine , but now it will eliminate uh the ones which a re uh equal to zero .
Bbin .
Our case actually our uh 10 results , there wasn't one which ha which here was uh equal to zero .
Let's put the mount is not equal to 10 0 99 let's say .

So let's run it again and we have here 0 99 .
Let's run it .
And now if you look here , uh let me see the , the 0 99 is not present as you can see here .
All right , I'm gonna end this video here and see you on the next video .
Welcome back .
Now it's time to start a discussion about the command .
Impose GRA SQL .
So what is the command ?
The command I post GRA SQL is used to filter data within a specified range of values .
It is typically used in conjunction with the workloads to retrieve rows that fall within a specified range of values for a particular column .
So first we have here is a breakdown of its uses and significance .
First , we have the basic syntax of the between commanded as follows .
We have the select the column .
So I have the select statement , the column name of or names from table name where column name is and I will use the between command value one and value two .
Next we have to , we have usage .

So the routine command is particularly useful when you want to filter rows based on a range of values for a specified column .
For EXA MP , you might want to retrieve all orders made within a certain date range or find employees whose salaries fall within a certain bracket .
Inclusivity .
One important aspect of to note is that between command is inclusive , meaning it includes both the specified start and end values in the range .
For example , if you use between 10 and 20 it will include rows with values 10 and 20 everything in between .
So why use it ?
So why are you doing it to use the between command ?
The command provides a concise way to filter data within a range , eliminating the need to write separate conditions for each boundary .
It enhances the readability and maintainability of your SQL queries .
Next , you have performance when using the between command , make sure that the column you're applying .
It has an appropriate index .
Indexing .

The column can significantly significantly improve query performance as possible .
Sequel can quickly narrow down the rows within the specified range .
Example , the orders within a specified date range , we have select order id , order date from orders who are order that order of the score date between 2023 0101 and 2023 06 30 .
So next we have finding employees with salaries between a certain range .
We have select employees id , first name , last name , salary from employees word salary is between 400 and 600 .
In summary , the between command in SQL is a powerful tool for filtering data within a specified range .
Making your queries more concise and readable .
It is commonly used to retrieve rows that met certain criteria without having to write multiple separate conditions .
Now let's work on some exa mples in PG Aldin .
Therefore , I'm gonna use the payment table .
Sometimes I select everything from the payment table .
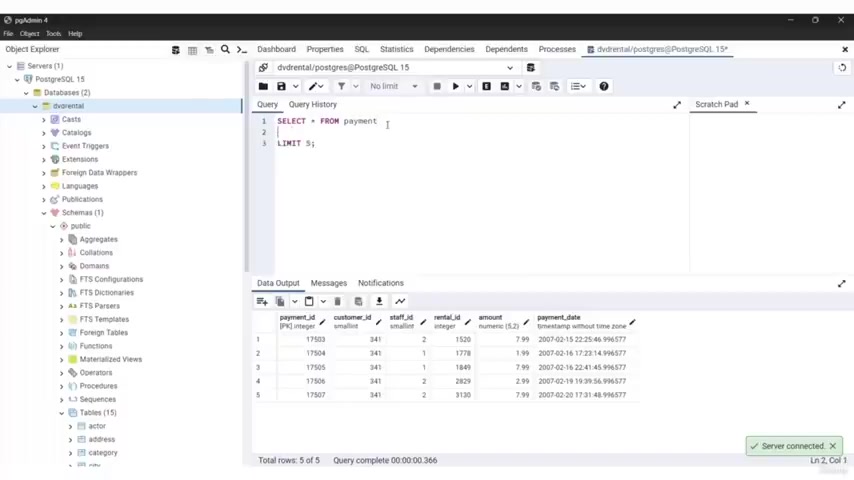
I'm gonna limit only five entries .
So let's run this and we have uh five entities .
We have payment ID , customer , ID , staff , id , rental , id amount and payment date .
And let's say that I want to select everything from payment where the amount is between eight and $9 .
So I'm gonna type betwee uh select from payment where amount you type between eight and nine semi colon .
The option of semi colon if you want , you can , can uh now let's on this as you can see .
Now we , we have all the payments that but the amount as you can see here is $8.99 .

So you have everything between eight and nine and if you want everything , which is not between eight and nine , you just put the nut keyboard here in front of N .
So now we put on this get 7 99 and if you want to see the , now we get 7 99 1 99 7 99 2 99 .
So we're selecting everything but not eight and nine .
So everything which is the uh not eight and nine .
Now let's uh let's uh let's see how many transaction we have transaction we have .
Let's tell it here count .
Let's select all the transactions to see how many transactions between with the , the amount where the bet between the amount is between eight and nine are .
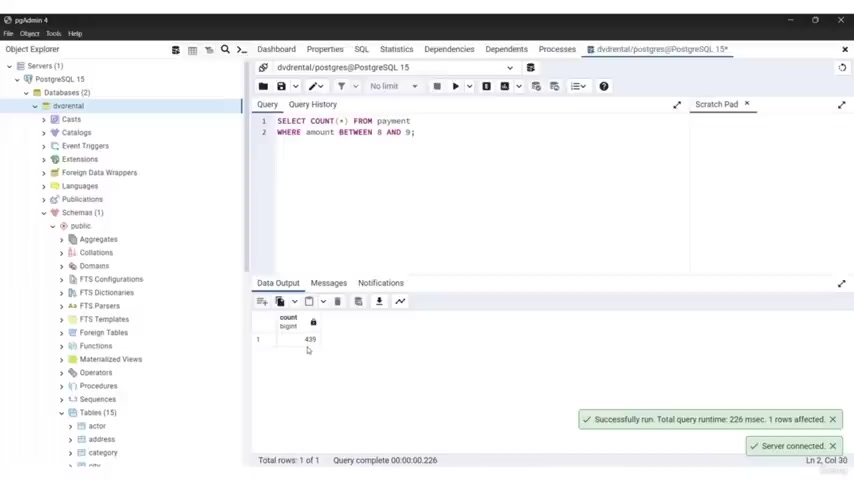
So we have 439 transactions and if you want to see which a re not with a , not do you want here upper case letters .
And we have , as you can see , we have a big number here .
14,150 f 57 .
Right ?
Let's say that I want to now to retrieve all the transactions from payment .
Let's put back here from payment , let's say uh let's run this to see how that table was called .
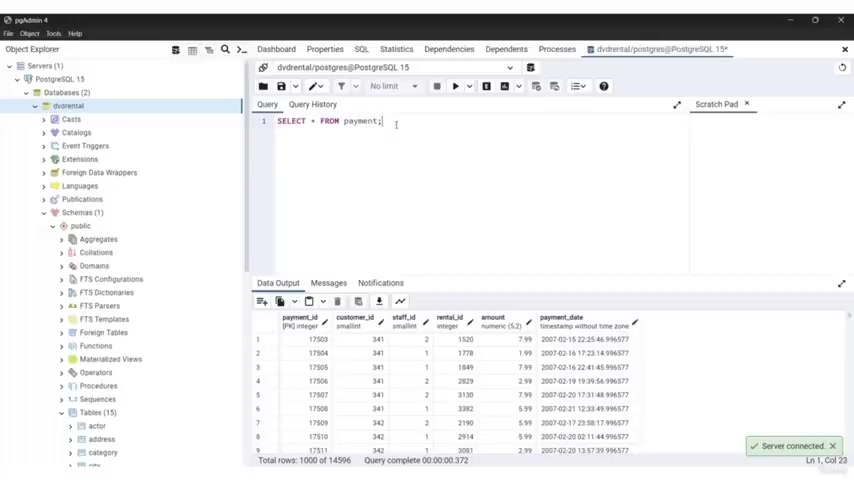
So payment date , what the payment date , let's see all the tran transactions in the first half of January in order to do that , I'm gonna go at the end of our statement and I'll tell here where and I'll type payment by a month date between and I put her single quotation marks 2007 .
Now demand dash 01 and the day 01 and , and single quotation marks 2007 dash 01 15 .
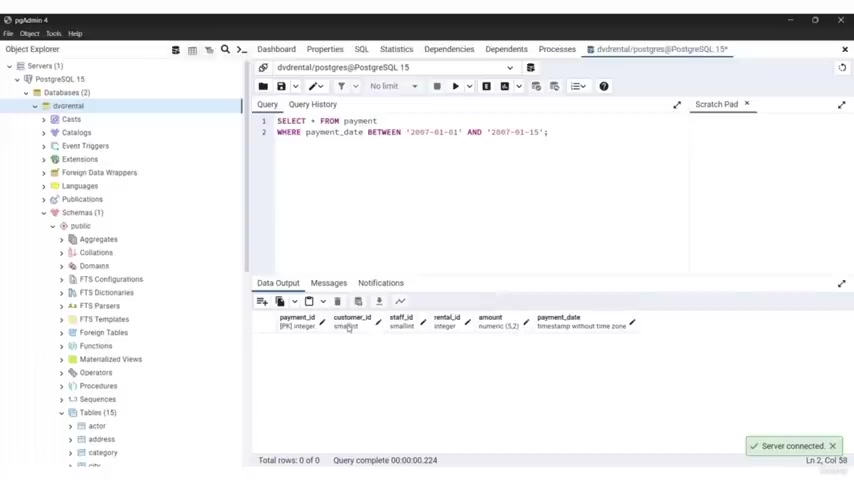
Let's run this and uh we get uh not many transactions .
So let me change this to , let's say first half of February .
So let's changes to 02 later on .
And as you can see , we have uh all the payments , but as you can see here , they are in the first half , you can have 2 , 2007 .
The amount is 02 and the the date is 14 as you can see here .
So now everything works fine previously , we didn't get anything because there is no transaction be uh the in January , but we have in February between uh day one and 15 .
All right , I'm gonna end this video here and see you in the next video .
Welcome back .
Now it's time to start a discussion about the in command in post sequel .
So what is the in command in post grade sequel ?

The in command in post SQL is used to filter data based on a specified list of values for a particular column .
It allows you to retrieve rows where a specified columns , value matches any of the value in the given list .
Here is a detailed explanation of the in command and its significance .
So first , you have the syntax , the basic syntax of the in command is as follows , we have the select the column name or names from the table name where column and we have the in command and we put parentheses value one value two and so on .
So this is the syntax of the in command .
Now , now two , we uh at the 0.2 we have usage , the command is particularly useful when you want to filter rows based on a list of values , it simplifies your query by allowing you to specify multi , multiple acceptable values in a compact manner .
This is especially handy when you have a long list of potential values to filter .
For .
Next we have three flexibility .

The command can be used with various data types including numeric value strings and even sub queries .
This flexibility makes it a versatile tool for querying data .
And the fourth we have why use it .
So there are few key reasons why you might want to use the in command but have reduced query complexity .
When dealing with multiple possible values for a column using Y can simplify your query comp compared compared to writing separate or conditions for each value .
Improve readability by using Y you make your SQL queries more concise and easier to read , especially when dealing with long list of values efficiency .
SQL SQL query optimizer can often optimize in queries more effectively than complex combinations of all conditions .
All right .
Next .
Now let's work on some examples in pr and therefore I'm gonna select everything from payment and I'm gonna type limit five , let's run this .
And as you can see , we have here uh five entries and we have payment , id , customer , id , stuff , ID , rental , id amount and payment date .
Now , let's say that I want to get the distinct amounts which are uh in this uh table in order to do that , I'm not a hero select distinct amount from payment .
Let's read the limit .
Let's write .
And now we have the distinct amounts which are in this uh table .
We have 1 99 10 99 and so on .
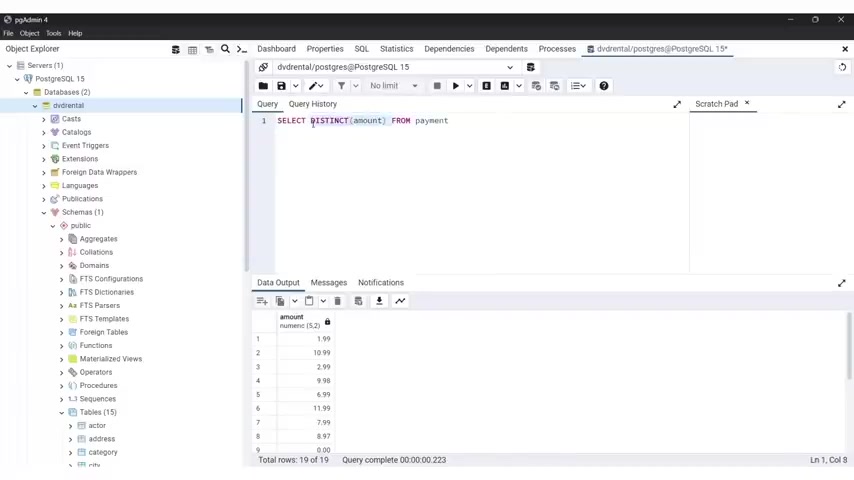
And uh now let's say that I want to get uh the amount only the amount , let's say uh select everything from payment .
So for us that is before and let's say that I want to get where amount parenthesis , uh what amount in parenthesis or let's put 0 99 .
So the amount is in 0 99 .
And as you can see , this is coloured in this uh specific colour because it's a a numeric value .
Let's put uh 1 98 and one 90 .
Good night .
Let's put this in quotation marks actually .
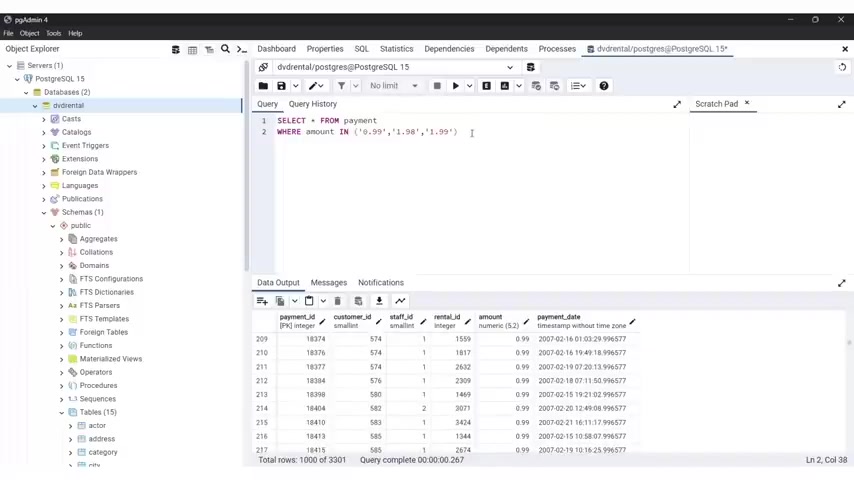
All right .
Now let's run it .
And as you can see now we have all the amounts which a re 1 99 0 99 and uh 01 98 .
As you can see here , So now we have this using the in operator .
No , next , let's say that I want to get the amount which is not in that uh this in this list .
So which is not 0 99 1 98 and 1 99 .
So let's run this now yet .
All the entries which are not in this uh this list of uh entries .
So as you can see , we have 7 99 2 99 but you know , don't have 0 99 1 99 or 98 or one or 1 99 as you can see here .
Now let's uh give one more exa mples with the air , but now I'm gonna use the customer table .
So I'm gonna select everything from Komar where first underscore name in parenthesis , John John , Jake and Julie .
Let's run the I was gonna , you have two customers , Julie and John .
All right .
I'm gonna end this video here and see you on the next video .
Welcome back .
Now it's time to start a discussion about the like and I like commands in progress sequel .
So what are they like ?
And I like commands in progress sequel .
The like and I likes and positive sequel are used for pattern matching within text columns .

They allow you to filter rows based on patterns defined using wild color characters .
The main difference between the two is that like performance case sensitive matching while I like performance case in sensitive matching it is a detailed explanation of the like and I like commands and there is significance .
So we have the syntax and the basis in terms of the like command is lets you have a , a query select from column name or names from table where column name like and have the pattern define the pattern .
Next , we have the basic syntax for the I like command is and the basic syn task for the I like command is select from column name or names from table name where col column name is I like and we define the pattern .
So whatever pattern you are searching for .

Now , two , we have wild killed characters and wild card characters are special characters used to represent one or more characters in a pattern .
The present and I represents any sequence of characters including zero characters .
The underscore represents a single character and the square brackets represents a character class allowing you to match any single character within the specified set .
Next , we have usage and the like and I like are particularly useful and you want to search for values in a column that match a certain pattern .
This is common when dealing with textual data such as names , addresses or descriptions .
They are especially handy when you want to perform partial searches , retrieve records that contain a specific soft string or filter database on specific patterns .
Next , we have case sensitivity like performance case sensitivity pattern matching .

For example , if you like a like a person an I will match rows with the values A a suit but not a with the underscore A .
So now let's look at the I like and I like persons case in sensitive pattern matching , it will match rose regardless of the case .
For example , I like apple with much apple , apple juice and apple juice .
Next , we have examples and uh retrieving our customers with names starting with J we have the following query for doing thats from customer name , contact uh underscore email from customers or customer name like and we put a single quotation marks J and percent sign .
So it will retrieve our customers starting with the letter J .
Next , we have find the products with the na uh NA mes containing blue .

We type select product na me category from products or product NA me like and have and sign .
We have first uh single quotation and sign blue and , and sign .
So this is uh for uh finding products .
Next , we have searching for employees is with the last name ending in son case insensitive .
So we have select for this uh particular example .
We have selects first name , last name from employees where last name like I like per side .
So , so that is gonna return us the employees .
Next , we have wild card characters .
So wild card characters are special symbols using pattern margin within SQL queries .
They are extremely useful for performing flexible searches and filtering , filtering based on specific patterns within text columns .

Here is an explanation of the common with wild card characters , their benefits and when to use them , we have the per side first and the side represents any sequence of characters , including zero characters , use cases searching for values that start with , with or end with a specific sequence of Kates finding record that contain a particular subset within a larger string .
And we have an example , we have uh select product name from products or product name .
Like we have uh single quotation marks per center sign , apple , per sign and single quotation mark .
This query retrieves all products with the names containing the old apple .
So this is very important to have in mind .
All right .
Next , we have underscore and underscore represents a single character .
Use cases searching for V the specific character at a certain position .

You can do that or finding record with a particular pattern where you know the character at a specific position .
Example , you have select customer name from customers where customer name like and have uh single quotation mark J underscore .
So we have the underscore one card N and we have the center side and uh closing uh single quotation mark .
And this query retrieves customers with names that start with J and have any second character followed by N .
So this is what this query is gonna do .
Next , we have square brackets and square brackets represent a character class allowing you to match any single character within the specified set , searching for values that can have variations on specific character position .

For example , if you have , if you for alternate spelling or format example , we have select product underscore name from products where product underscore name like you have single quotation mark call and have the U in , in a square R and , and size in closing uh single quotation mark .
And um we have another , we have uh the same example .
And this query that I presented will match products with the name starting with color and accounts for variation in spelling such as color in British English .
So this is what that is gonna do now benefits of wild card characters flexibility .
Wild cards make your searches more flexible by allowing you to match a variety of pattern without patterns without specifying exact values .
Next , we have efficiency .
You can perform complex searches with a single query .

Eliminating the need for multiple separate queries , reduce query , comple reduce query complexity .
Wild cards simplify query construction by enable you to perform pattern based filtering without writing length and conditional statements .
Next , we have dynamic filtering .
Wild cards are especially useful when you need to search for pattern you within user generated input or when the exact values are unknown .
When to use wi card card , when you need to search for pattern within take data columns , when you want to perform partial searches or receive records that contain specific substances when you need to account for variations in spelling formatting or character positions when constructing dynamic queries where the exact values are not known in advance .
Now , let's see now how combining the sign underscore and square brackets allows you to create even more complex and specific pattern based searches and within S SQL queries .

This combination is particularly on one to need when you need to search for data with a specific structure or a pattern .
While accounting for variations .
Here is an example of how to use this combination .
Along with use cases , we have syntax for combining wild card characters .
We have the I which represents any sequence of characters , including zero characters .
You have the underscore which represents a single character and we have score brackets which represent character class allowing you to match any single character within the specified set .
All right .
And we have use cases searching for email domains .
Suppose we have a database table containing email addresses and anyone who retrieve all email addresses from a specific domain while allowing for variation the domain names such as different subdomains or top level domains , T DLL TT LD .
Let's say you're interested in retrieving email addresses from both example dot com and example dot net .

For that you need to to type the following query , select email underscore address from users from users where email underscore address like .
And we have a single position mark per set and sign example .
And we have uh square bratic underscore and we have dot again , square brackets , opening square brackets , left , left square brack .
You have CNO , right square bracket and we have them .
Now let's go next .
And um the explanation for this query , the presentence present and sign example matches any email address that ends .
With example , the underscore square brackets in square size square brackets matches any single character which can be any character including a dot in the email address dot And we have score brackets .

CNO matches a single character from the character said CNO which covers variations of the TLD like CN or O for uh dot com dot net dot org results .
This query would retrieve email addresses like user at example dot com , admin at example dot net and any other variations that match the specified pattern .
So this is what he's gonna do benefits and use cases , versatile , versatile filtering .
The this combination of iar characters allows you to filter database on complex patterns with a higher level of flexibility .
Next , we have pattern variations , you can capture v variations in data such as different spelling formats or characters without writing separate conditions .
Next , we have dynamic searches .
This technique is valuable when dealing with user input or when you need to adapt queries to much evolving data patterns .

Next , we have efficient query .
Instead of constructing multiple queries , you can achieve the desire uh which filtering in a single query and next word to use first we have user generated input when users provide input that may have varying structure or pattern example names , addresses phone numbers , data clean up when you need to identify and correct in consistencies in data formats .
Domain filtering .
As demonstrated in this example , when you search for specific domain variations in the mail addresses or ULS and in summary , combining the per set and I underscore and score bracket .
And SQL allows you to perform sophisticated pattern watching for specific use cases .
This technique en enhances your ability to filter and retrieve data while accommodating variations in patterns making your queries more versatile and efficient .

Now let's work on some exa Mples inpg admin and I'm gonna use the customer table for this reason .
So I'm gonna type select everything from customer to see how it looks semicolon .
So let's run this and we have the customer ID store ID , first na me last na me , email address ID , active , active bull , and so on .
So let's say that I want to get all the customers whose name starts with the upper case letter J .
So I'm gonna type here at the end of our statement .
I'm gonna delete the , the semi colonial type where first underscore name that type like I , I'll put single quotation marks uppercase J and I'll put as I and now if you run this now get back all the persons whose s whose first na me starts with the letter J as you can see here .
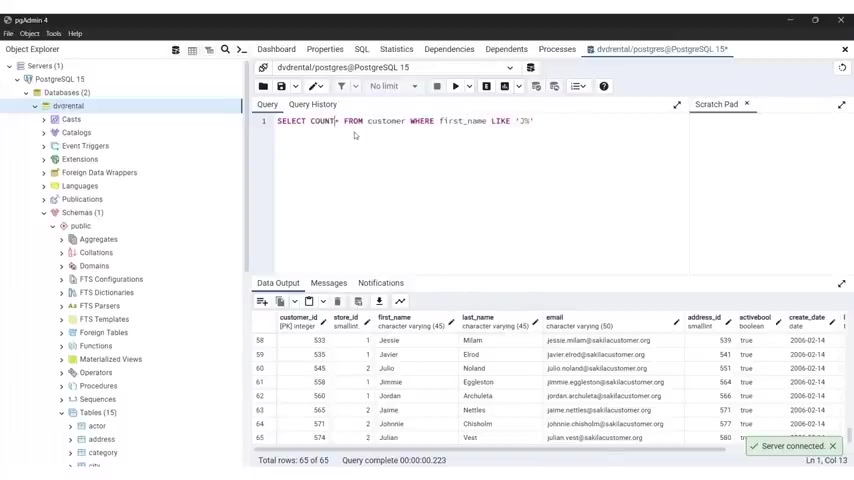
And if you want how to see how many people a re there a re we can scroll down and we're gonna see 65 or we can type here .
Count , count .
And if you run this , it will return 65 .
So there are 65 persons whose name starts with the upper case letter J and I can type here and let's see last underscore name like I'm gonna put like single quotation marks .
I'm gonna put S per certain side .
So now if you run the S as you can see , you get 54 persons back whose first name start with upper case letter J and whose last name starts with uh the upper case letter S as you can see here .
And this is case sensitive .
If I put lower case J here and if I run the S now we will not return uh anything back because now it's case the like is case sensitive .
So it will match the exact letter .
So if it's an upper case J , it will ma match only the upper case Jin the first name .
So um if you want to don't , don't be case and still you type here .
I like and here's also I like and now if you're on this , as you can see , now we get back , Julie Jeffrey J and J uh J and Jimmy .
And yes , and then now we have Sanchez Pier and so on .
So this is uh let's put this on the next line .
This is how we can use this .
Now , let's say that I want to get back .
Uh , let's say , uh what first name ?
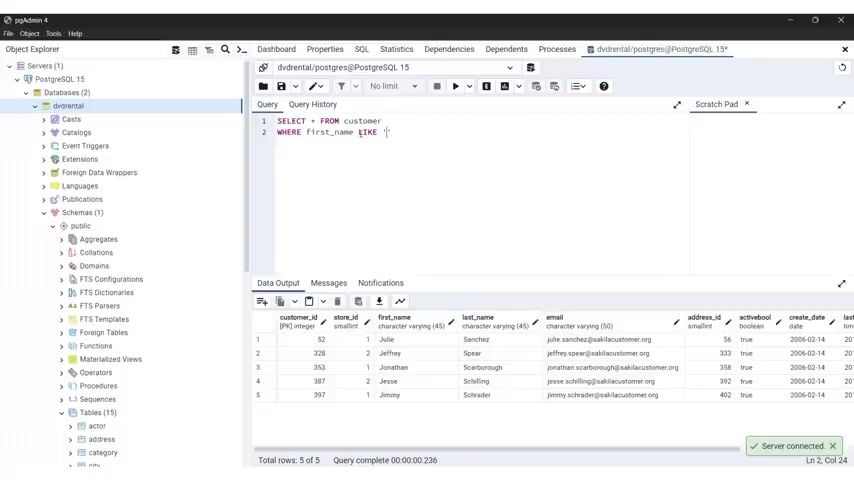
And uh , let's put the , like with upper case letters , like , let's say that I want to get all the uh persons whose first na me have , have in the inin the , in itself , it has uh , the , er , present .
So what , what can I do to achieve that in order to achieve that ?
I'm gonna put single quotation marks , I'm gonna put , let's say uh I'm gonna put person and sign .
So when I say we're gonna get all the characters which are before , er , and which are after , er , so what this is gonna do is gonna re uh re return all the names which have in their characters , which has in their name , the present , er E and R and you will not care about what is before the , er , and what is after the R .
So what this is what you're saying here ?
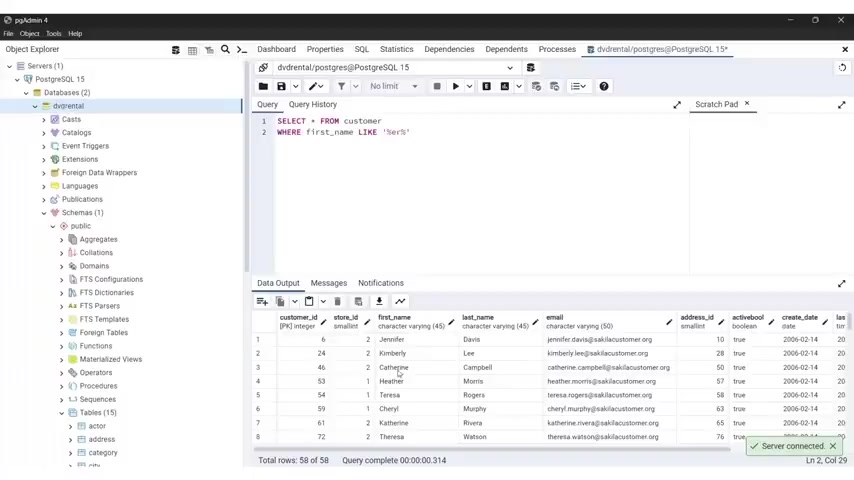
So now if you on this , as you can see , we have Jennifer , we have Kimberly Catherine .
So those , all of those na me have , I present in their construction , their uh first na me the letters enr and we don't care what is before and what is after .
But if you want , uh let's say that before to be only one character in order to do that , I'm gonna put underscore so the underscore uh operator .
So now if you run this , it will only accept now or a single letter before the enr .
So I can see you have Teresa Berta Veronica .
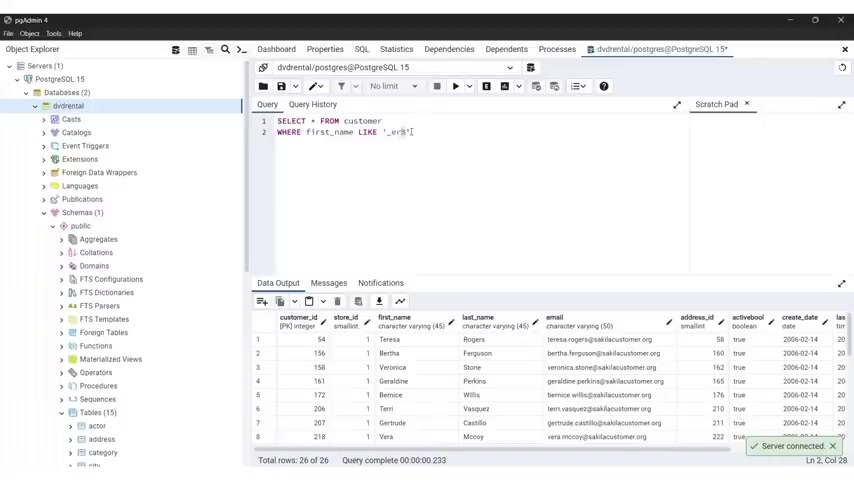
So we have only one letter before , before the , er , and uh uh we don't care by putting the person after the r saying that we don't care what , uh , what is the number of uh uh of characters which uh ca me before the er , so you can put also here another underscore and now we're gonna accept only a letter before the er , and a letter after the er , so now if you run this , you get only this because this is the only , which has a letter before the er , and the letter after the er , so you get only Vera as you can see here .
So this is how you can use the like and I like and you can also put here not like , so you can put , not like .
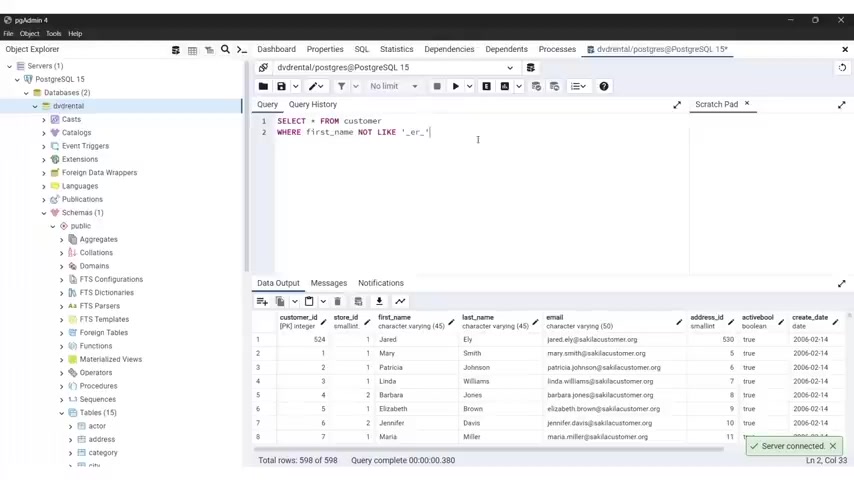
So now if you run this to get all the first Na Mes which uh which don't have the , the er present in the NA Me , we don't have this construction specifically uh a , a letter before the er , and letter after the er , so yet I can see a lot of uh NA Mes which a re which are matching this pattern .
All right , I'm gonna end this video here and see you in the next video .
Welcome back .
Now it's time to do some challenges with the knowledge that we have or quality so far .
And the first challenge is to retrieve the first name and last name and email from all customers .
So this is the first challenge .
And next , I'm gonna give you some hints and the hints are to use the select statement to choose specific columns from the customer table .
And now I'm gonna show you the solution .
The solution is to type select first name , last name , email from customer .
All right .
Now let's do the second challenge .
The second challenge is called conditional retriever .

So challenges to retrieve the payment that the customer id and amount from payments with an amount greater than 100 .
And I'm gonna give you some hints .
Now hints , use the word close to filter row rows based on a condition .
And now the solution solution is to select payment ID , customer ID A mount from payment where a mo is greater than 100 .
So this is the solution .
The next challenge we have sorting and limiting limiting .
And the the challenge is to receive the first name , last name and email of customers sorted by last name in ascending order and limit the results to five .
So this is the challenge .
Now , let's give you , give you some hints .
And the hint is to use the order by clause to show the result and the limit close to restrict the number of rows returned .
Now , the solution is to type select first name , last name , email from customer order by last name as sending , sending ac C limit to file .

So this is the now challenge .
Number five data filtering challenge , retrieve the payment id , customer id and pay my date , the date from payments made in the year 2022 .
I'm G I'm gonna give you some hints , hints , use the and this is something which exceeds what uh I thought to you and uh what I told you and this is to use the extract functions , a re specific components like here from a date .
And uh this is uh uh aggregate function .
I'm gonna look a t the aggregate functions in the next uh chapter .
But uh I I thought that's a way to give you a challenge with this .
Alright .
Solution select from payment select payment ID , customer id , payment date from payment where and we have the extract uh function here from payment date equals to uh to uh 2022 .
Next challenge number five is called pattern matching .

And the challenge is to receive the first name , last name and email of customers whose email contains the gmail .
I'm gonna give you some hints .
Now , hints is to use the light operator along with the wild cards present and signed to perform pattern matching .
Now I'm gonna give it a solution and the solution is select the first name , last name , email from customer where email like and single rotation mark sign , gmail sign , uh and closing single quotation mark .
So this is the solution .
Now ch challenge number six is to is called range query and here need to retrieve the payment ID , customer id and amount from payments with an amount between 5100 inclusive .
Hence used the between operator to specify a range .
And now the solution is to type select payment ID , customer id A mount from payment where a mo is between 5100 .

Alright , I'm gonna end this video here and see you on the next video .
Welcome back now it's time to start a discussion about aggregate functions .
So what are aggregate functions impose sequel aggregate functions are special functions that perform calculations on a set of values and return a single value as a result .
These functions are commonly used to summarize or derive meaningfully in size from large data sets in a database instead of operating on individual rows , aggregate functions work on a group of rows and return a single value for each group .
They are crucial for tasks such as calculating averages , sums , counts , minimum and maximum values and more .
Next , we have some key aspects of aggregate functions and first have grouping growth .
Aggregate functions are often used in conjunction with the group by close that we're gonna study in the videos and the group by close divides the results set into groups based on one or more columns .

The aggregate functions then operate on each group separately producing a single result for each group .
And second , we have common aggregate functions and pore could provide a wider range of aggregate functions that carry to various analytical needs .
Some of the most common aggregate functions include some which calculates the sum of a numeric column within uh a group average which computes the average of a numeric column within a group count which counts the number of rows within a group .
We already use this mean which returns the minimum value from a column , sorry .
So mean which returns the minimum value from a column within a group ?
And max which returns the maximum value from a column within a group right now , let's export those functions in PG .
And I'm gonna use the film table .
So I'm gonna type select everything from the semi colon .
So let's run it and we have your ID title description and we have released your language ID , rental duration , rental rate length and the replacement cost .
And let's say that I want to get uh the movie with the minimum replacement cost .
Let's say that I want to see that in order to do that , I'm gonna delete this and I'll type select mean parenthesis .
Now I'm gonna specify the T A Well , no , I'm gonna specify the columns .
I'm gonna type replacement cost from feel .
Now for on this , we get 9 99 .
So this is the minimum value and you can uh also get uh the maximum value so I can delete this .
Mean I'm gonna type here , marks replacement cost from here .
Let's run it and you get 29 and 99 .
So this is the maximum replacement cost for a movie .
And um what you can do is to select another column here .
So I'm getting type here , let's say uh uh I don't know , less separating it will not work .
So if you on this get the problem as you can see , film must appear in the group by law .
So we cannot select a table , a table , you cannot select uh a column here because uh this uh aggregate function returns only one value and we only get that value back .
And uh because I put here also select the rating from film , it will select uh all the ratings from uh from film .
And we here , we say that we want the value back one single value .
So in this , this because of this , we cannot uh have another column here .
But what you can do is put a comma and I can type here mean unless I have a replacement cost from field .
So now if you run this , now this will work .
We get 2 2099 the maximum value and the MNO value 99 99 as you can see here .
Now let's look at the average function .
So let's delete the S and to get the average , I'm gonna type A VG also for the replacement cost , li we get uh 90 you get 0.98 4000 and we have a lot of decimal points .
Now , we can round this to only a specific amount of decimal points by putting round parenthesis .
And in this uh round , we need to specify first the value that you want to round and the number of digits that you want the value to be rounded too .
So I'm gonna put here , let's say uh I know three closing parenthesis .
And now if you run this , we get 90 90 90 84 .
All right .
So this is how you can use the round .
And you can also let's say that I want to replace all the movies in uh in uh in , in my list .
And I want to see what will cost , how much it will cost me to replace the , all those movies .
In order to do that , we need to use the sum function .
So I'm gonna do this , I'm gonna type S and you told Sam some replacement cast and it will sum all the columns .
So now if you're on this yet , 9 9008 , 8 , 9884 as you can see here .
All right , I'm gonna end this video here and see you on the next video .
Welcome back .

Now it's time to start a discussion about the group by command .
Impose SQL .
So what is the group by command impose GRE SQL or more specifically what is group by and why it is necessary in SQL .
The group by clause is used to group rows from a table based on one or more columns .
This grouping enables the application of aggregate functions such as sum count average mean and marks on subsets of data sharing common values in the specified columns .
Essentially , it transforms individual rows into summarizing information aiding in the analysis of large large data sets and revealing trends and insights that might not be immediately apparent for the group by close to be effective .
It's essential to select categorical or discrete columns .
These columns contain discrete values often representing category categories , classes or labels .

This distinction is crucial because aggregate functions are meaningful only when applied to categorical data as attempting to aggregate continuous data could lead to nonsensical results .
Now the group by operation follows a split , apply combined process .
Let's consider a hypothetical sales table with the columns region product and sales amount to analyze the total sales for each region .
We apply the following steps .
We split the da we .
So first step is split and the data set is basically divided into groups based on unique values in the region column .
The apply aggregate functions such as sum cells amount are applied to the cells amount column within region group .
Combine the aggregated results are combined , creating a summary table that displayed the total sense for each region as you will immediately see in this diagram .
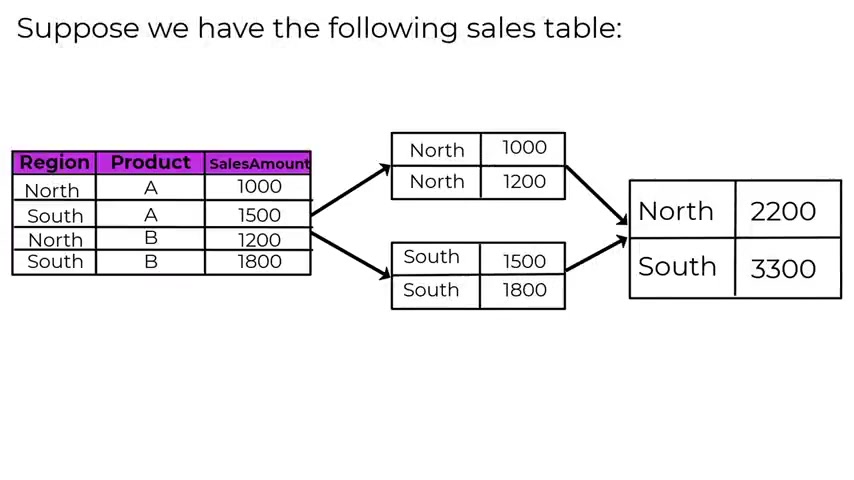
So suppose we have the following sales table and we have the region , the product of the sales amount and you have the region north south and we have the product A ab and we have the sales amount and we have 51,000 , 30,000 .
And uh by applying the group by region , we obtain north and south and north , it has 22 thousands and south is 32,000 because we apply uh some on cells amount uh column .
So now this is uh how that uh will look , it will divide our uh our uh and the categorical data here is the region because we group by that one .
Now when and how to use group by best practices and considerations .

The group by clause serves various purposes and scenarios is this particularly valuable when aggregating data to compute summary statistics such as total averages or counts for distinct categories within a data set segmentation to analyze data by discrete attributes .
Aiding in the identifying patterns and trends reporting for generating summarized reports and dashboards simplifying complex data for decision makers when using group by several considerations and warrant attention column selection , choose categorical columns relevant to the analysis grouping by too many columns can lead to excessive complexity and information overload aggregate functions .

Select appropriate aggregate functions based on insights you seek applying incorrect functions can distort the interpretation of results sorting if necessary specify , sorting order , using order bylaws to arrange , to arrange groups or results in a meaningful way .
Filtering , incorporate filtering criteria often using the having clause .
We're gonna look at this in the next videos to focus on specific data subsets within groups , common pitfalls and mistakes to avoid .
While Gruba is a powerful tool mishandling it can lead to misleading or incorrect results .
Here are some common mistakes to avoid missing columns .

When selecting columns ensure that they are either part of the group by clause or are being used with the appropriate aggregate functions overlooking nulls by be mindful on o of uh null values as they can fake grouping and aggregation results use functions like QSJ to handle nulls appropriately .
You gonna look at this command in the next videos .
Now let's have misplaced where and having clauses place filtering criteria and the word close to filter data before grouping use having close .
We're gonna look at this in as to filter aggregate results after grouping , inconsistent aggregation , be consistent with aggregate functions and grouping columns .
Mixing levels of aggregation within the same query can lead to confusion .
In conclusion the group by command I post SQL is an indispensable tool for analyzing and summarizing data .

It transforms raw data into meaningful insight by applying aggregate functions to categorical columns .
As you saw in the previous example , by understanding the split , applied combined process and adhering to the best practices .
Users can harness the power of group by to uncover hidden patterns and trends within data sets .
However , caution , caution must be exercised to avoid common pitfalls that can compromise the accuracy ability of the results with proper use .
The group or group by clause can become an invaluable asset for any database analyst or data professional enhancing their ability to distill complex data into actionable knowledge .
All right , I'm gonna end this video here and see you on the next video .
Welcome back .
Now it's time to start a discussion about the group by statement import Gray SQL .
But first , let's explore the payment table to see what we have there .
So I'm gonna type select everything from payment .
Let's run this and we have the payment ID , customer ID , staff ID , rental ID and amount and we have the payment date .
So what we have here and this customer ID is CGO gonna use this to group uh to now group by statement to group our customers .
Now what we have here is the customer ID , the stuff with which the , the customer interactive .
So we have the customer ID and it uh interacted with different uh staffs ideas and uh it rental , it rented different movies .
And later we're gonna see how we can join this rental ID to get the actual movie and we have the amount spent on that uh renting on that particular transaction .
Now let's uh let's select the customer ID .
So we gonna run a simple query here from payment .
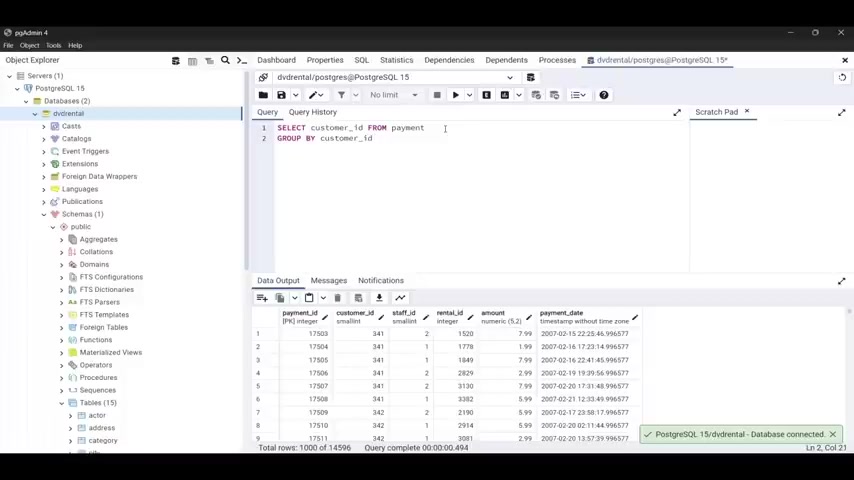
Let's go by customer ID and later on this .
And now we have uh the customer I DS as you can see here .
And this is the same thing as using the distinct uh statement , this distinct keyword .
So what we have here is the customer ID and this uh group by the uh also by the customer ID .
Now let's say that I want to see the amount the total amount spent by each customer .
So I want to see the total amount per customer ID .
In order to do that , I'm gonna put a comma here , I'll type sum .
So I'm gonna use the aggregate function .
I'm gonna uh uh sum the amount group by customer id .
And uh let's run this to see what to get back .
And now get the total a mount spent by uh each uh customer id .
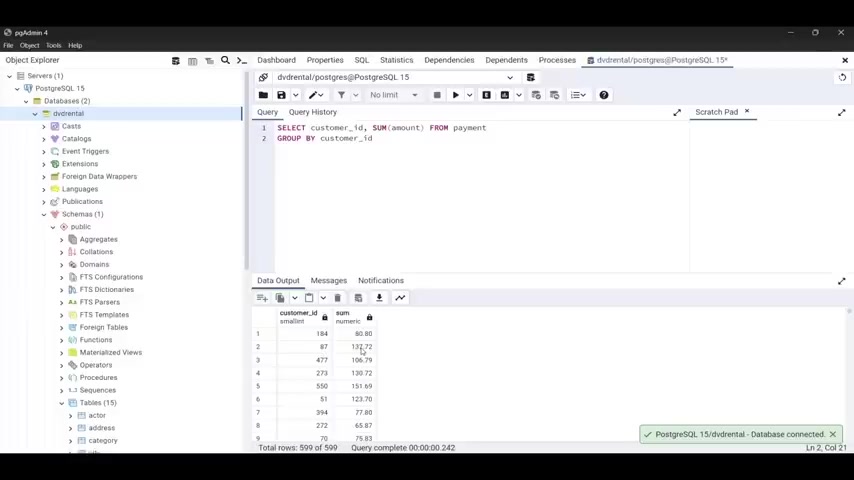
So 184 spend uh probably this is 18 , do $80 and do a $0 .
And uh we have uh customer ID 87 we have this amount and so on .
So now we are getting the total amount spent per customer ID .
Now let's say that uh that I want to order this , I can order by the , I can type your order by and I can't type here simply order by amount because this uh column that we have here sum is the sum amount .
So is the total sum amount .
It's not simply a sum So I need to use here , order by sum and the amount because this is what this column is that we see here .
So now if you run this , as you can see , now it is the order ascending .
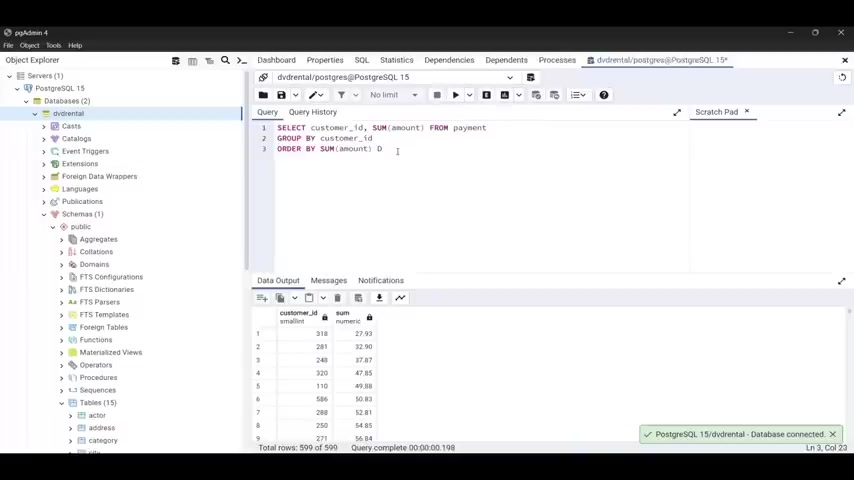
We have uh 318 , we have $27 .
So on .
And uh here we can specify ascending or descending .
So if you're on this , you will get the same output .
And if I type descending , let's run it .
Now we get uh now we get which customer who , which customers spend the most amount on uh renting .
So this is uh ordering this ending .
Now , let's say that I want to select multiple columns in our uh in our query , how I can do that .
What I can do is I can type , let's uh delete this , let's delete this .
Let's select again from payment because I want to see the table again .
So let's run it .
And uh let's say that I want to get the customer ID .
So I want to get a customer ID , the staff ID and gonna aggregate SAM amount from payment .
I'm gonna type here group by and they're gonna grow by the customer ID , customer underscore ID and by staff ID .
And you gonna order order by SAM amount .
I'm gonna explain you immediately what we have here and here should be stuff and a ST stuff ID .
So let's run this .
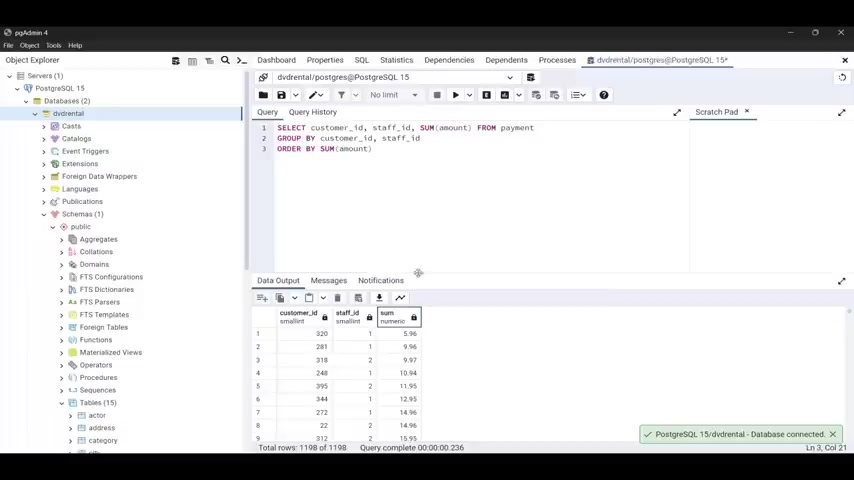
Now , what we have here is we have the we have the some , we have the staff ID and the customer ID and how we will read this , you will read this in the following way , we have the total amount spent with this staff ID by this customer ID .
So we have this total amount spent by staff uh per staff ID and per customer ID .
And as you can see here , we have another customer ID spent with the this staff ID and we have the amount .
So again , we have here , we have the sum amount spent per staff ID .
So with the , the amount spent which uh this particular staff , staff id by per uh by this customer ID .
So this is what we have uh we have uh here .
All right .
Now , let's say that uh let's uh let's dele this .
And uh one of I , one more thing to point here is that you can change the order here .
So I can uh I can put first staff ID and then customer ID .
So stuff , stuff underscore ID and then the customer ID and this is not uh you're gonna have the same data display , but uh you're gonna have the same data , but it's gonna be displayed differently .
You have the further staff ID and then the customer id and the amount so you can change this .
Uh If you want , it will not affect you the query stuff ID .
Now let's delete this and uh let's explore again the payment table let's run it .
All right .
And uh let's say that I want to let me show you first the function , which is the date function .
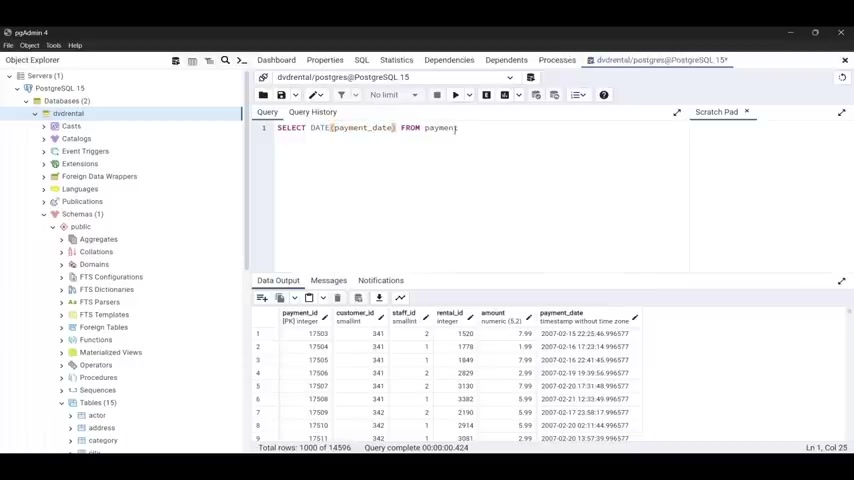
And I'm gonna use the date function on this payment date that we have here .
And uh when I use that because I want to see the some amount of , of uh of uh the some amount of transactions per each day .
So in order to achieve that you need to .
But what that , so I'm gonna type here date , select date .
I'm gonna type here payment date from payment .
I'm gonna type here group by , group by so group by date , we know to organize also payment date and we use this payment , uh we use the date and the payment date .
So you use this thing that we have here because this is a time stamp and I want to get only the day .
So I want to get the year , the month and the day .
I don't want to get the hour .
So by using this date is gonna , you're gonna , you gonna , you gonna do that and uh you can also order so I can type your order by order by again by some and I'm gonna type amount , let's run this and we have uh as you can see here , uh we have the , now we have the data and we have , if you , if you , I think I can increase this .
Let me see .
No , I can't or let me check .
Anyway , we have the year , the month and the day and let's also aggregate .
So let's use the sum function here to get the total uh amount .
So I'm gonna type sum amount .
So I get the A mount per each day .
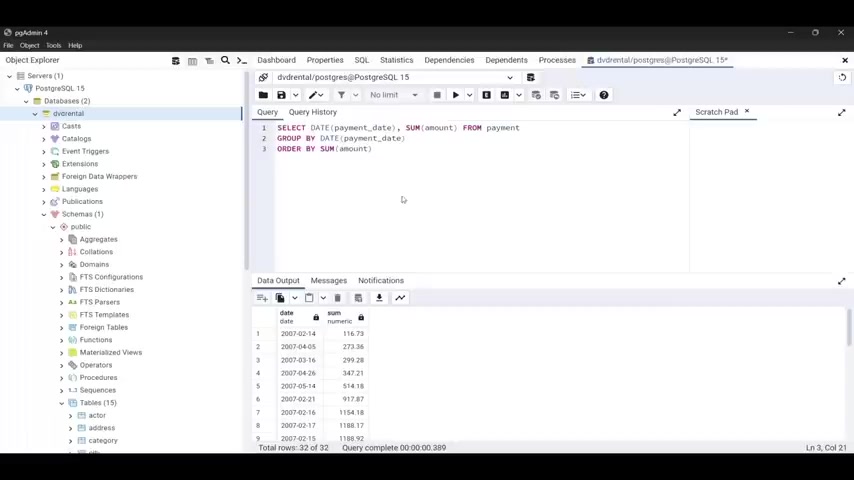
So I get the total a mount which it was uh spent by each day .
So if you run this , now , as you can see , we have on this particular date , 2007 , 0 to 14 , we have 116 and so on .
So now we get the sum amount .
So we get the sum amount per day .
And uh again , we use date , payment date in order to get the only to get only this uh to get the the date in this particular format which which is the year , the month and the day .
So not do not include the , do not include the , the hour because I don't want to see the each tra each the total amount on each transaction per minute .
I want to see them by the day .
So this is why I use day here .
And um this is our discussion .
One more thing that I forgot to show you is that you can um you can select the total sum amount select , let's type here um customer id .
So just a second customer id and instead of some amount I'm gonna , I'm gonna use count .
So count amount to see the total number of transactions per , per customer ID .
So group buy grow by and I will type here .
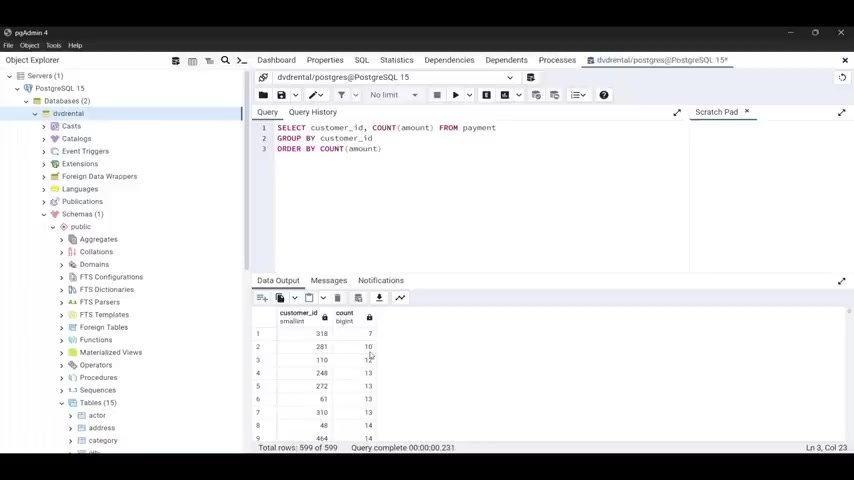
So I'm gonna type group by customer id order by count amount .
So notice that this .
Now it's answering the question , what is the total amount of transactions and uh per each customer ID ?
And uh previously it was asking the question , what is , what is the total amount per customer ID ?
So now if you run this gonna get this in the output , so you see the customer ID 318 had seven transactions , the customer 281 had 10 and so on .
All right , I'm gonna end this video here and see you on the next video .
Welcome back .
Now it's time to do some challenges using the knowledge that we have so far .
And the first challenge is to find a total amount collected by each staff member .
This is the expected result .
A list of staff ideas along with the total amount they have collected .

Hint is considered using the group by clause and aggregate functions like some and the solution is to type select stuff ID column , sum amount from payment group by stuff ID .
This is the solution to our first challenge .
Our second challenge is to list all the payments made on a specific date .
Expect the result .
A list of payment I DS amounts and payment date for payment made on specified date .
Hints use the word close to filter rows based on payment date and this is the solution select payment id amount , payment date from payment where payment date equals and we have the year , month and day .
All right , I'm gonna end this video here and see you in the next video .
Welcome back .
Now .
It's time to start a discussion about the having command impose gray sequel .
So what is the having command ?

The having command impose GRA SQL is used in conjunction with the group by clause to filter the results of a query based on the aggregated values of a column or columns .
It allows you to apply conditions to the results left after grouping has been performed .
In other words , while there were close filters , individual rows before they are grouped , they have enclosed filters , groups of rows .
After they have been grouped , it is a breakdown of key aspects .
First , we have purpose , the having clause is used to filter rows in the results .
After grouping an aggregation specifically when you want to filter groups based on aggregated values usage , it follows the group by clause and comes after the SQL query .
The basic syntax is select the column name the aggregate function on the column from the table group by the column and having at the end of having and put the condition .

So next , we have need for having while the word close filters individual rows before grouping the having close filters groups of row based on the aggregated results .
This is especially especially useful when you want to filter out groups that met certain criteria scenario to use .
You should use having when you need to filter out groups on aggregate functions like count sum average et cetera .
For example , finding the average salary of departments with an average salary salary greater than a certain value .
Next , we have comparison with where use where to filter individuals before grouping and having to filter groups after ire avoid unnecessary complexity while having is powerful , avoid over using it or making it too complex .
Sometimes it might be more efficient to use sub sub queries or other methods to achieve the desired result .

And we're gonna look at sub queries in the next uh in the next chapter .
Now , performance consideration when using having consider the performance impact , especially when dealing with large datasets , improper use of having can lead to slower query execution times examples .
So let say that you want to find the departments with more than 10 employees , you type select department count and put asterisks from employees group by department having we put having count greater than 10 and you will find all the departments with more than 10 employees .
Now let's say that you want to find the average salary of departments with an average salary above uh 5000 .

So let's say that you in order to do that to type select department then use average salary from employees grew by department having used the average salary greater than 5 50,000 .
And in summary , the having clause is used to filter group and aggregate result based on certain conditions .
It is particularly helpful when you want to apply condition to the groups of data after they've been grouped and aggregated using the group by clause .
However , it's important to use it judicially and consider its impact on query performance .
Now , let's explore the payment table to see how we can use the having command .
So I'm gonna type uh select , you're gonna select everything from payment from payment .
Let's run this and you have the payment ID , customer ID , staff , ID , rental id amount and uh payment date .
Now let's say that I want to see the sum amount per customer ID in order to do that .
I'm gonna type here select customer ID .
I'm gonna put the comma that function sum one amount from payment grove by goodbye customer .
I , so this will return the amount per customer id .
So if you run this , we get 184 and it has 80 87 has 137 .
So now we're getting the amount .
So the total amount per customer ID .
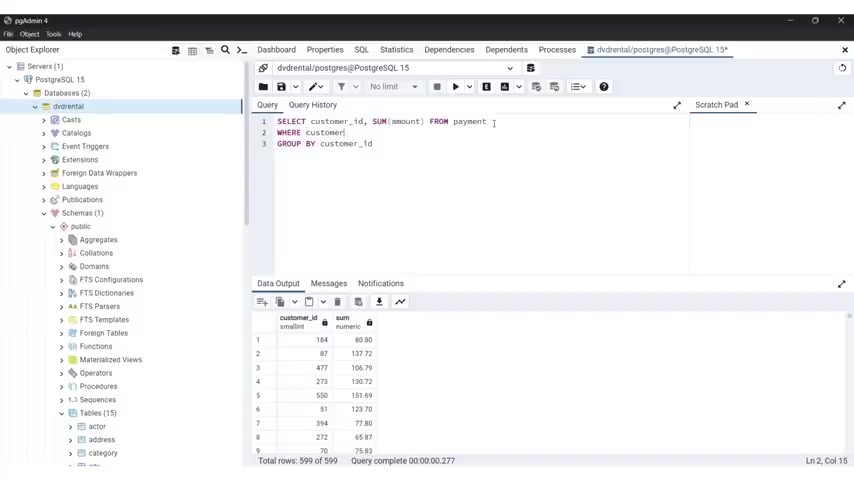
Now let's say that I want to filter this or of course that I can put here .
We also command and type in .
I can type your where and I can type uh let's say customer underscore ID , not in parenthesis .
Let's put 184 to see that it will filter that out and uh it is that one and let's run this .
And as you can see now , 184 87 are skipped because we use this nothing .
But what if I want to filter the based on the sum amount ?
So I have the column sum amount here and I want to filter based on the sum amount column .
Ho how I can do that ?
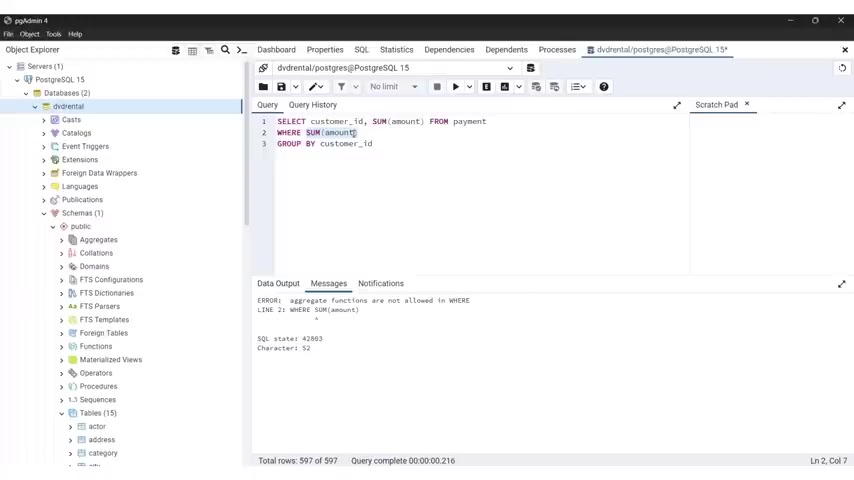
I can type here select where customer and type sum am this seems OK .
But if you run this , it will not work .
And I explain , I will explain why .
So we can't do this because this uh is uh uh disagreed the , this uh ar function which aggregates that column and this uh sum amount .
Let's uh actually , I'm gonna keep this , this sum amount is called only when you call the group by .
So in order to filter our group results , we need to add a hal command after the group I and it will filter the aggregated result .
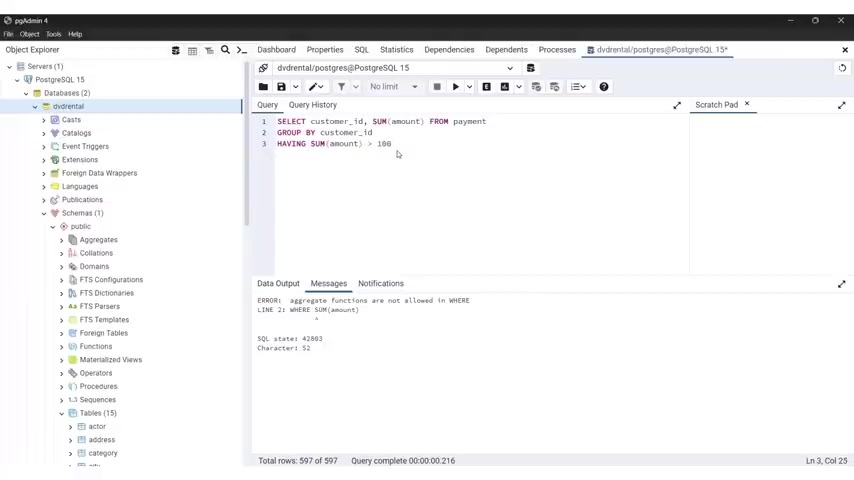
So if I go down here and I type hal and I'll put here some amount , let's put greater .
It has to be a bull and express .
So it has to be true or false .
Greater than 100 .
Now it will work .
And we have the sum amount and as we have all the amounts here is the sum amount is greater than 100 because now it's filtering the aggregated results using this having , but we we again , you can't use the the sum amount in the way because the sum amount that is here .
So this part here is going to be called when the the group by is rich .
So when this command the series , it will call some amount and it will aggregate the results .
All right .
Now let's explore the customer table .
So let's select everything from customer from customer and let's run it and have the customer ID , ID , first name , last name , email address ID , active , bull and create date , last date , last update , active .
So on now , let's see that I want to see the total number of customers per store .
How I can do that in order to do that , I'm gonna go here , I'll type select from when I select store ID .
I'm gonna put comma count .
I'm gonna count the customer ID .
So I'm gonna count the customer id from customer group by store ID when I grew by the store ID to get the total number of customers per store .
And uh let's run it like this .
And then I'm gonna use the halving and as you can , we have 326 and 273 .
So we having the total number of customers per store .
So store number one has 32 6 , uh 300 to 326 customers and store number two has 273 customers .
Now , if I want to filter this aggregated result .
What I can do is I can type here having and I will type count customer id because that column is the count customer ID .
It is not only customer ID .
If I put customer id here greater , less put than 300 you only have one , greater than 300 this one .
So now if you run this , as you can see , we have one and 326 and you can also put here an asterisk because this is actually saying here how many rows are per store ID ?
So I can put asterisk here and asterisk here and it will work .
So if you on this get the same result .
But by using the customer ID here , I can see specifically that I am uh I am aggregating using the customer ID column .
So let's put customer ID back .
All right , I'm gonna end this video here and see you in the next video .
Now time to start a discussion about the statement in postgrade sequel in postgrade SQL .

You can think of the statement as a tool that lets you give nicknames to tables , columns or calculations within your queries , just like how you might give your friends nicknames .
You can give this element easier to remember names to make your queries less confusing .
You'd want to use the as statement when and we have first you want to give friendlier names to columns in query results .
Two , you're dealing with mad or complicated stuff .
And you want to simplify things by using a simpler name .
Three .
You're working with a table and its and its own copy kind of like a twin and you need to tell them apart .
Here is how you do it .
His type , select original name as new name from table name .

Next , remember these four things if you want to use spaces or special characters in your nickname , put the nickname in double codes , choose nicknames that make sense and are easy to understand .
Don't go for really short or confusing nicknames .
Three , be consistent with your nicknames to keep things organized .
Four , while nicknames don't usually slow , slow down your query , don't go overboard with them in uh super complex queries .
And finally , so the statement is like giving your SQL elements friendly names , making your query less of a puzzle to solve .
Now , let's work on some exa MS to see how we can use the operator .
So I'm gonna type here , select everything from payment to see how it looks , payment .
And I'm gonna run this and we have the payment ID , customer , id stuff , id , rental , id and amount .
And let's say that I want to see the total number of transactions in order to do that .
I'm gonna use the count functions .
I'm gonna type count , I'm gonna use the column amount .
And if I run this now we have the total number of transactions .
But if you look a T this for the first time , you will not uh see specifically what this is uh because this is , as you can see here is called count .
Well , uh let's uh use the as operator to see how we can rename that to make it more clear what uh it is some type the as operator and I'm gonna type uh number transactions .
So now you put on this , now we see specifically that this represents a number of transactions made .
Now let's uh let's delete this .
So let's delete this part .
And uh let's select the customer ID , gonna sum them .
I want to see how much each customer spent amount and I'm gonna go to buy customer ID .
So no further on this , we see that uh each C if we see the total uh a mount , which c which uh each customer spend , I guess it , the customer 184 spend 80 but we don't see specifically what this is because this is simply called sum .
So let's rename it .
And today I'm gonna use the as operators here as and uh I'm gonna call it total spend to see more specifically what that is and we have now total spent here .
So now we see specifically that this is the total spend the total amount spent by each customer as you can see here .
Now , we can use the halving here .
So I'm gonna type here hal and I'll type here some a month let's put greater than 100 .
So now we're gonna get back only the sum amount which is greater than 100 .
So now we run this , I can see we have uh only greater than 100 .
And uh one important thing to note is that the as operator gets executed at the end of a query , meaning that we cannot use the alias , the alias inside the word statement .
So if um so this is called total spent .
OK ?
So if uh let's say that I put here uh All right .
So let's say that I put here instead of some amount I'm gonna put here total spent .
Now , if I run this , we'll get an uh uh error which is column , total spend , it says does not exist .
So this is because the as operator gets a T the end of the query , meaning that we cannot use it here in order to , to u use the having here , we need to use the sum and the amount .
So if you run this , everything works fine .
All right , I'm gonna end this video here and see you in the next video .
Partnership
Are you looking for a way to reach a wider audience and get more views on your videos?
Our innovative video to text transcribing service can help you do just that.
We provide accurate transcriptions of your videos along with visual content that will help you attract new viewers and keep them engaged. Plus, our data analytics and ad campaign tools can help you monetize your content and maximize your revenue.
Let's partner up and take your video content to the next level!
Contact us today to learn more.