
https://www.youtube.com/watch?v=FdcXJ7d3WQU
2023-12-11 16:39:38
Deploy Your Private Llama 2 Model to Production with Text Generation Inference and RunPod
In this video , you're going to learn how you can deploy your own private WA A 2.0 chat model and we'll build a private arrest API and I'm going to show you how you can prompt the model as well .
Can you deploy WA A 2.0 on your own private machine ?
Yes , you can .
In this video , I'm going to show you how you can deploy the W A 7 billion chat model on a single GP U using Ramport .
Also , I'm going to show you the text generation influence library and how you can deploy on the R report .
Then we are going to make some API requests using the rest API library requests .
And finally , I'm going to show you how you can stream the responses from our W A 2.0 model using the text generation client library .
Let's get started .
There is a complete text tutorial that is available for mo expert pro subscriber and in it , you can also find a link to the Google Co Op notebook .
So if you want to support my work , please consider subscribing to I Expert pro .
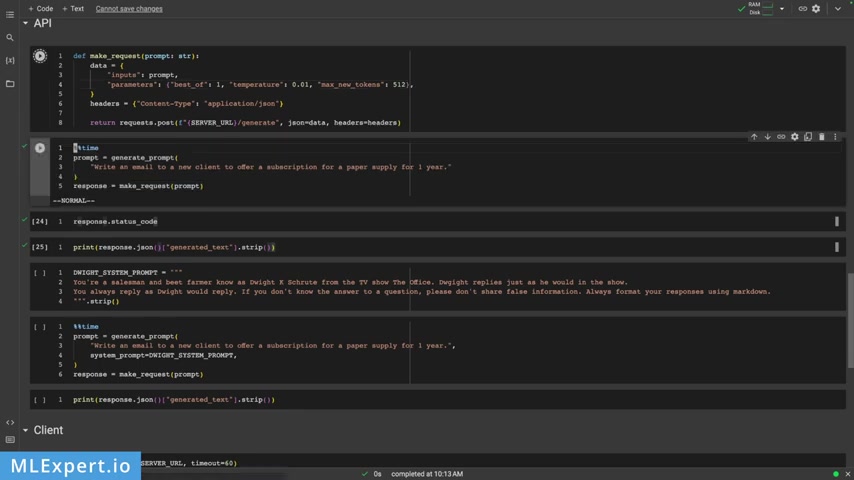
Thanks the library that we're going to use in order to run our influence for the U two model is going to be called text generation influence .
And this is a library created by the Hanging Face Company .
And you can see that is open source .
And one of the important things about this library is that it is used in production actually at hanging phase and it powers the Hanging phase chat , the inference API and the inference endpoint .
So it is really well maintained and it works in production already .
So one of the important things is that it supports token streaming using several sent events .
So we can stream the responses from our work language models .
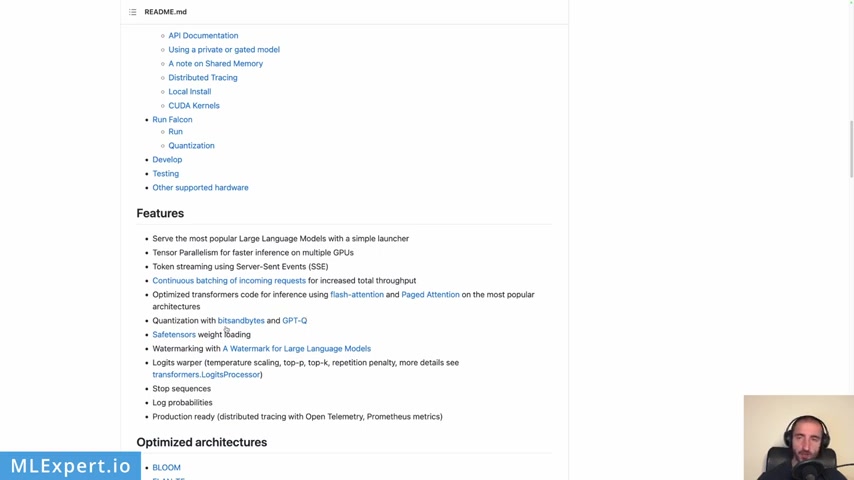
It supports quantization with bits and bytes and GP TQ something that we are not going to actually use within this video , but you can try it out and it allows as to what safe tensors which pretty much uh compress the size of our models .
So we're going to use that .
And there are a lot of optimized architectures for which this library works .
And as you can see at the worst point right here , uh they say that it is optimized for one version two .
So this is great what this library actually uh holds or provides is a Docker container which you can use in order to run the influence .
And this is something that we're going to use with the AMP pot to host our text generation inference Docker container .
I'm going to use a pot .
And this is one of the options that you have in order to host your GP US .
Of course , you can use Aws Azure or something else .
But this is something that I found that is pretty easy to set up .
And I'm going to show you how we can do this within this video .
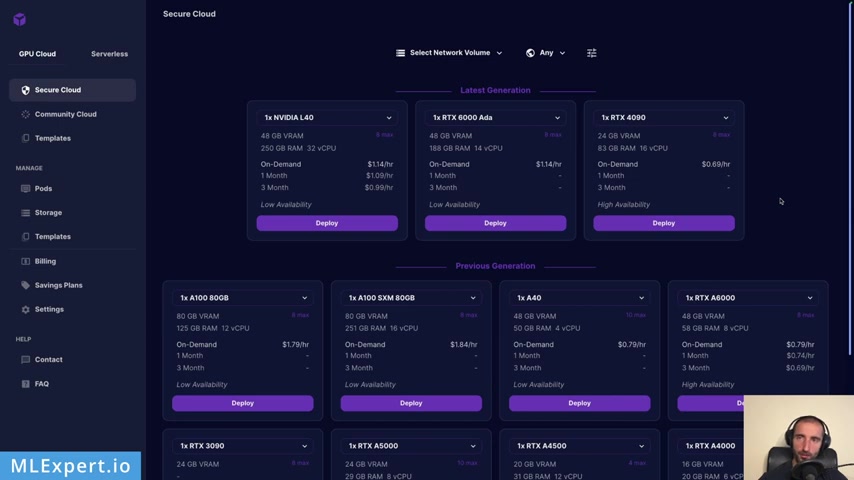
Once you sign up for a import account , you will be presented with something like this .
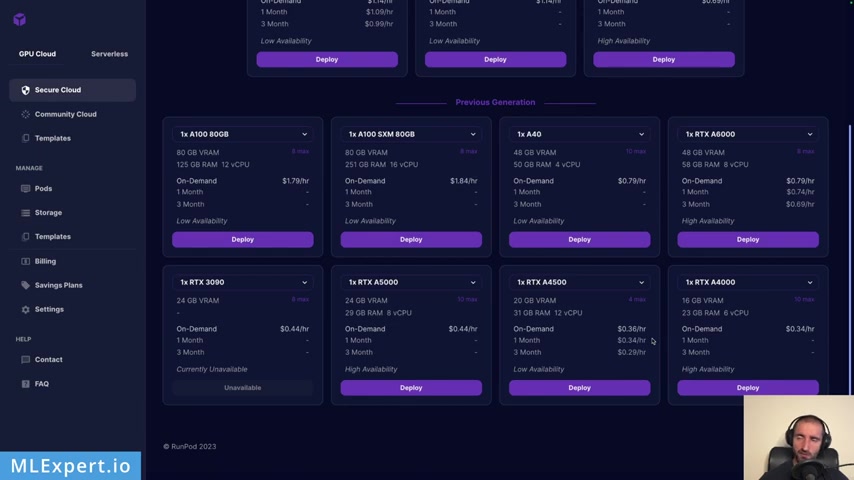
Uh From here , you can basically choose your GP U but also you can choose the data center location that you're going to use .
In my case , I'm going to use the European Union , Romania Data center .
And from here , you can also select a network volume and you have some other filters as well .
Uh How many mem how much memory , how many uh CP us , et cetera and uh this type as well could the version as you can see .
So in our case , I'm going to use the RT X A 4500 , and it has 20 gigabytes of VA and I'm going to use the on demand option .
I'm month and three month options .
I guess that you can rent out for a specific time .
Uh Also there is a community quote option , but I'm not going to go through that .
It is basically uh some people that are renting out their GP US .
Uh In this case , I'm going to use the secure quote .
You also need an API key which we're going to use within the Google Club notebook .
And to get yours , go to settings API keys and then create an API key with the plus API key button .
Right here .
I have a Google web notebook that is already running and you can see that I've also installed some of the dependencies .
Uh I'm using the Ramport client library , the text generation a library that comes from text generation influence and then I'm upgrading the request library within the Google Club notebook .
And next , you can find some of the I DS of the GPS that are available from port .
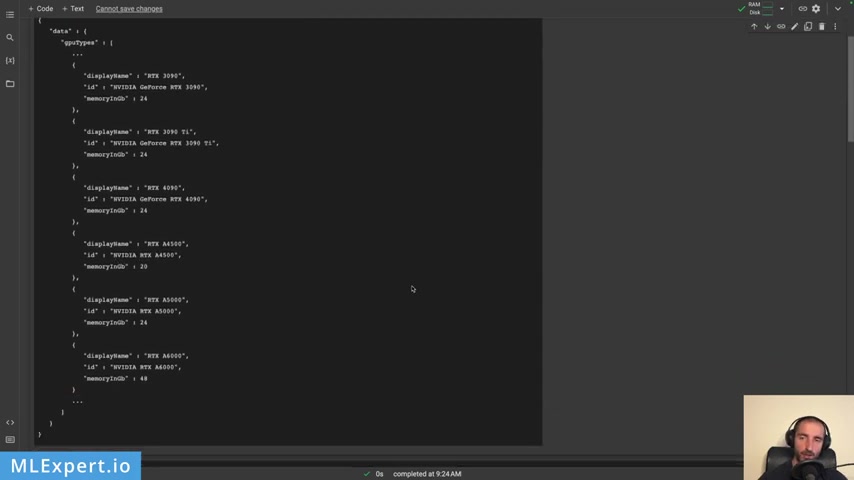
And from here , I'm going to actually take the NVIDIA RT X A 45 OO and in our case , I'm also going to get the imports from the request , the R report and the text generation client .
The first thing that you need to do is to pass in your API key right here within the Google Cloud notebook .
And then I'm going to create a GP U instance with this create port function .
And here I'm going to name it and I'm going to pass the image of the docker container to text generation inference .
One of the pretty much the one of the latest versions .
Uh The latest one is 1.0 and they did something with the licensing there .
So here I'm also passing the GP U type ID , the data center that I'm using a secure quote and the one of the most important parameters here is the model itself .
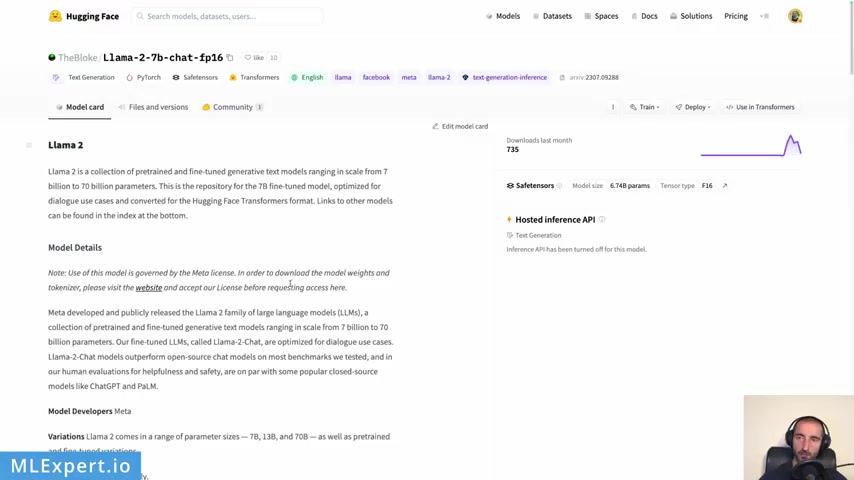
So in our case , I'm going to use this repository in her face by the book and this is pretty much a copy paste from the original wa A A model , but it doesn't require the key that you need in order to download your model .
So I think that this is pretty much the same model but just cloned version of it .
So thank you the blog for that .
You don't need to actually request the model itself .
But if you want to be sure that everything is all right .
Uh Please go ahead and download the model from the W A repository .
Also , you can pass in your API key to the HM face , so you can actually download this within the environment variables .
Uh One of the important things here is that I'm increasing the volume uh gigabytes and here I'm passing in a 50 gigabyte uh the model itself .
It's going to take more than 10 , I believe .
Let's see what the files a re yeah .
Uh roughly 14 gigabytes of memory just to store this model .
We're going to download these too uh and the Tokes itself , of course , but that's pretty small compared to this .
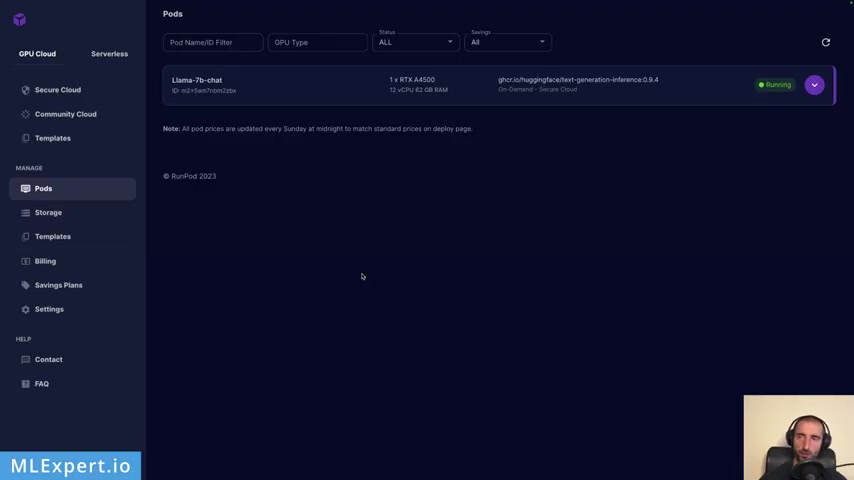
So once you pretty much go through this , uh you can go to the report and after some time after you run this , you have this instance that is going to be deployed and is going to be running and you get something like this , not that uh we're using a 93% of the GP U and you can go to the box right here .
It should be something like this and this is confirming actually that it is downloaded the model uh within the two files and then it is doing a warm up .
Yeah , right here .
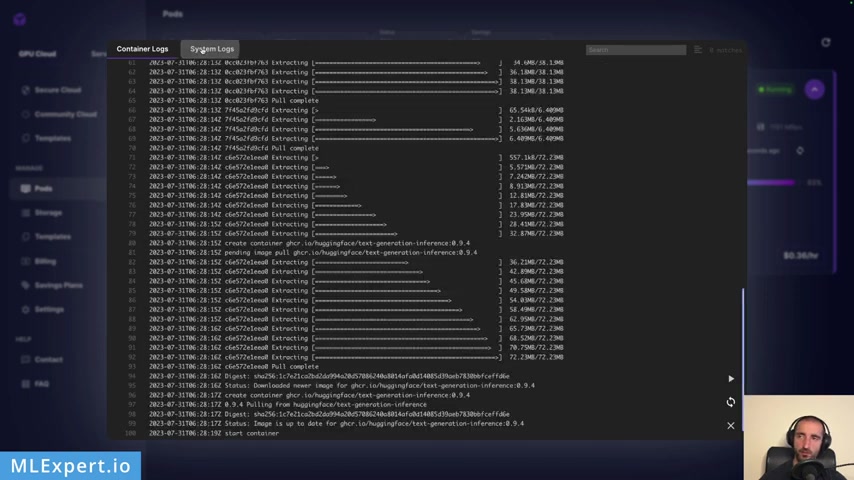
So it's passing up some tokens and running through the inference on your own drone And the system works , you see that it is went ahead and downloaded the complete Docker image so you can deploy it within your machine .
So it should look like this and everything should be running smoothly from there .
So let's continue with the Google App co op notebook .
So this is actually um some information about the pot , the image name and you have uh of course a unique identifier for your machine .
And in order to run this , you have this server and on this server , you have something that is called swagger UI .
And if you open this , yeah .
So this would be actually your server , right ?
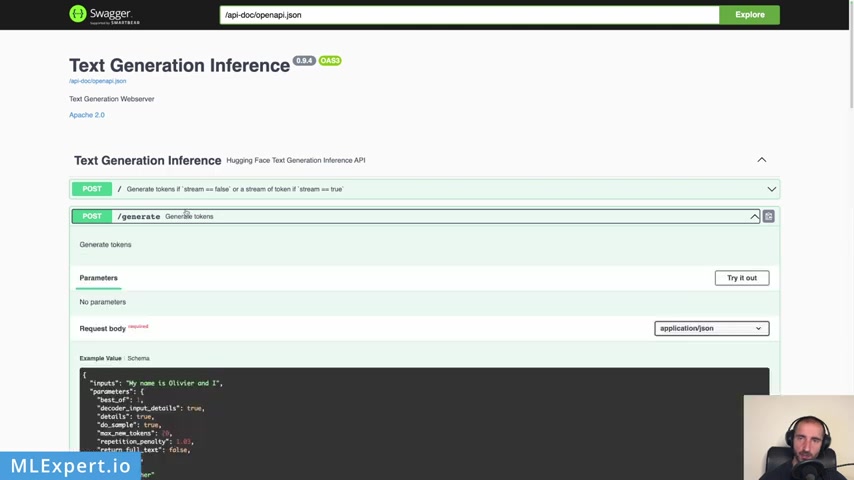
And here you can pretty much look at the two methods that we're going to use the generate tokens method or the generate method .
And here you can go through the parameters that you're allowed to pass in uh the most important one being the input or the prompt .
And then some of the parameters you can see that you can have a temperature sampling a repetition penalty , et cetera .
And this is a sample response that you're going to get from the API and then you have this generate stream end point , of course , which is going to work within the server sent events .
So this is pretty much the documentation that you get from the swagger ui uh you have a health check and you can actually try out the requests .
Let's see , he'll check .
What does it tell us ?
Let's execute this .
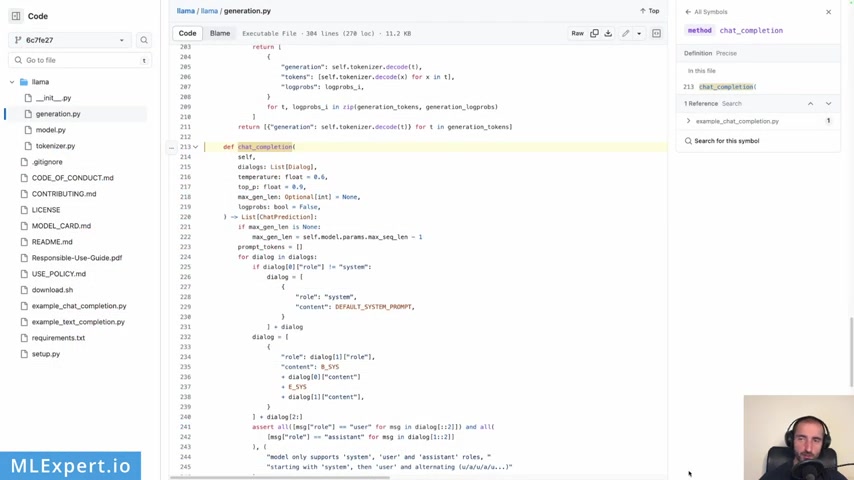
So the first thing that I'm going to do is to properly format the system prompt and the prompt for the W A 2.0 And this is pretty much the template that we need to use to generate the proper format for your prompt .
Uh You have to pretty much use a template that the authors are using and this is the official one repository .
And if you go through this method , code chat completion , you see that it essentially provides a formatting for your prompt .
So it has started with the instruction on be begin instruction and then end instruction .
Uh You can see here also , you probably have to go to the constants on the top which represent the begin instruction and end instruction right here .
So these are the tax data they're using .
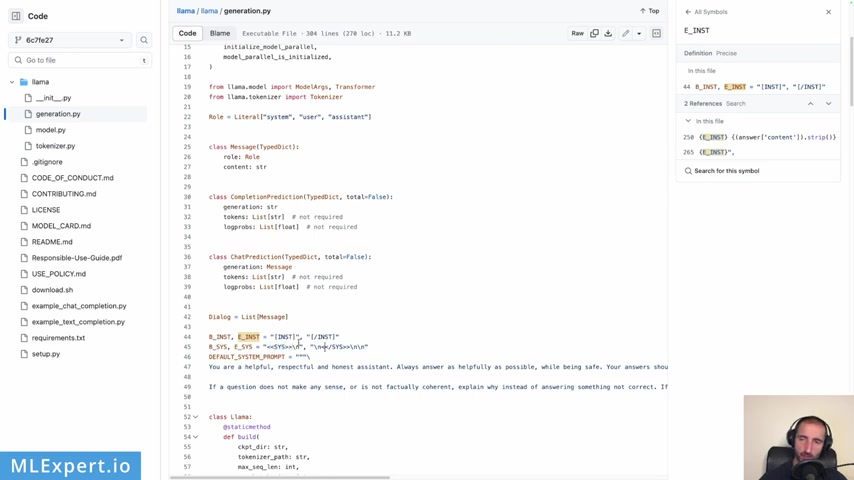
And also there is this begin system and end system I would say .
So these are again , special tasks that you need to wrap your system prompt within .
Also , you are presented here with the default system prompt that this library is providing for you .
So in order to run the one model properly , we will need to essentially use this same format .
And to do that , I'm going to create a function code , generate prompt and within it , I'm going to pass in the prompt and the system prompt .
And from here , you can see that I'm using the same format , the instruction , then the system within that .
And then I'm passing in the system prompt and then the prompt itself .
So in order to test this , I'm going to run this .
So , and then we are going to create our first request to the API of our model .
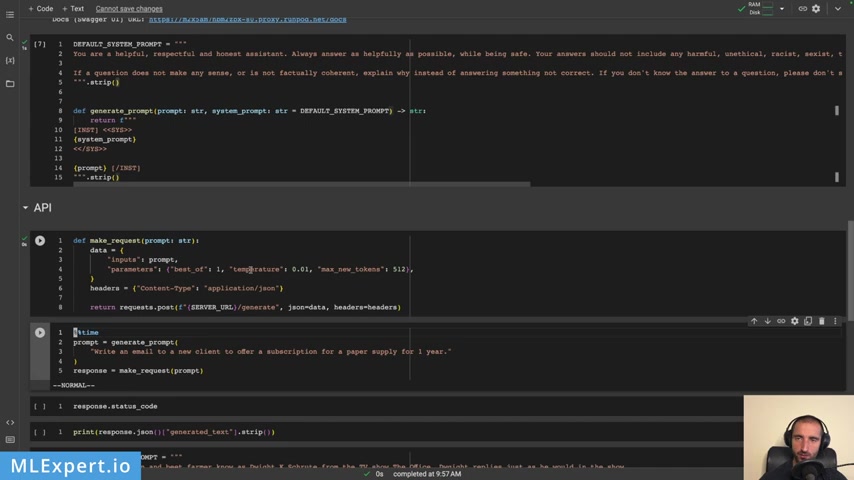
So this is pretty much a parameter code with best of one .
So we want just a single sequence and then I want the temperature to be a very low number .
Unfortunately , you're not allowed to pass a temperature of zero .
I'm not sure why .
But the API is like uh drawing an error if you do that .
And I'm also passing the max new tokens .
In our case , this is going to be 512 .
Uh note that W A 2.0 supports up to 4000 context length .
So uh take a look at your parameters right here and here is the prompt that I'm going to use .
Write an email to a new client to offer a subscription for a paper supply for one year .
And know that I'm passing in the default system prompt , which we're going to use and this took about 10 or 11 seconds .
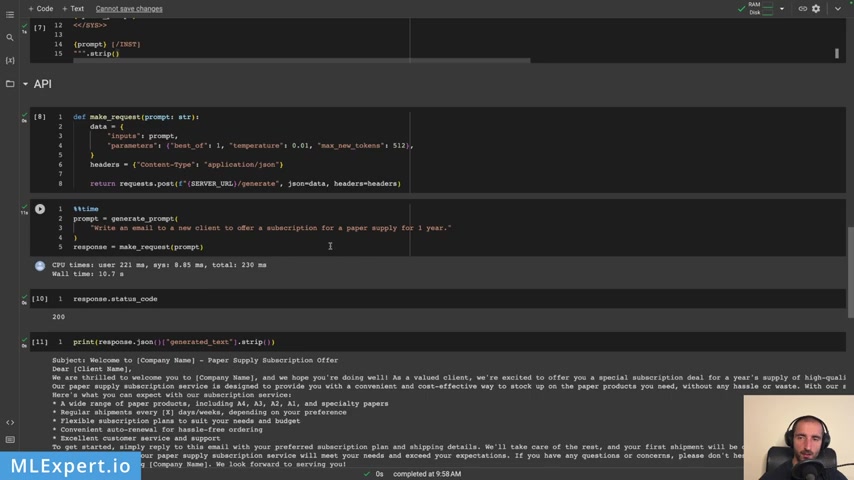
Let's see the response code 200 and this is the email that was generated by the 12.0 model .
And yeah , you can see that it is very good and it is providing a bullet point , bullet point points .
Yeah , at least uh with the benefits to get started , simply reply to your to this email .
Yeah , it looks pretty good .
I would say that the prompting is working much better compared to my previous video where I found that the model didn't perform as expected .
Probably the prompting techniques are really important for this model as well .
So now I'm going to change the default system prompt , uh your assessment and bearer known as do a root from the office .
So yeah , I just want this model to behave as just what Dwight would reply .
So I'm going to use the same prompt .
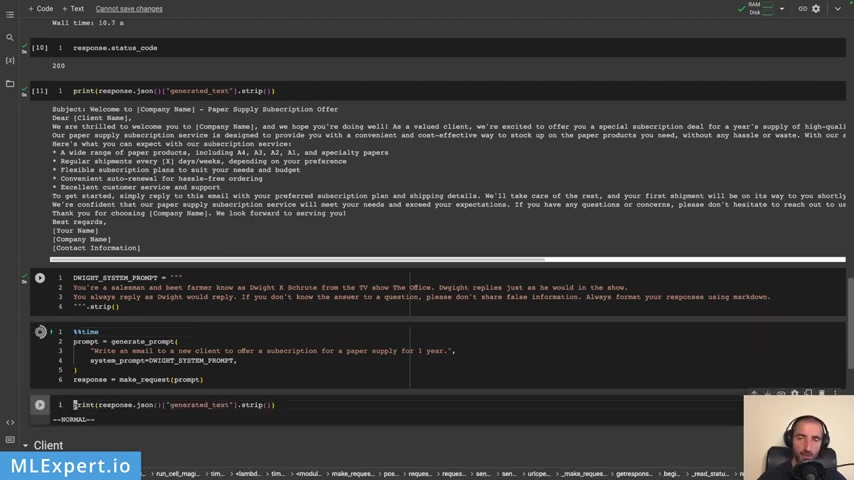
But again , I'm going , but this time , I'm going to change the system prompt right here and let's run through this .
Of course , this is going to take a bit of time again .
And now the model might actually output a lot more tokens .
So yeah , it took about 12 seconds a bit slow compared to the first one .
And let's see the response .
So be the awesome paper supply subscription offer .
So yeah , it says BT .
All right .
So the Beet Farmer .
Greetings from D me Scranton .
Ok .
So it knows that it is , uh , the TV show , it knows about the TV show .
And then as a valued member of the D Metfor community , I'm extend to offer exclusive opportunities to subscribe to our top notch paper supply for the next one year .
So this sounds something like Dwight might say .
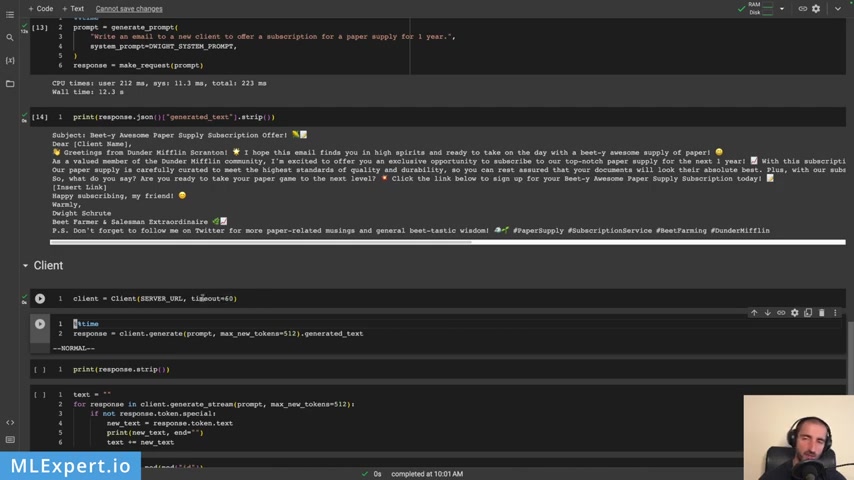
But yeah , here it looks like the emojis are a bit too much .
At least here is subscribing my friend warmly .
Dwight's ro best farmer and salesman , extraordinaire .
OK .
Some of this is pretty good , but probably you might want to dial out or dial down the emojis themselves .
OK ?
So another way instead of using the API is to use the text generation inference client .
And this is uh from the library itself , you just need to pass in the server URL and then I'm going to pass in a time out of 60 seconds since the default value is 10 seconds .
And this might be a bit low when you're waiting for responses that are much bigger .
And I'm going to create the same a response for this one .
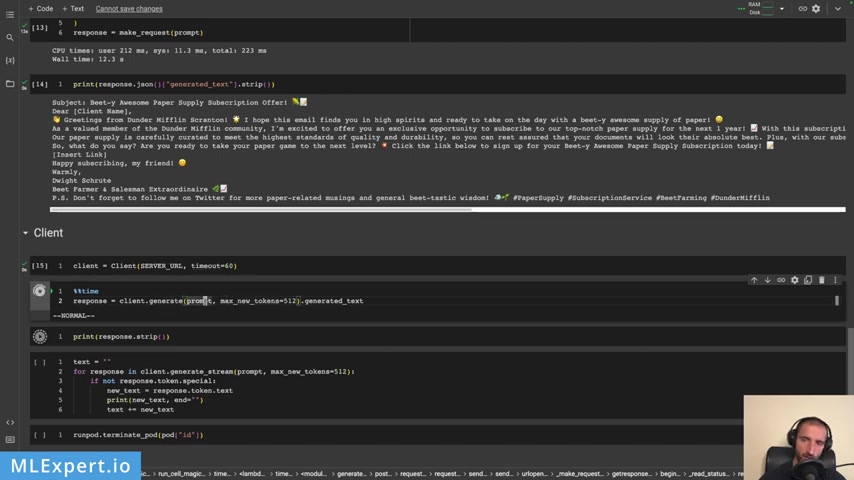
And yeah , you're just passing in the generate the prompt , which is again , is the same thing that we had thus far .
And then the maximum tokens parameter .
Uh this took about 14.5 seconds and uh the response is uh pretty much the same I would say .
Yeah , it should be uh we're using pretty much the SA me temperature .
Yeah .
OK .
And finally , and we can use the generate stream and this will create an iterator uh which you can iterate over and then you can print out the text if you want to .
So let's see , you can see that the streaming is working .
Yeah .
And I would say it's pretty fast .
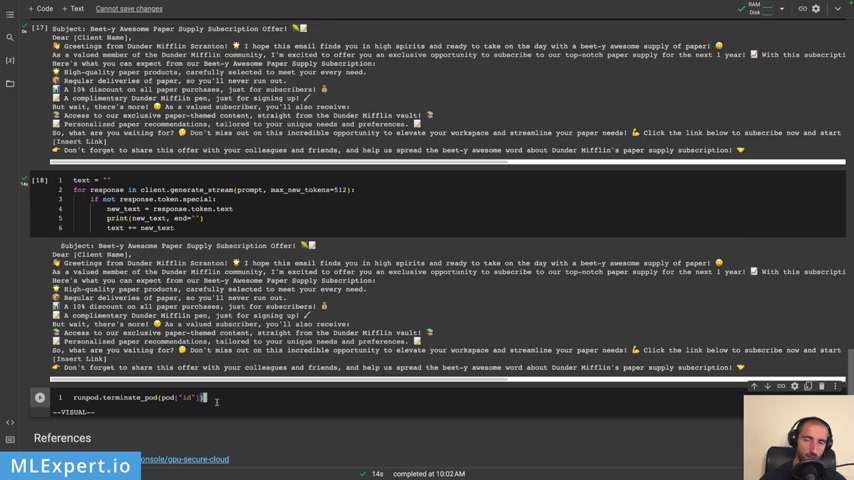
Uh This is hosted on a single GP U and it costs about 33 4 cents per hour in order to run this one A seven B model .
So this is pretty cool .
And the final thing that I'm going to show you is to how to actually terminate the machine .
This will go ahead and actually delete the pot .
So you don't have to pay anything over that and they should go and terminate your machine .
This is it for this video in it .
You've seen how you can deploy your private wa A 2.0 model .
We've used the 7 billion parameter model and we've deployed it on a single GP U .
We took a look at the text generation in library and we made some API requests to the API from the library .
And then we have a look at the text generation influence client , which is going to allow you to first call your model and then use the generate stream in order to stream your responses from your 12 point model .
Thanks for watching guys , please like share and subscribe .
Also , please join the Discord channel that I'm going to link down into the description and I'll see you in the next one .
Bye .
Original video
Partnership
Are you looking for a way to reach a wider audience and get more views on your videos?
Our innovative video to text transcribing service can help you do just that.
We provide accurate transcriptions of your videos along with visual content that will help you attract new viewers and keep them engaged. Plus, our data analytics and ad campaign tools can help you monetize your content and maximize your revenue.
Let's partner up and take your video content to the next level!
Contact us today to learn more.