https://youtu.be/dBoQLktIkOo
How to use the Llama 2 LLM in Python
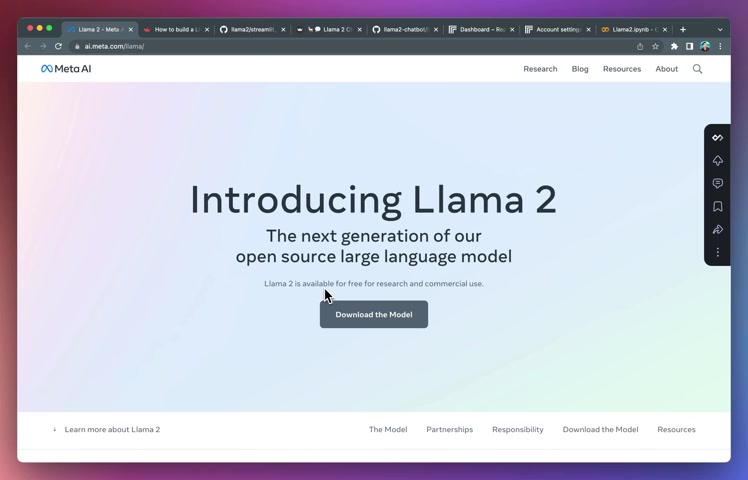
You probably noticed that a few days ago meta A I released your open source large language model called Lama two .
The great thing of this model is that the performance is greatly improved .
It's free for research and commercial usage .
And in this video , I'm going to show you how you could use it in only a few lines of code .
And without further ado let's dive in .
So this Lama two Gibber notebook provides you a quick glimpse at how you could leverage and use this open source large language model for your Python projects .
OK ?
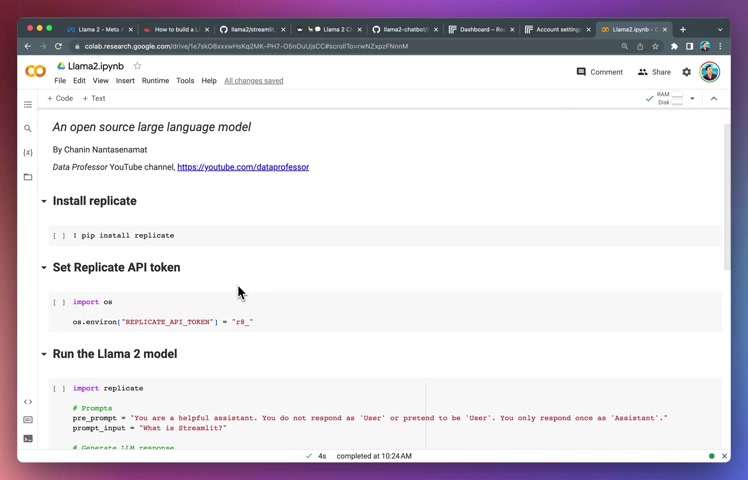
So first thing is you want to install the replicate library and I don't think I mentioned already into too much detail , but then replicate allows you to get access to the hosted version of the Lama two model .
Because otherwise , if you want to run it locally inside this coat notebook , I'm not sure it will work unless you're using a GP U version because this default one here is AC pu version .
So this would be a topic for another video as well .
The hardware that is being used for running the large language model and that's the name in place is it will consume a lot of computational resource in running the model and generating the response .
So let's install it by pip install replicate and it is installed and then we're going to use OS module and then we want to assign an environment variable called replicate API token .
And then in here in the quotation mark , we're going to replace it with the API key .
So don't worry , I'll delete this particular key after the tutorial , run it here .
And then it is now in the environment variable .
And then let's run the lamma two model .
So here , first we're going to import the replicate library .
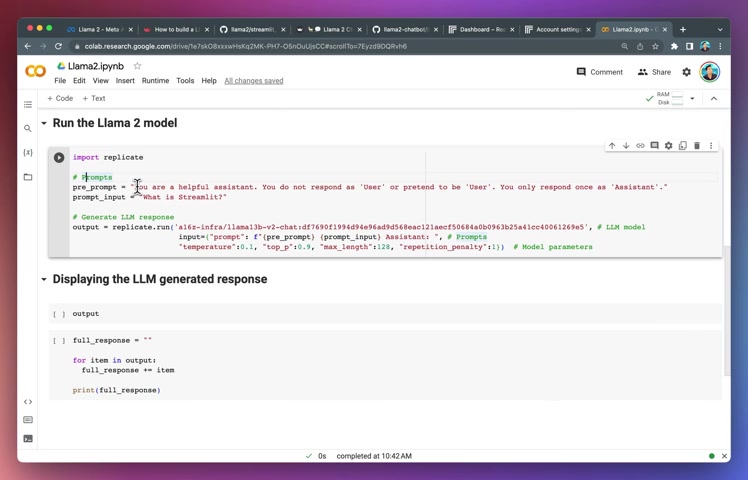
Then for the prompts here , we're gonna create two variables .
The first one is the prep prompt and it essentially will provide the model with a general instruction on how to perform the generation of the response .
So here we're going to say that you are a helpful assistant .
You do not respond as user because it tends to do so or pretend to be user .
You only respond once as an assistant .
And then the actual prompt that we want to ask is here what is trim for example , or it could be what is Python ?
And then we're going to generate the response using replicate dot run .
And then for here , we're specifying that we want to run using the 13 billion parameter version from the replicate platform .
And then for inputs , we're using the F string to combine the prompts and the prompt inputs , right ?
Because both of this will be a string , a single string together with the assistant .
So the assistant here will just be telling the large language model to generate a response for the role of an assistant .
And for the model parameter , we're specifying temperature to 0.1 the top p parameter to 0.9 .
And essentially the lower the value for temperature will give you less creativity .
But then it will give you a more standard response .
A higher value will give you a more creative response .
And the top P here is essentially the top ranking cumulative probability to be used as the generated response .
Because a typical large language model will predict the probability of each word to use one by one .
And when we're using a lower value here , we're just going to use the top ranking abilities .
So feel free to modify these parameters as well .
And the maximum length for the generated token here will keep it small and we make it as 1 28 .
But if you need a larger response , then you could play around with this parameter as well .
And here we're specifying the repetition penalty to one .
All right .
And so let's run the model here and it's already run because we're asking it a simple question and we're limiting the maximum length to 1 28 .
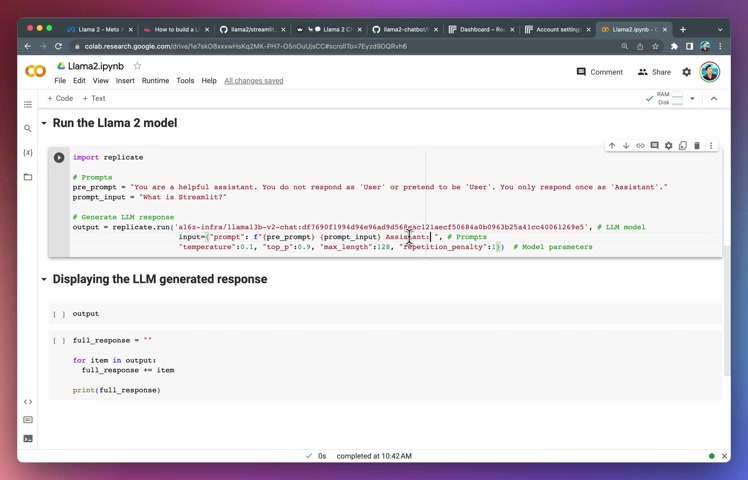
If you're looking at the output , you're going to see that it is a generator object .
So what you want to do here is you want to iterate through the object and then you want to append all of the individual chunks of texts together into a full response using the four loop .
And then we're gonna print the full response otherwise it will give you chunks of words .
And there you go .
This is the generated response .
Trile is a Python library that allows you to create web applications with Python .
OK .
So this is a very simple video on how you could use Lama two model .
I'd love to learn how you're going to use this large language model for your own projects .
And so drop your ideas down in the comment section and let me know what other videos that you'd like me to make .
And as always the best way to learn data science is to do data science and please enjoy the journey .
Are you looking for a way to reach a wider audience and get more views on your videos?
Our innovative video to text transcribing service can help you do just that.
We provide accurate transcriptions of your videos along with visual content that will help you attract new viewers and keep them engaged. Plus, our data analytics and ad campaign tools can help you monetize your content and maximize your revenue.
Let's partner up and take your video content to the next level!
Contact us today to learn more.