Load from PC
2023-06-14 17:58:51
deeplearninAi_LangChain_Lesson2_v02

When you interact with these models naturally,
they don't remember what you say before or , or any of the previous conversations, which , which is an issue when you're building some applications like chatbot and you want to have a conversation with them.
And so in , in this section , we'll cover memory , which is basically how do you remember previous parts of the conversation and , and feed that into the language model so that they can have this conversational flow as you're interacting with them .
Yeah .
So chain offers multiple sophisticated options for managing these memories .
Let's jump in and take a look .
So let me start out by importing my open AI API key and then let me import a few tools that I'll need .
Let's use as the motivating example for memory using land chain to manage a chat or a chatbot conversation .

So to do that , I'm gonna set the OM as a chat interface of open A I with temperature equal zero .
And um I'm going to use the memory as a conversation buffer memory and you see later what this means .
Um And I'm gonna build a conversation chain again later in this short course , Harrison will dive much more deeply into what exactly is a chain and land chain .
So don't worry too much about the details of the syntax for now , but this builds an L M and if I start to have a conversation conversation dot predict , give the input .
Hi , my name is Andrew .
Let's see what it says .
Hello and just nice to meet you .
Right and so on .
And then let's say I ask it what is one plus one ?
Um , one plus one is two .
And then Oscar again , you know what's my name ?
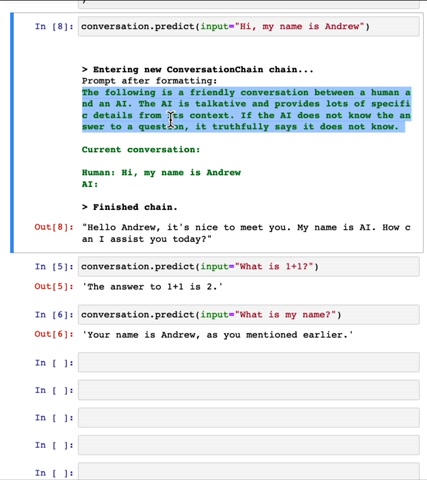
Your name is Andrew , as you mentioned earlier , the trace of sarcasm there .
Not sure .
And so if you want , you can change this verbals variable to true to see what land chain is actually doing when you run .
Um predict high .
My name is Andrew .
This is the prompt .
The land chain is generating .
It says the following is a friendly conversation between a human and an A I A as talkative and so on .
So this is a prompt that chain has generated to have the system , have a hopeful and friendly conversation and it has to save the conversation and here's the response .
And when you execute this on the um 2nd and 3rd parts of the causation is it keeps the prompt as follows .
And notice that by the time I'm uttering , what is my name ?
This is the third turn .
That's my third input .
It has slowed the current conversation as follows .
Hi , my name is Andrew was one plus one and so on .
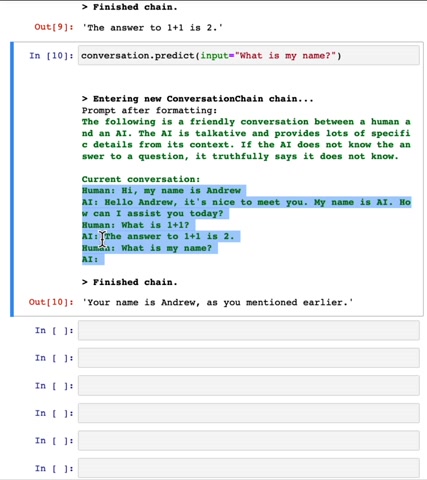
And so this memory of this history of the conversation gets longer and longer .
In fact , up on top , I had used the memory variable to store the memory .
So if I were to print memory dot buffer , it has stored the conversation so far .
Um You can also print this out memory dot load memory variables .
Um The curly braces here is actually an empty dictionary .
There's some more advanced features that you can use with a more sophisticated input , but we won't talk about them in this short call .
So don't worry about why there's an empty curly braces here .
But this is what lang chain has remembered in the memory of the conversation so far .
It's just everything that the A I or that the human has said I encourage you to pause the video and run the code .

So the way that line chain is storing the conversation is with this conversation buffer memory , if I were to use the conversation buffer memory to specify a couple of um inputs and outputs .
This is how you add new things to the memory if you wish to do so explicitly .
Memory dot save context says hi , what's up ?
I know this is not the most exciting conversation , but I wanted to have a short example .
Um And with that , this is what the status of the memory is .
And once again , let me actually show the uh memory variables .
Now , if you want to add additional um data to the memory , you can keep on saving additional contact .
So conversation goes on .
Not much .
Just hanging cool .
And if you print out the memory , you know , there's no more stuff in it .
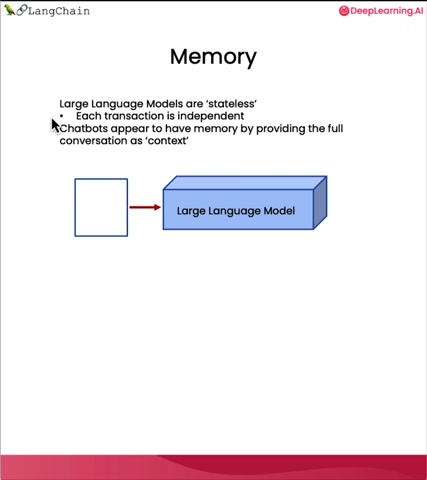
So when you use a large language model for a chat conversation , um the large language model itself is actually stateless .
The language model itself does not remember the conversation you've had so far .
And each transaction , each call to the API end point is independent and chat was a period of memory only because that's usually rapid code that provides the full conversation that's been had so far as context to the L M .
And so the memory can store explicitly the turns or the utterances so far .
Hi , my name is Andrew .
Nice to meet you and so on .
And this memory storage is used as input or additional context to the O M so that they can generate an output as if it's just having the next conversational turn , knowing what's been said before .
And as the conversation becomes long , the amounts of memory needed becomes really , really long .
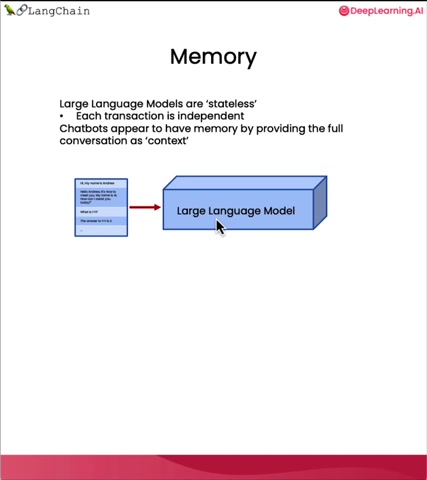
And does the cost of sending a lot of tokens to the L M which usually charges based on the number of tokens it needs to process will also become more expensive .
So that chain provides several convenient kinds of memory to store and accumulate the conversation .
So far , we've been looking at the conversation buffer memory .
Let's look at a different type of memory .
I'm going to import the conversation buffer window .
Every that only keeps a window of memory .
If I set memory to conversational buffer window memory with K equals one , the variable K equals one specifies that I wanted to remember just one conversational exchange .
That is one utterance from me and one utterance from the chat bot .
So now if I were to have it save context , how was up ?
Not much ?
Just hanging .

If I were to look at um memory dot Low variables , it only remembers the most recent utterances notices dropped .
Hi .
What's up ?
It's just saying human says not much just hanging at the A I says cool .
So that's because K was equal to one .
So this is a nice feature because it lets you keep track of just the most recent few conversational terms .
Uh In practice , you probably won't use this with K equals one .
You use this with K sets a larger number .
Um But still this prevents the memory from growing without limit as , as the conversation goes longer .
And so if I were to rerun the conversation that we have just now , we say hi .
My name is Andrew .
What is one plus one ?
And now I ask it , what is my name ?

Because K equals one .
It only remembers the last exchange , which is one , is one plus one .
The answer is one plus equals two and forgotten this early exchange , which is now now says , sorry , I don't have access to that information .
Um One thing I hope you will do is post the video , change this to true in the code on the left and rerun this conversation with verbals equals true .
And then you will see the prompts actually used to generate this .
And hopefully you see that the memory when you're calling the L M on , what is my name that the memory has dropped this exchange where I learned , what is my name ?
Which is why it now says it doesn't know what is my name with the conversational token buffer memory , the memory will limit the number of tokens saved .

And because a lot of L M pricing is based on tokens , this maps more directly to the cost of the L M calls .
So if I were to say the max token limit is equal to 50 and actually let me inject a few comments .
So let's say the conversation is A I is what ?
Amazing back ations .
What beautiful chapels and what charming .
I use ABC as the first letter of all of these conversational threads we can keep track of um what was said when if I run this of a high token limit .
Um It has almost the whole conversation .

If I increase the token limit to 100 it now has the whole conversation starting with A I S what um if I decrease it , then you know , it chops off the earlier part of this conversation to retain the number of tokens corresponding to the most recent exchanges .
Um but subject to not exceeding the token limit .
And in case you're wondering why we needed to specify an L O M is because different L MS use different ways of counting tokens .
So this tells it to use the way of counting tokens that the um chat open the I 00 M uses .
I encourage you to pause the video and run the code and also try modifying the prompt to see if you can get a different output .
Finally , there's one last type of memory I want to illustrate here , which is the conversation summary , buffer memory .

And the idea is instead of limiting the memory to fixed number of tokens based on the most recent utterances or a fixed number of conversation exchanges , let's use an L M to write a summary of the conversation so far and let that be the memory .
So here's an example where I'm going to create a long string with someone's schedule .
You know this meeting am with your product team , you need your powerpoint presentation and so on and so on .
So there's a long string saying what's your schedule ?
You know , maybe ending with a , a new lunch at the Italian restaurant with a customer , bring your laptop show , the L latest L M demo .
And so let me use a conversation summary , buffer memory um with max token limit of 400 in this case , pretty high token limit .

And I'm going to insert in a few conversational terms in which we start with .
Hello , what's up ?
No much ?
Just hanging .
Uh cool .
And then what is on the schedule today ?
And the response is , you know , that long schedule .
So this memory now has quite a lot of text in it .
In fact , let's take a look um at the memory variables , it contains that entire um piece of text because 400 tokens was sufficient to store all the text .
But now if I were to reduce the max token limit , say to 100 tokens , remember this slows the entire conversational history .

If I reduce the number of tokens to 100 then the conversation summary buffer memory has actually used an L M the open A I end point in this case because that's where we have set the L M to , to actually generate a summary of the conversation so far .
So the summary is human .
A , I engage in small talk before the day schedule and forms human and morning meeting , blah , blah , blah , um lunch meeting with customer interested in A I in latest A I developments .
And so if we were to have a conversation using this O M , let me create a conversation chain same as before .
And um let's say that we were to ask you know , input what would be a good demo to show .
Um I said verbose he goes through .
So here's the prompt .
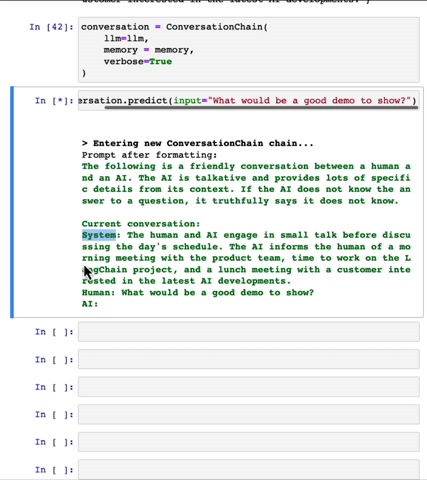
D L M thinks the current conversation has had this discussion so far because that's the summary of the conversation .
And just one note , if you're familiar with the open A I chat api end point , there is a specific system message .
In this example , this is not using the official open A I system message .
It's just including it as part of the prompt here , but , but it nonetheless works pretty well .
And given this prompt , you know , the um output is based A I development .
So I suggest showcasing our latest N R P capabilities .
OK ?
That's cool .
Um Well , it's , you know , making some suggestions to the cool demos and makes me think if I was meeting a customer , I would say boy , if only there were open source framework available to help me build cool N LP applications using O MS , good things are .

Um And the interesting thing is if you now look at what has happened to the memory .
So notice that um here it has incorporated the most recent A I system output .
Whereas my utterance asking it what would be a good demo to show has been incorporated into the system message .
Um You know the overall summary of the conversation so far with the conversation , some buffer memory , what it tries to do is keep the explicit storage of the messages up to the number of tokens we have specified as a limit .
So you know this spot , the explicit storage or try to cap at 100 tokens because that's what we asked for .
And then anything beyond that , it will use C O M to generate a summary which is what is seen up here .

And even though I've illustrated these different memories using a chat as a running example , these memories are useful for other applications too where you might keep on getting new snippets of text or keep on getting new information such as if your system repeatedly goes online to search for facts , but you want to keep the total memory used to store this drawing list of facts as you know and not drawing arbitrarily long .
I encourage you to pause the video and run the code in this video .
You saw a few types of memory um including buffer memories that limits based on number of composition exchanges or tokens or a memory that can summarize tokens above a certain limit .
That chain actually supports additional memory types as well .
One of the most powerful is a vector data memory .
If you're familiar with word embeddings and text embeddings , the vector database actually stores such embeddings .

If you don't know what that means , don't worry about it .
Harrison will explain it later and it can then retrieve the most relevant blocks of text using this type of uh vector database for his memory and LA chain also supports entity memories , which is applicable when you wanted to remember details about specific people or specific other entities .
Such as if you talk about a specific friend , you you can have chain , remember facts about that friend , which should be an entity .
In an explicit way .
When you're implementing applications using land chain , you can also use multiple types of memories such as using one of the types of conversation memory that you saw in this video plus additionally entity memory to recall individuals .
So this way you can remember maybe a summary of the conversation plus an explicit way of storing important facts about important people in the conversation .

And of course , in addition to using these memory types is also not uncommon for developers to store the entire conversation in the conventional database , some sort of key value store or SQL database .
So you could refer back to the whole conversation for auditing or for um improving the system further .
And so that's memory types .
I hope you find this useful building your own applications .
And now let's go on to the next video to learn about the key building block of land chain , namely the chain .
Partnership
Are you looking for a way to reach a wider audience and get more views on your videos?
Our innovative video to text transcribing service can help you do just that.
We provide accurate transcriptions of your videos along with visual content that will help you attract new viewers and keep them engaged. Plus, our data analytics and ad campaign tools can help you monetize your content and maximize your revenue.
Let's partner up and take your video content to the next level!
Contact us today to learn more.