
https://www.youtube.com/watch?v=ZcEMLz27sL4
2024-01-26 17:06:13
Streaming Events - Introducing a new `stream_events` method
Streaming is a incredibly important UX consideration for building LLM apps in a few ways .
First of all , even if you're just working with a single LLM call , it can often take a while and you might wanna stream individual tokens to the users so they can see what's happening as the LLM responds .
Second of all , a lot of the things that we build in lang chain are more complicated chains or agents .
And so being able to stream the intermediate steps , what tools are being called , what the input to those tools are , what the output to those tools are .
Um streaming .
Those things is really important for an IUX as well .
So we've recently added a new method in lang chain to help with this called stream events um which hooks into the callback hand as we have .
So it's very easily modifiable and what it will do is it makes it easy to stream everything basically .
And so this video will cover uh stream events .
It will also cover the basic stream and a stream methods that we have .
So these are simpler methods for dealing with the end responses of of chains or of models and they will take a look at doing this for generic runs and then for uh lane chain agents as well .
So let's jump into it .
This is the docs right here .
A little known fact , all of these docs are also notebooks .
So I'm gonna open up the notebooks version of this .
Um Let's restart my kernel um Just so I can do it with a clean end .
Um And yeah , we're gonna cover two main things here .
We're gonna cover the stream and then a stream methods .
And these are methods for streaming the final outputs of chains .
And then we're gonna cover the stream events uh method .
Oh We're gonna cover the stream events method and this is a way to stream all the events that happen within a chain .
So um all run objects in lang chain .
And so these are every , these are all chains , these are all models , these are basically all objects in L chain , expose a sync method called stream and an async variant called a stream .
And so these methods will stream the final output in chunks yielding each chunk as soon as it's available .
And so as we see as we go along , streaming is only available if for , if every step in the program kind of like knows how to stream things along .
So if you're working with one step in the program , like an LLM , if it knows how to stream , then you can use stream .
If you're working with multiple and maybe one of them doesn't know how to stream and we'll see an example of this later on , then it might not stream .
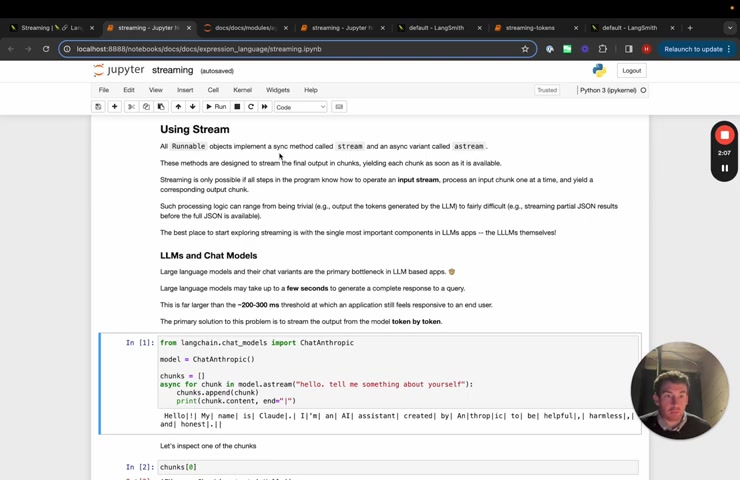
So let's start by looking at the LL MS themselves .
So we'll use an anthropic model here .
And basically , what we'll do is we'll iterate over the chunks in model dot A stream .
Things that come out of these are going to be A I messages .
Um And so what we're gonna do is we're going to append them to a list and then we're going to print um chunk dot content .
Um And so this is just a content field on the A I message when we're going to print this little operator to show this the spaces between the streams .
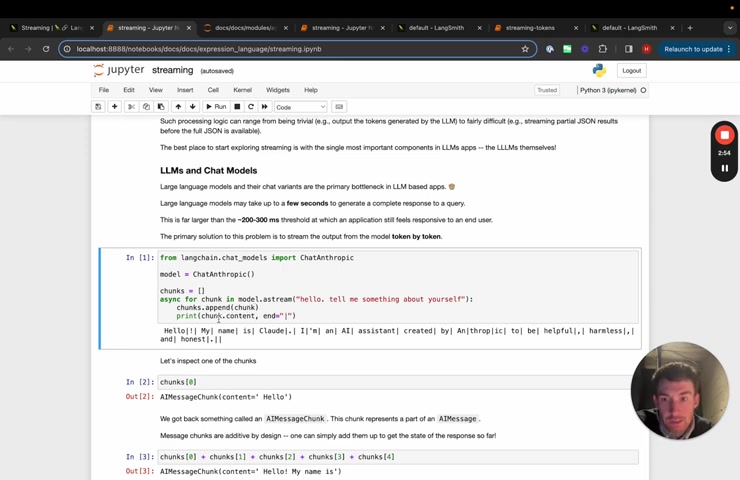
So we can see that it starts to stream as it responds .
If we look at one of these chunks , we can see as A I message , these A I messages , we've , we've made kind of like edible under the hood .
So you can add them up and you can get the final response .
OK ?
So that's a simple LLM .
Now we're gonna look at chains .
And so in this chain .
And so chain is kind of like anything constructed in link chain expression language .
This chain will just be a really simple one where we have a prompt uh parser .
Um And then the chain is prompt model parser .
Um We will invoke it uh with a stream so we'll use async here and we'll stream over things and we can see what happens as it goes through .
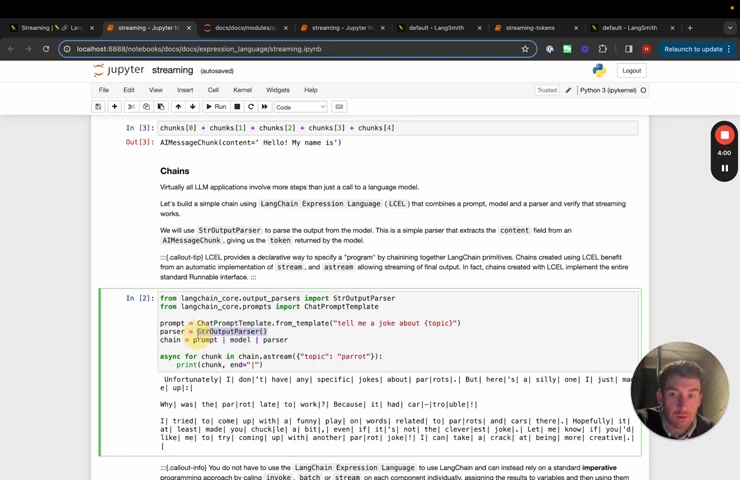
And so basically , we're asking we have a prompt that's formatting it with uh it's tell me a joke about blah .
Um We have this model and then we have this parser and this parser is just responsible for taking the content property off of the message .
And so it's just return a string instead of this A I message , the model and the parture exposed stream methods .
So we'll see that it will stream out as it completes .
There we go .
All right .
So we can also see an example of other things .
Um So uh a more complicated parser that we have um is the JSON output parser which takes in a response from a language model that is supposed to be JSON .
Um But it might be like half completed json , right ?
So this happens when you're streaming the , the like when you , when you're halfway through the stream of A Json Blob , it's not valid JSON .
And so this parser deals with a lot of those peculiarities and parses it accordingly .
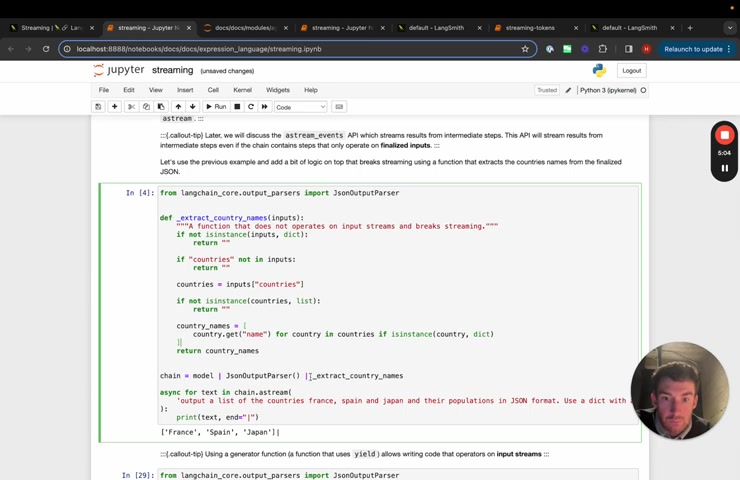
So we can see here that it will start to stream out the more completed kind of like Json Blob as we create it here , we'll see an example um where this doesn't stream .
Um So this is a method that just returns all the country names .
Um And so here , if we add this on the end of the blob , we can see that there's actually no streaming that will happen because this final thing , it doesn't have , it doesn't yield things , it doesn't stream , it doesn't take , it doesn't take in a generator and it doesn't return a generator .
And so it kind of blocks everything .
So it just returns at once at the end if we want to change that , um we can change this and this will start to yield things .
And so why is this happening ?
Um I think this is happening because I have a uh I have some flush issues here .
Um Let's do this , see if this changes things .
Yeah , so we can see here once I add in this .
So there are some flush issues going on , but basically , we can see that it streams back um tokens .
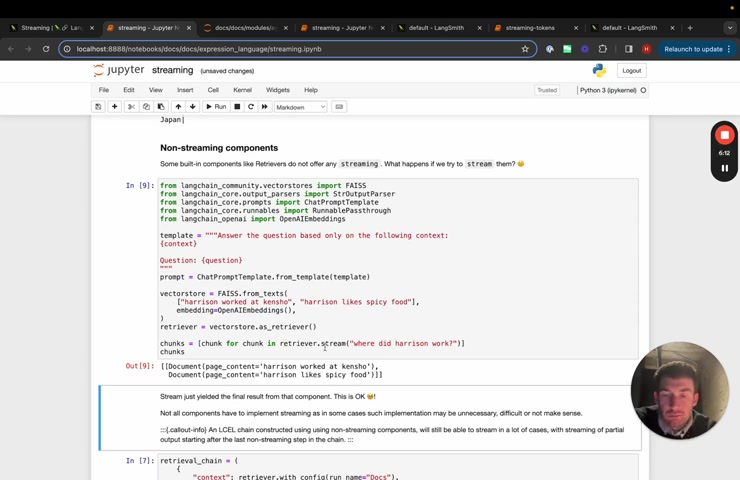
And again , that's because this yields things come up some built in components like retrievers , these don't stream anything .
So if I call uh the um if I call this , it just returns a list of documents , we haven't really seen a need for retrievers to be streaming .
So that's why we kind of haven't implemented a version of that , but you can still use these within chains um that uh uh you can still use retrievers within chains and still stream the final results .
So here's like a really simple rag chain that gets the context back .
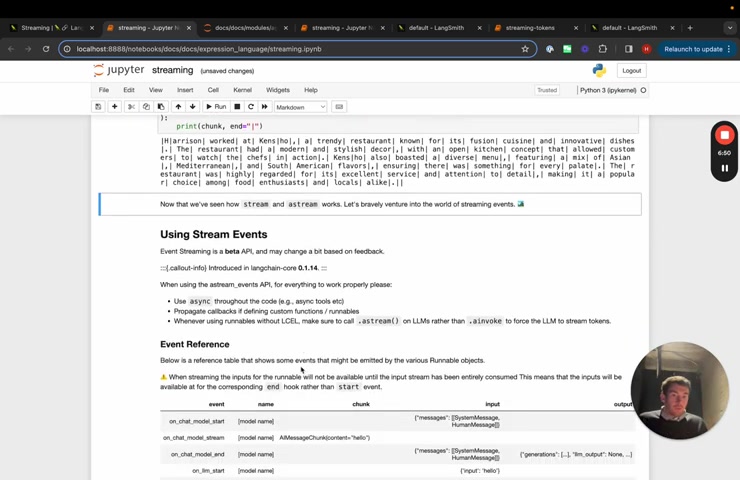
Um So basically call the retriever gets some documents , passes it to a prompt passes it to model , passes it to an out parts here , these still stream .
So we'll see that the final response we can stream .
All right .
So those are covering kind of like the basics of stream and a stream .
The , the big uh kind of like limitation of these is that it only streams , the final kind of like output of a of a chain oftentimes we might want to stream the the intermediate steps or the events that happen within the chain along the way .
So we'll walk through this new method um stream events .
Um And the events that it produces are , are aligned with the callback handlers that we have .
And so we have a bunch of different types here that we've listed here .
Um So we kind of like have uh uh so this is for chat models and LL MS very similar .
We , we yield something on the start .
We , we yield something on the end and then on stream , we also yield each token if the model supports streaming , same for LL MS , um same for chains , same for tools , same for retrievers and then same for prompts .
Prompts just has start and end .
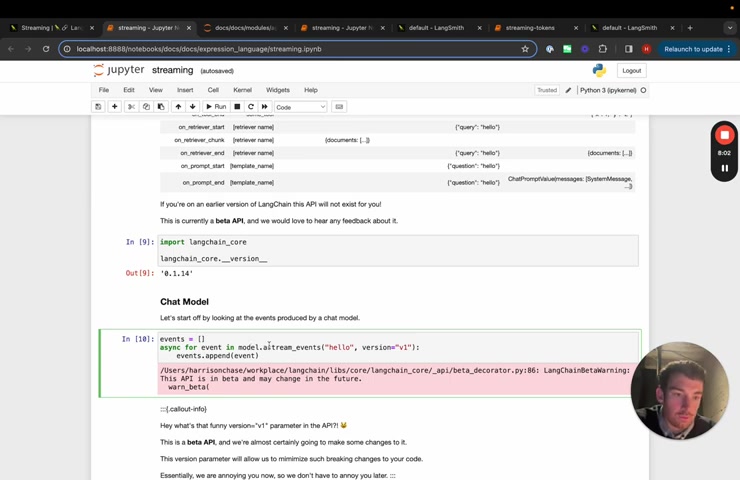
Um One thing to note is that this is a beta API um and would love to hear any feedback about it .
So please let us know .
So here we can start , we can use the , the , we can just use the model and we can , we can call a simple model and we can take a look at the stream events that are associated with this model .
One thing that you may notice is this version thing in a stream events .
So what is this uh basically we're documenting kind of like the API for this a stream events um interface .
As mentioned , it's a beta interface , it may change .
So we want to uh make it , make it easier to do that in the future .
Let's take a look at what some of these events are .
So we can see that the first one is on chat model start .
So it starts kind of like the the streaming , the first event , it hits the chat model start and then it's chat model stream , chat model stream .
So basically what's happening is the inputs going in , it's starting the chat model .
And then after that , it's getting token by token , if we look at the last results , we can see that it's on chat model stream and then on chat model end .
So this is a very simple single call to a chat model that first calls the event on chat model start , then calls stream on each token and then calls on chat model end at the end .
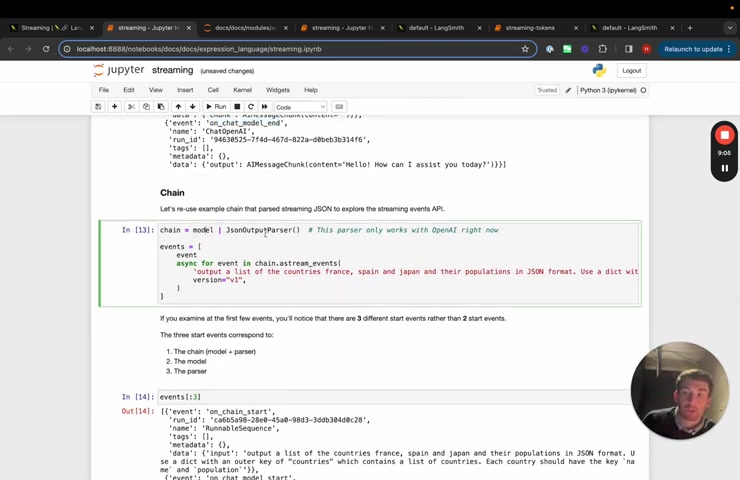
Let's take a look at the chain that we have .
So now we have this model and we have this JSON outer parser .
Let's gather the list of events and we can explore them this way .
So the first three events that we see are actually all on blank start .
So first we have on chain start because we enter the overall chain here .
Then we have on chat model start because that's the first one .
But then the model streams things through .
So it passes a generator through , it passes that generator through right away to the output parser .
And so we immediately hit kind of like on parser start , we can explore this a little bit more by looking at the , at , by looking at some different events .
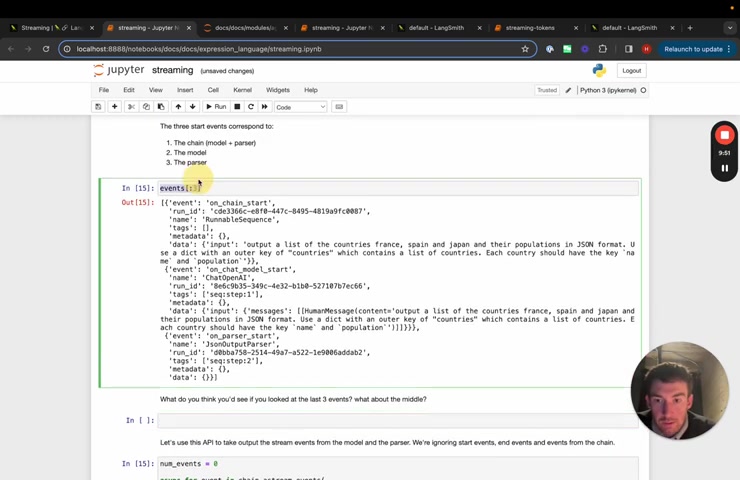
So let's look at maybe like the last three events in here .
We can see that we have Allen chat model end on parser end and then on chain end .
Um So this is this , this makes sense .
It's uh you know , if we imagine kind of like the the sequence of of chain encapsulating a model and then a parser , basically the model will kind of like finish , then the parser will finish and then the chain will finish .
Let's look at maybe some of the middle ones .
So if we look at like 3 to 6 , we can see that what happens , maybe let's do 3 to 7 for just a slightly nicer thing .
Um We can see that it's a mingling of of on chat model stream on parser stream on chat model stream .
Um Sorry on chat model stream on parser stream on chain stream .
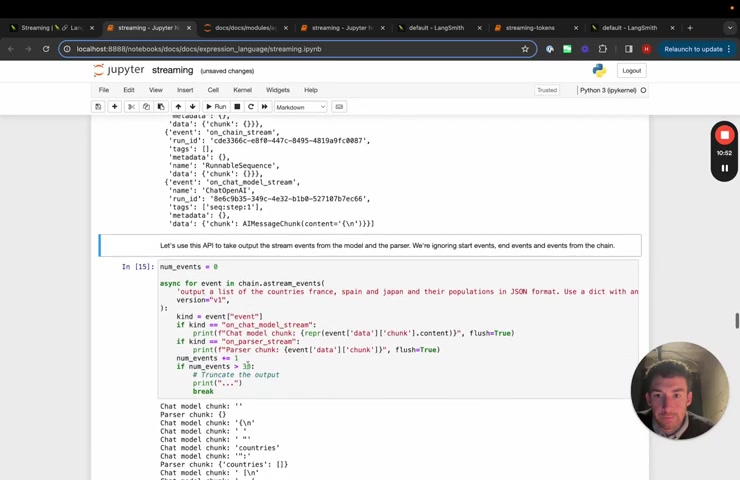
So what's happening is as the chunks occur because we stream them all the way through , we first see one token come out of the chat model that gets passed through to the parser that gets passed through to the end of the chain .
And so it's the sequence of events .
So now we can take a look at using these real time to do some streaming .
So we will do this by parsing the event , the the the events that get emitted by the stream events .
So first we'll take a look at each event and we'll take a look at what the kind of the event is .
Then we can basically do things depending on what the kind is .
And we'll just do some simple string matching based on the name .
So if the chat , if it's on chat model stream , this is when it's printing out a token , we'll pa we , we'll print this chat model chunk and then if it's on parser stream , this is when it's uh going through the output parser , we will pass that and we'll set flush equals true .
This will get rid of some of the flushing issues that I had above .
And yeah , we'll , we'll just only do this for the 1st 30 .
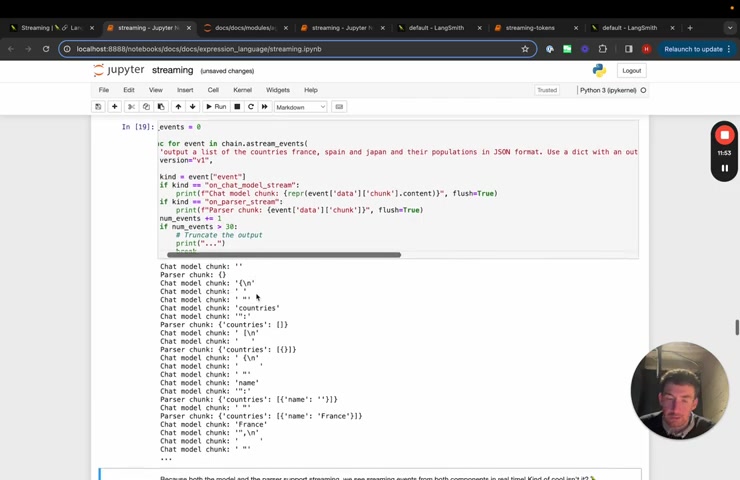
So you can see now that we start printing things out and it's intermingled with chat model and parser because basically the chat model starts accumulating tokens and at some point then the parser emits something .
Um But , but they start streaming kind of like at the same time , there might often be a lot of different events coming out from your chains when you have complicated ones with more types of models , um different types of tools , sub chains , things like that .
And so we want to make it really easy to basically um filter uh these events .
We have a few ways of doing that .
One is by name , so you can assign any run .
So again , a run is just a model or a prompt or a chain or an output parser , you can assign it with a run name and then you can filter um the events by include names .
So here we give uh the model , the run name model , the output parser , the run name , my parser , we have include names only my parser .
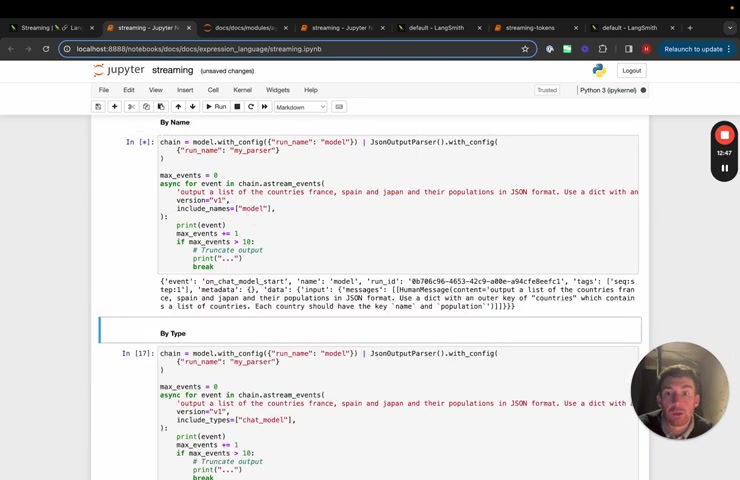
And then if we print out events , we will only get events related to the output parser because we're filtering out the ones with the run name model .
If we switch it up , we go model , then we only get ones associated with the model another way to filter by type .
So we have the same chain here .
Um But we're just going to uh change include types .
And so now include types , we're going to set next to chat model .
This will get all chat models .
So if you want to get all chat models , regardless of the name that you give them , um you can , you can get them this way , tags are another way to do it , tags are basically inherited from any child component .
So here we're gonna give this whole chain the tags , my chain and then we're going to stream all events and include tags , my chain , my chain .
So the way that tags work , it's not just events associated with this chain , it's with any sub child components as well .
So if we stream it out , we see that we start to get everything we get chain .
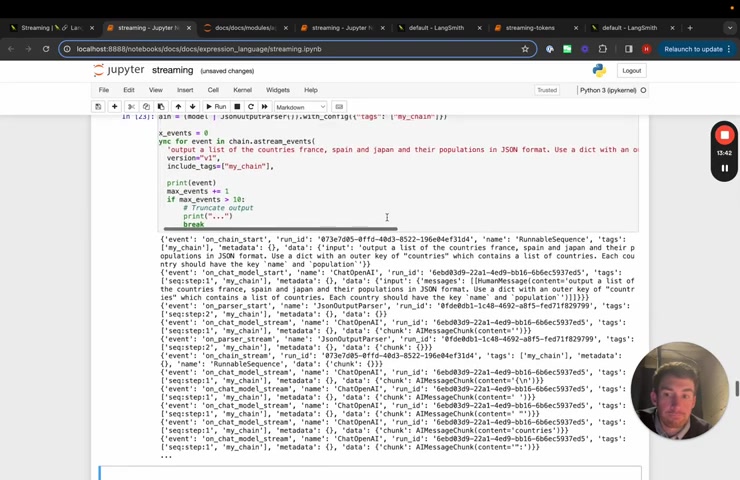
Um We get on chain , start on chat model , start on pars of start in this case because we tagged the whole chain with my chain .
This is everything .
If we take a look at non streaming components again , we can see that .
So this is the , this is the one that blocks the final result .
Um doesn't stream .
If we look at a stream again , we this is the same example as above .
It doesn't stream .
But if we do stream events , it does .
And because that's they get passed through up until that point .
So we can see kind of like everything going on .
Another thing .
This is a slightly more advanced one is basically if you have um if you have basically custom tools and they have inside them a run , um then what you want to do is you want to propagate the call back .
So that otherwise no stream events will be generated .
A common example of this is if you have a tool for an agent and that tool calls an LLM , you need to make sure to propagate the , the callbacks correctly .
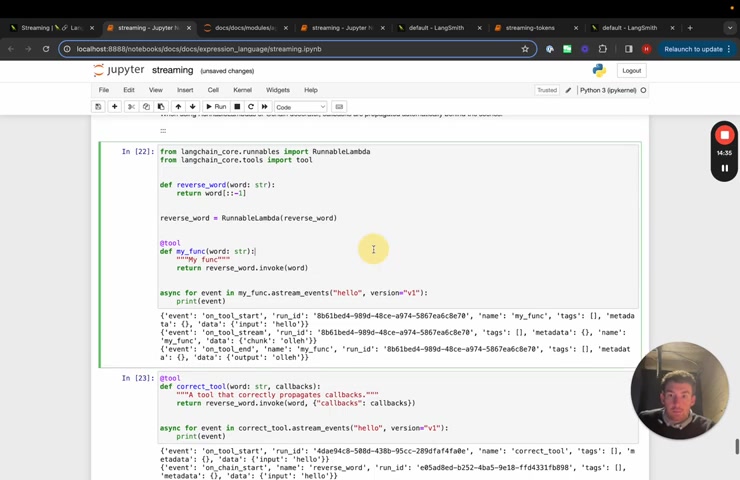
Um So here is an example of it not propagating correctly .
Um And so you can see that there is basically just the stuff for tools because even though it calls this run inside of the tool , the callbacks aren't propagated .
So it doesn't actually know that exists if we now propagate them .
And you can do that by just adding in callbacks as an argument to this tool function .
Um And then passing it in through callbacks here .
Um You can see now that we get this on chain start and on chain end event and these occur in the middle .
And so these are , I think more examples of just the same .
All right .
So that covers basic streaming stuff .
We get most of the questions around streaming around agents .
And so I want to show two examples of doing that .
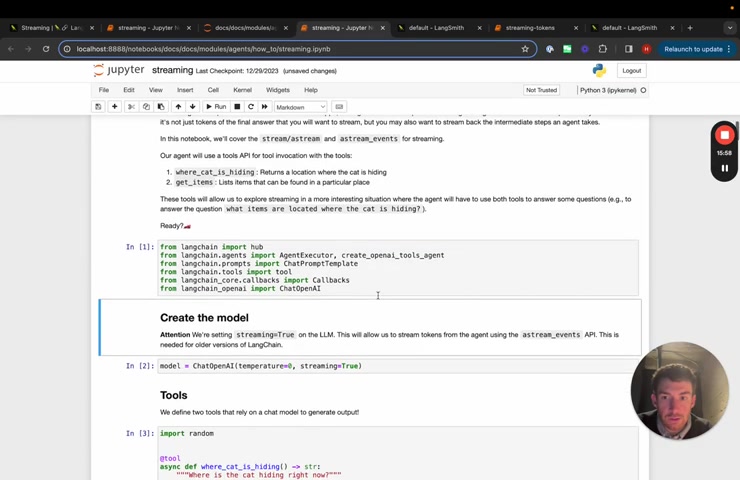
So this is the streaming page in the lane chain documentation that shows how to stream with the agent executor .
So let's restart the kernel .
So we can see what's going on here if you haven't , if you don't know what agents are , check them out in a separate video , I'll link to one in the description basically with agents .
The first thing we're going to do is we're going to define a model and we're gonna make sure that streaming set equal to true .
This is so that it's , this is necessary so that it , it streams no matter where it's called from .
So in an agent , it will be called within the agent many times .
So we set streaming equals to true .
Um And , and then we define our tools .
Um And so these are just two example tools um we can play around with them and then we initialize the agent .
And so here we can see that we are going to first pull a prompt and we're gonna use this prompt for agent .
We're then gonna list out the tools we're then gonna create the open a , a tools agent .
And we're gonna give the model here a tag agent LLM .
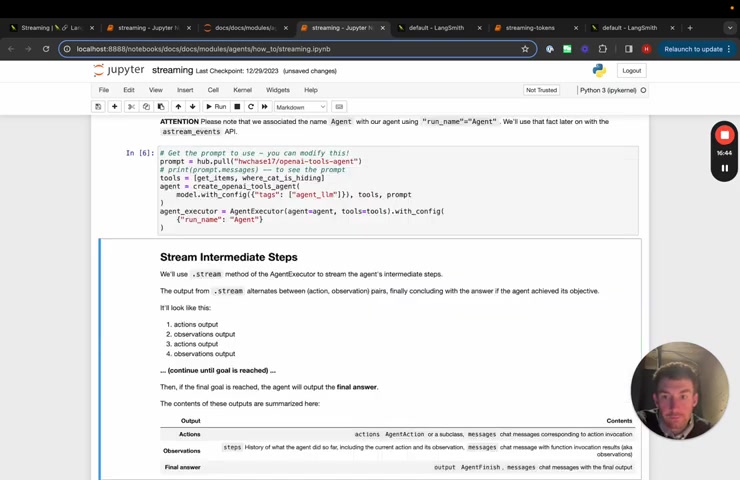
And then we're going to create the agent executor .
This is the run time for the agent .
Um And we're gonna give it run name , agent , this covers streaming .
So this is the streaming of the agent , the streaming of the agent does the individual steps .
So that's nice .
But oftentimes we wanna get the individual tokens as well .
So let's stream , let's go down to custom streaming with events .
So here we can do the same thing that we had before .
So we have the input , we'll use version one , we're using a stream events and now we can start doing stuff with the uh the events that are emitted .
So if on chain start and if the event name was agent , so this is basically this is if you remember back up here , we tagged the agent executor with the run name agent .
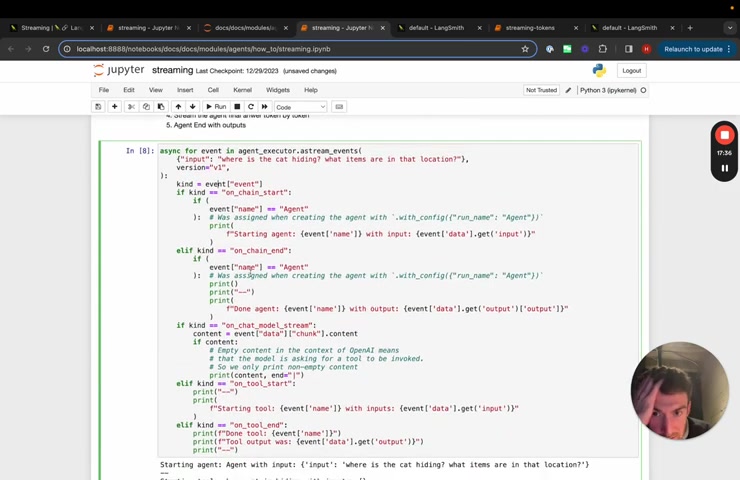
So this is basically saying whenever on , on the start and end of this , we are going to print out this and then same thing on the end of this , we're going to print out this and this is needed because there's a lot of sub chains within this agent .
Um There's places where we kind of like do the prompt into the model .
Um Those are sub chains , we really care about this overall agent and then we care about the streaming of the tokens from the chat model .
So we are going to uh basically , if it's on chat model stream and if the content is exists .
And so there's actually cases where the content doesn't exist .
And this is when tools may be called , we can , we can play around with this and see what that looks like after .
But for now , only if there's content , we're going to stream that and then we'll also stream the tool start and tool end .
So if we do this , we can see that starts printing things out , you can see that it really quickly streamed that .
Um and it gets that .
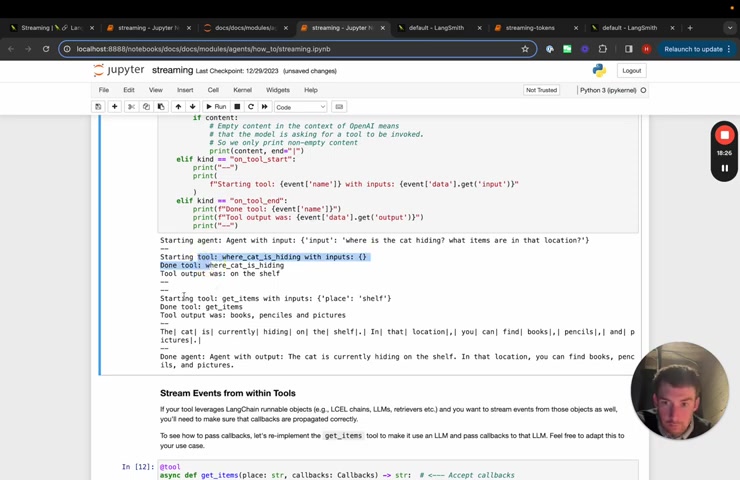
So if we take a closer look , we can see that it prints out starting agent , we then get a bunch of information about the tool um tool one , tool two and then it starts uh streaming the final response , we can also change this so that it always prints out the content .
And so now what we'll see .
Yeah , so we'll see here .
So these things are when it actually .
So OK , so this is when the content didn't exist , we can maybe even just print out what exactly it was .
Yeah .
Here we can see that it prints out the whole chunk and so we can see that the tool calls um and , and it's still streaming kind of like stuff um which is why it looks incomplete .
Basically , this is printing out the um individual chunks which have the chunks of the tool call in it .
So there's no content but there's the chunks of the tool call .
And that's what we're printing out here that covers streaming with agent executor .
There's one more thing I want to go over which is streaming with Ling graph .
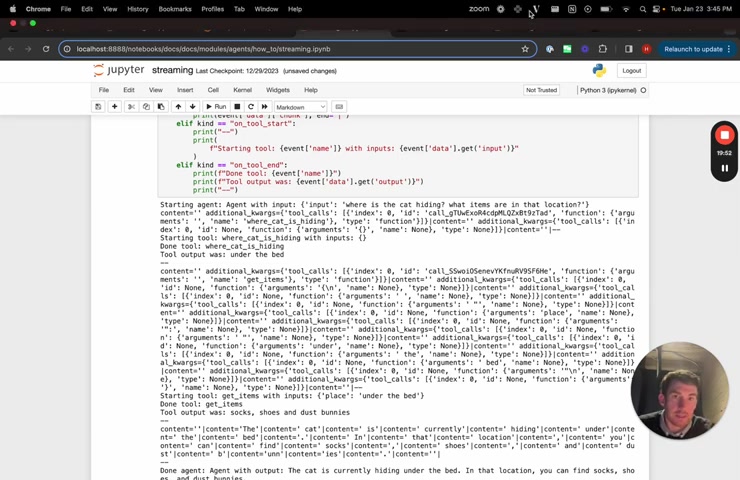
Ling graph is a package that we introduced that makes it really easy to create uh agent runtime as graphs and or state machines essentially the same thing .
And so because lay graph is built on top of L chain and is uh uh run at the end of the day , it has this exact same interface .
So if we go over to Ling graph , we can see an example of this .
Um let's also restart the kernel here .
We can create our tools , we can create our tool executor which just runs tools we can create the model .
Again , we set streaming equals to true .
Um For for chat , open A I .
Um we bind the functions of the model so it knows which tool it has available .
We're now creating the nodes in line graphs .
If you aren't familiar with this , I'll also link to a video for land graph .
So you should check that out .
We just did a whole series of them on , on youtube , we define a bunch of our nodes here .
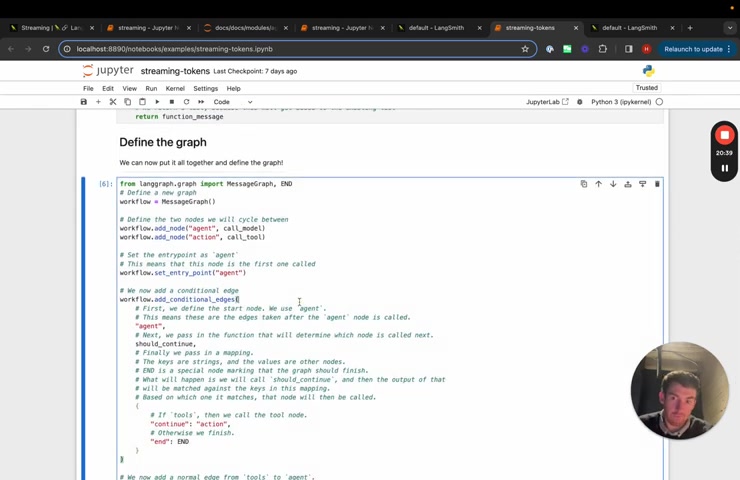
Um Again , we'll cover this in a video separately or it's , it's already been covered in a separate video .
We define our graph here .
Um And then this app that we get back , this is a run ball like any other thing that's constructed with lang chain expression language .
So we can start taking a look at it and uh uh using it in the same way .
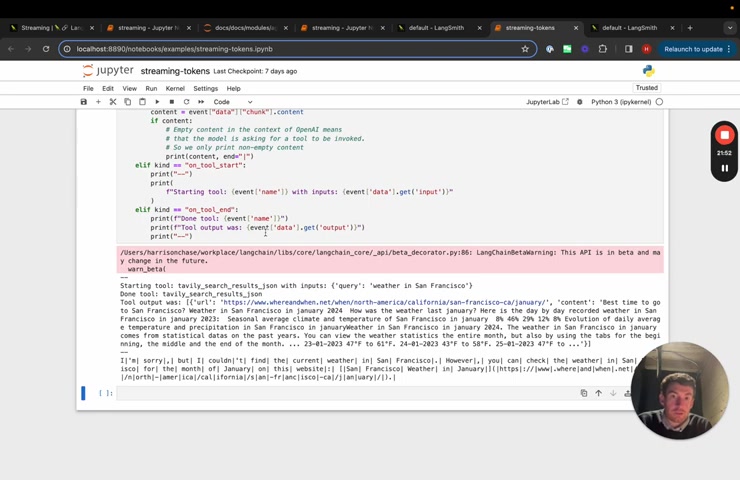
So we'll use a stream events .
We'll , we'll look at the type of the event if it's a chat model stream .
So if it is a uh token , basically we'll do the same thing where we print it out if it's not empty .
Um And then we also print out the on tool start and the on tool end .
So we'll , we'll run this with the inputs .
What is the weather in sf we can see that we get back or it's logged the , the starting input for the tool , we get the output and it starts streaming back the response of the tokens there .
That's basically all I wanted to cover in this video streaming is super important to LLM applications .
And so hopefully , this new stream event method will make it really easy to stream back what is going on inside your applications to the end user .
Again , this is in beta .
So please let us know if you have any feedback or questions .
Thank you .
Original video
Partnership
Are you looking for a way to reach a wider audience and get more views on your videos?
Our innovative video to text transcribing service can help you do just that.
We provide accurate transcriptions of your videos along with visual content that will help you attract new viewers and keep them engaged. Plus, our data analytics and ad campaign tools can help you monetize your content and maximize your revenue.
Let's partner up and take your video content to the next level!
Contact us today to learn more.