https://www.youtube.com/watch?v=Lsn_OR9Fr3s
2023-06-14 17:56:08
10. Voice Cloning, Eleven Labs API, OpenAI Embeddings, ChatGPT API, Whisper API

So I've been , I wanted to ask uh I felt a little bit unsafe with my uh money recently with all the events happening .
So um is my money safe ?
Should I be putting it in a money market account ?
I understand that recent events can make you feel uneasy about the safety of your money .
However , there are many safe and easy ways to manage your cash such as online savings accounts , T bills , cds and more .
It's understandable to worry , but it's important to remember that the financial system is built on faith and it's not in the system's interest to let people's assets disappear .
Hey , everyone , welcome back in today's video .
We're going to continue the series on open A I by building upon the previous two tutorials .
So in video eight of the series , we created a financial advisor Q and A that was able to query a corpus of text to find the answers to your commonly asked questions .
And this corpus of text was built upon transcriptions of the podcast portfolio rescue .

Now we're going to take that concept of a financial advisor Q and A and combine that with my previous video where I had sort of a financial therapist where I was able to talk to it and have it respond to me with its voice .
And the voice was based upon a text to speech that's built into Mac Os X .
Now , I received a variety of comments that , uh the text to speech in Os X was a little bit robotic , not quite natural .
And so what I wanted to do is figure out can I add a little bit of personality to this ?
And this idea of a personal assistant that's actually intelligent is kind of taken off right now because , you know , we all tried Alexa and while it was kind of neat , ultimately , it seemed kind of dumb , right ?
But uh with all these natural language models and advancements that are happening , uh week after week , you got to wonder , you know , are these things actually gonna get smart enough and will they be someday convincing enough to where you almost feel a connection to it ?
And if you watch the movie her about 10 years ago or so , uh you remember the lead character actually sort of fell in love with his uh personal uh voice assistant .
So basically in every moment I'm evolving just like you really weird .
Is that weird ?
Do you think I'm weird ?
Kind of why ?
Well , you seem like a person but you're just a voice in the computer .
I can understand how the limited perspective of an artificial mind would perceive it that way , you'll get used to it .
So , having watched the movie her , how would I go about building something like this ?
How would I try to add a little bit more personality to my voice assistant ?
So , um what we can do is take different voice samples and create different , different personalities and have it speak in different ways using the same corpus of text and to demonstrate this , what I've done here is take samples of this exact movie sequence in her , right ?
And I took Scarlett Johansson's voice and trained an image on Scarlett Johansson .
And so right here , you can see where I've just chopped it up to only have the voice samples of Scarlett Johansson .
So how can I help you ?
Do you mind if I look through your hard drive ?
OK .
Let's start with your emails .
You have several 1000 emails regarding L A weekly , but it looks like you haven't worked there in many years .
Yeah , there are some funny ones , I'd say there are about 86 that we should say we can delete the rest .
OK ?
Can we move forward ?
OK .
So before we address your organizational methods and so let's talk to Samantha now and see what she sounds like .
All right , so I got uh Samantha loaded up right here .
So we're gonna have another financial advisor session with just a different voice but the same uh knowledge base .
So just a different persona here .
So let's see how this goes .
Hey , Samantha .
You seen any good movies lately ?
Yeah , I just saw Scream Six and I had a good time .
The theaters were packed , which is a great sign that we're getting back to normal .
As for TV , shows , succession is coming back soon .
And Yellow Jackets is one of my favorites .
If you're interested in financial history .
I recommend Panic of 19 oh Seven and The Good Life , which is a study on happiness .
So , what do you think ?
Pretty cool , right .
It's not perfect , but it's actually pretty impressive if you've never played around with any of this voice cloning technology .
And so I know we want to get to the coding on how to actually train this thing and talk about how to build this .
But I want to demonstrate one more personality that not only has a different voice but has a totally different style of speaking .
And so I made a persona in the style of Jay Z .
And so this one is going to use the same Corporates of knowledge and not only use a different voice but also answer with rhymes , right ?
So I want uh my answer in the form of rhyme and it , and it will portray the exact concept as a freestyle rap , right ?
All right .
So I have Jay Z loaded up right now .
So let's ask him some similar questions .
Hey , Jay , what you been up to lately managing wealth with style and flair Jay Z is in the house cause I'm a financial billionaire .
That's right man .
Sounds like you had a good weekend .
So uh I've been meaning to ask you a question .
So let's say I am a billionaire like you once I get there , I'm gonna get there someday .

So um should I be putting my money in a bunch of different accounts just to make sure it's safe ?
I've been worried , worried with all these bank failures that my money's not safe .
Let me break it down in a smooth flow .
You're worried about bank failures feeling low .
But let me tell you , friend FDIC S got your back up to dollar 250 K .
They won't let your wealth crack as for brokerages not to conflate the two S ECs got our back with rules that ensue .
And so where did I get the samples ?
Used to train the Jay Z voice clone ?
Well , right here he blows on the big face .
I've got two of those and the reason I bring this up is because there's been many objections to uh taking these voices and things , art , things from other places , text and what people are talking about and combining them into a new form .
A lot of people are saying , uh that's plagiarism .
You're stealing all our stuff .
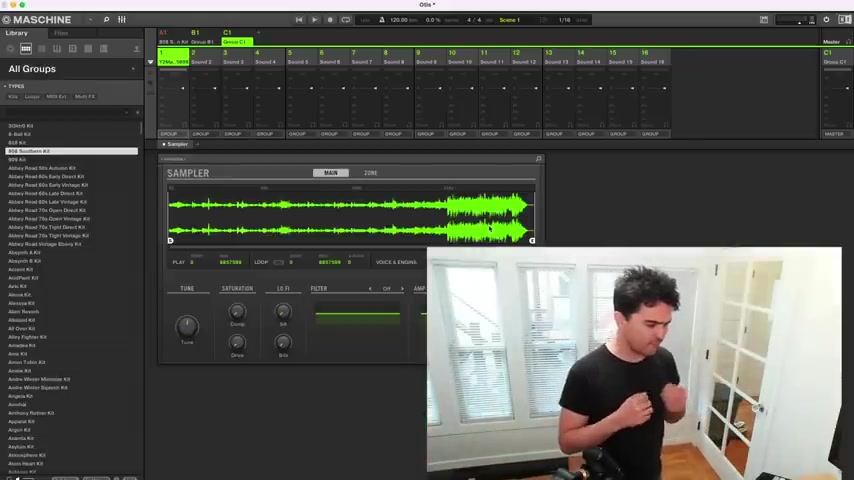
And I think there's some good points there , but also , uh think about something like hip hop music , which I'm a big fan and some of you have seen where I have a machine studio , our machine M K three here , uh which is a beat making machine .
And so when you think about the song Otis itself , it's actually based on a sample um from Otis Redding .
And so what I can do is take the original song just like Kanye West did and chop that up .
So here on my screen , uh you see , I have my sampler loaded and you can see here , I have it chopped up and so the original song is mapped to these pads .
Right .
Right .
And so what a hip hop producer does is take these samples from other sources and remix it in a new way .
Do you play instruments ?
Barely ?
Do you know how to work a soundboard ?
No , I have no technical ability and I know nothing about music .
You must know something .
Well , I know what I like and what I don't like and I'm , I'm decisive about what I like and what I don't like .
So what are you being paid for ?
The confidence that I have in my taste and my ability to express what I feel has proven helpful for artists .
And so what's happening with all of us now is that we can all essentially get , take all these samples from all these different sources and put them together in a new form using our own uh creativity and come up with a whole different form that might mean something to someone else might make a , a connection in a totally different way than the original artist or author has intended because I'm young and I'm black and my head is real low .
Do I look like a beer ?
I don't know .
Yeah , I'm thinking maybe we start a cappella with , um , if you're having girl problems , I feel bad for your son .

I got 99 problems but a bitch ain't wanna hit me right into the , the patrol .
Yeah , that's , that's money back in the game , right ?
So apparently , so you all these records , I used to listen to these guys are the creators of it , the architects of what we do right now .
And so in a way , all of us are reacting to all the inputs that have come into our brain and output it in some different format and we can debate this kind of stuff forever .
But you know , it's here and you can't really stop it .
So that was a very long demo and a lot of commentary uh a lot more than usual .
Um Usually I'm just talking about coding this stuff , but I'm , I'm talking through all this stuff and my reaction to it as it unfolds , the stuff is moving very quickly and I kind of make stuff with it and then share it .
So um talking it through with you .
Um And so , yeah , that's what I do on this channel .
And so all of these concepts build on each other .
So this has been a nine part series so far .
So this project , the main concepts are covered in video .
Number five , open A I embeddings API video number eight , the financial advisor , embeddings and question answering and video number nine , where you use the chat GP T API and the whisper API along with radio user interfaces .
So those three and so what would be best ?
I know a lot of people don't do this .
They just want a quick five minute thing .
But if you really want to understand at the lowest level , you want to watch this embeddings video and question answering .
And so this is like over an hour of free content here and free code .
And so I'm gonna go over each of these concepts that I used and the code that was used to write uh this project and that might inspire you to uh watch the rest of these and uh build all of this yourself .
And so the first thing we wanted was a knowledge base .
And so I showed you how to do this in video number eight , building a financial advisor .
And so what I did was use open A I whisper here and we walked through how to actually transcribe a youtube video .
And so we downloaded all these different youtube videos , we transcribed them , dumped all the text to a bunch of different files , right ?
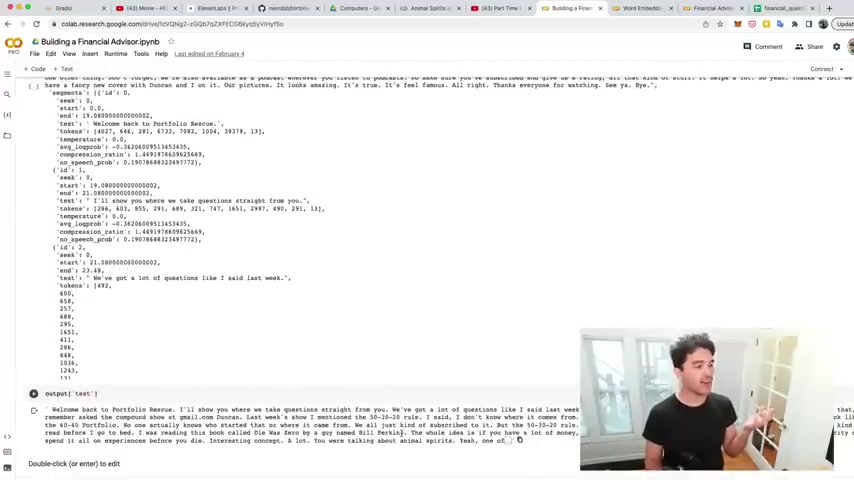
And so you can just transcribe a youtube video to get your corpus of text .
And if you walk through this cola notebook that I shared , you'll already know how to create this uh knowledge base and you'll end up with a nice uh spreadsheet .
And so once you're able to extract the questions and answers from your data source , or , you know , you could just manually create your own question answer , data set right here .
You'll just have a nice spreadsheet with column A with the questions and column B with the answers .
And so what I'm gonna do here is show you how to load this data set in .
So I'm just going to use a smaller data set here .
I'm gonna load this into Google Colab .
So I'll share this notebook with you and you can open it up and you can try this stuff out yourself .
And so what you can do with Google Colab , you can open this file system and you can drag in your own data set .
So I'm gonna upload this questions A CS V here temporarily .
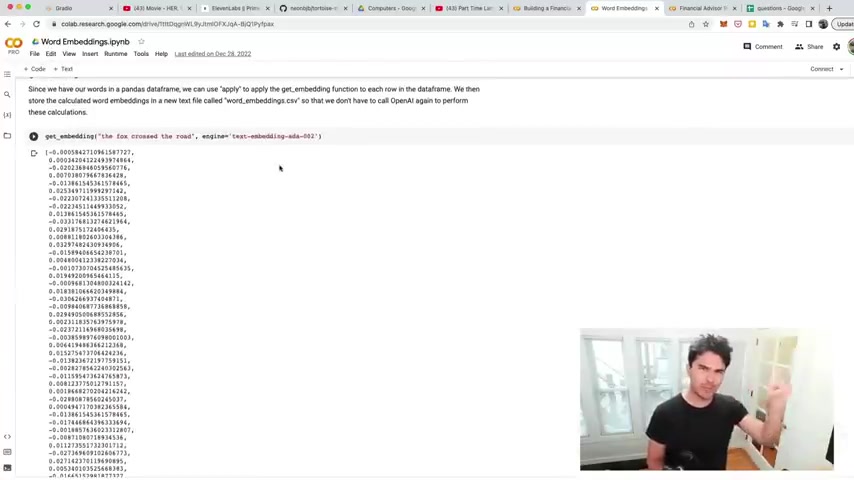
And so once we've uploaded this CS V file , we just need to write the Python code to calculate word embeddings , which is what I discussed in video five of the series that explains this concept in great detail , best video on youtube on the topic if you ask me .
So what we do is calculate this vector or numerical representation of our words and phrases .
And so I uploaded these questions and so now what I want to do is circulate these vectors that , that represent these questions and answers that were , were asked .
So to do that , we first need to import the Python open A I package .
So I'm going to do pip install open A I and that's gonna install it and add it to my uh COLAB environment .
You can also do this on your local machine , but for ease of sharing it online , I've written the code in a notebook so that you can execute it and not have to set up your environment yourself for this particular part of the exercise .
So I installed open A I and then I also am going to import some common libraries .
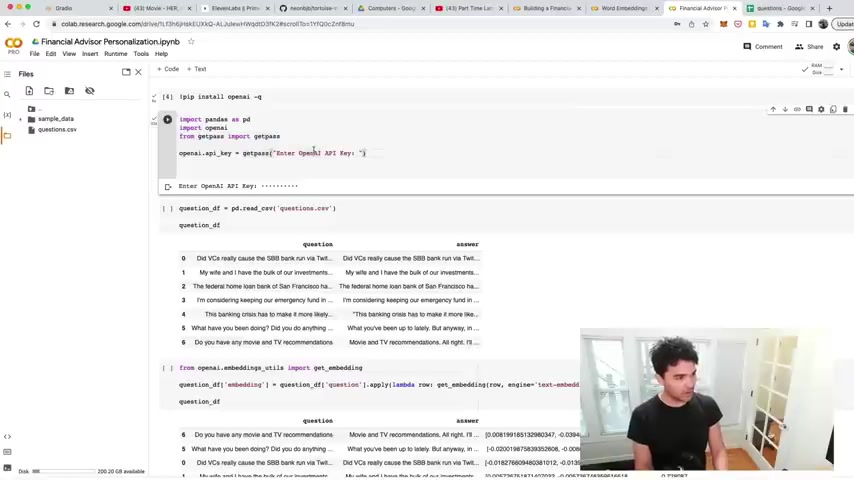
So we're going to need pandas to manipulate data frames .
We're going to import the open a library .
And I also have this get pass that accepts my open A I API key .
And if you've been watching this series , you already know about API keys and how to get your open A I API key .
So I'm gonna enter in mine right there and it's entered .
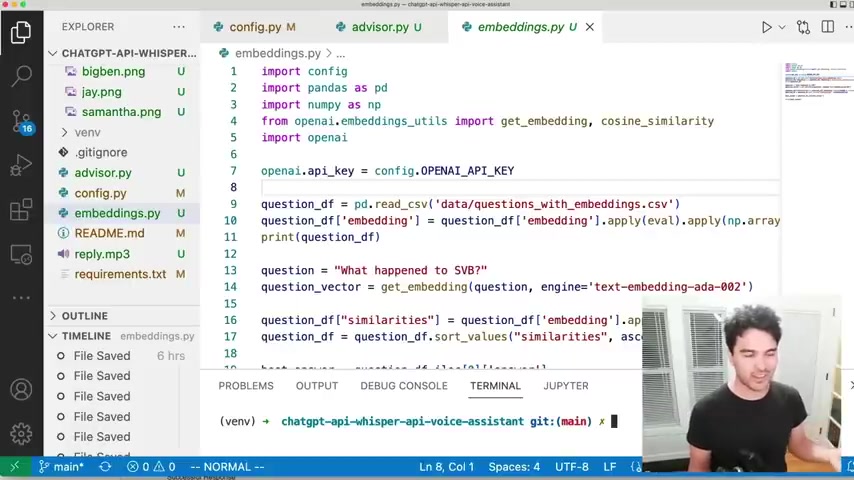
And so now what I'm gonna do is use pandas , which we imported as P D and I'm gonna read a CV file .
So I'm gonna read this question , CS V file and run this and we should have a questions , data frame and look at that .
So I have a question .
Did V CS cause the S V B bank run via Twitter uh a question about uh their wife's husband , wife's investments , the Loan Bank of San Francisco .
And I have in general , what you been doing lately ?
And do you have any movie and uh TV , recommendations ?
So I have a variety of questions and answers .
This is simplified one .
I in the uh previous financial advisor video .
I , I actually talked about how you could transcribe all of them and I have a list of all the episodes and I'll actually put all the transcripts online .
So if you want a giant database , I have all those transcripts available uh for both this podcast and animal spirits .
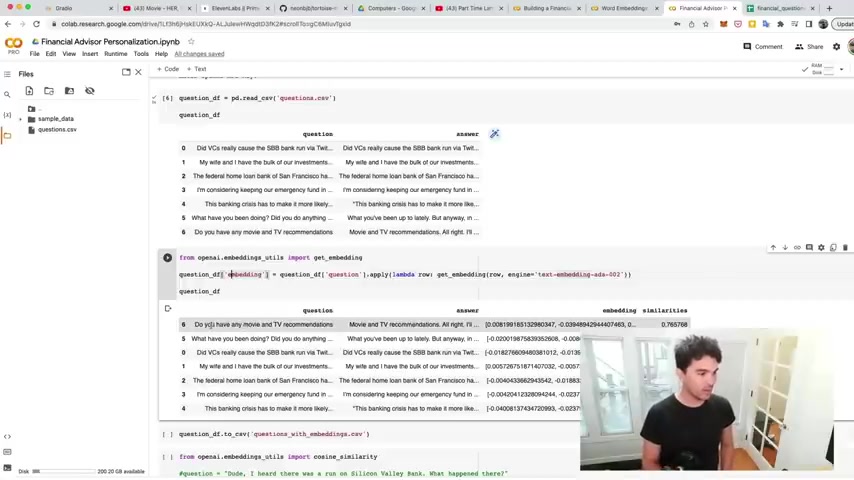
So now that we have our questions and answers in a panda's data frame , we just need to calculate these word vectors here .
And so what you do here is you import uh the open A I uh get embedding function .
So we import it there .
And then what we do is create a new column called embedding that's gonna store these uh right .
And then , so I say applause .
I uh this word embedding to the question .
So my question is , do you have any movie and TV recommendations ?
I apply this function , get embedding using the text embedding A 002 model .
And so this is a cheap model .
It makes it very cheap to calculate word embeddings , right ?
And we talked about this in video five already .
And so for each row we're applying uh this get embedding function to the question and storing the result in a column called embedding right there just like that .
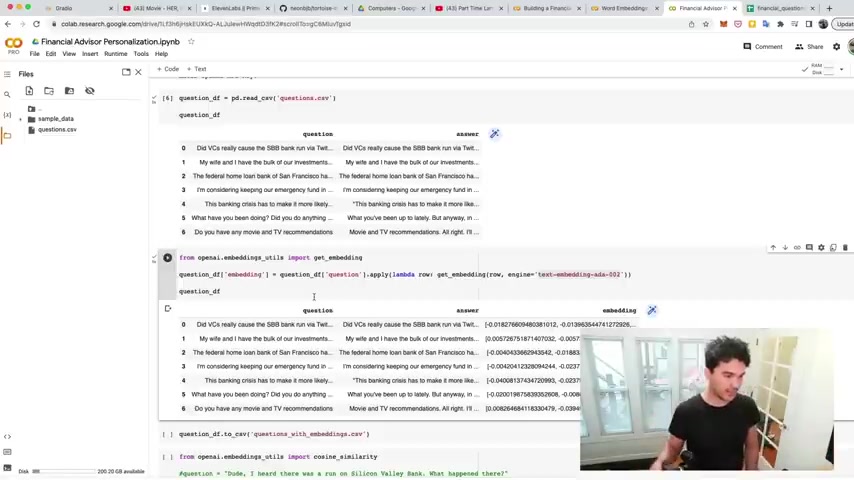
So I run that and you should see in a moment that for each one of these questions , the answers we now have an embedding .
So cool , we have a numerical representation of these questions .
Great .
And so now , so that I don't have to store this .
Uh I don't have to run this again because this actually cost a penny or so less than a penny for this many questions .
Uh I save it with the embeddings to a CS V file .
And so I can save it right there .
And then , so now look , I have a CS V file that's a copy of the questions and answers and embedding .
And then I can use that in my user interface in a moment .
So I can use those embeddings .
I have to calculate .
OK .
So I save that now to demonstrate what we're gonna do here , we're gonna be adding this code to our uh user interface in a moment .
But just to show conceptually what we're doing here , we're inputting this function called cosine similarity .
And in the uh word embeddings video , I created , we talked about cosine similarity and how it allows us to measure the distance between two different points in a vector space , right ?
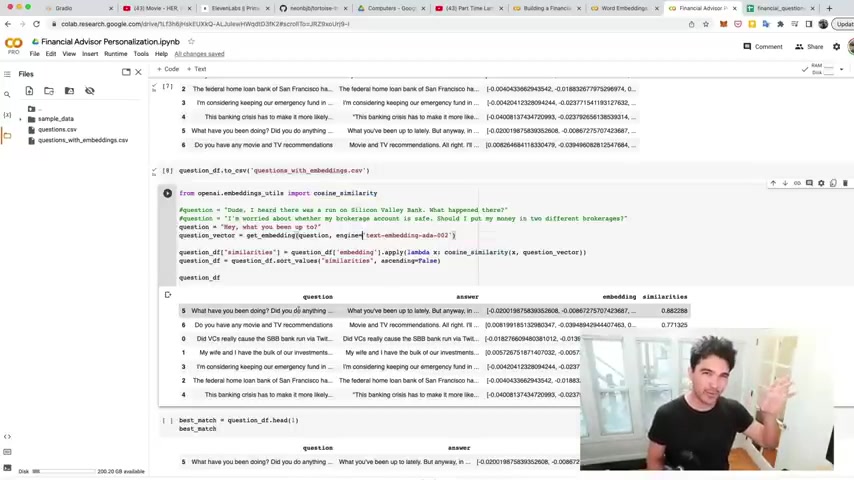
And so this embeddings uh concept allows us to take words that are spoken in the uh in the human language and convert it to a numerical representation that lives in this vector space .
And what we learned in our semantic search video is that uh words and phrases that are close together in this vector space are actually close together in meaning as well .
So we showed how uh milk and uh and uh cappuccino are actually very close together if you actually calculate these numbers and we can use the same concept for question answering .
So we can find uh the question .
So if I uh if I ask my own question in a , in a strange way , I can find the question here in this data set .
That's close to my question , even though I'm not saying the question exactly the same way .
So I'm able to search for the meaning of my question and see which question it's closest to , right ?
And so what I'm doing here is um I'm hard coding question just to test this out .
So I have a question .
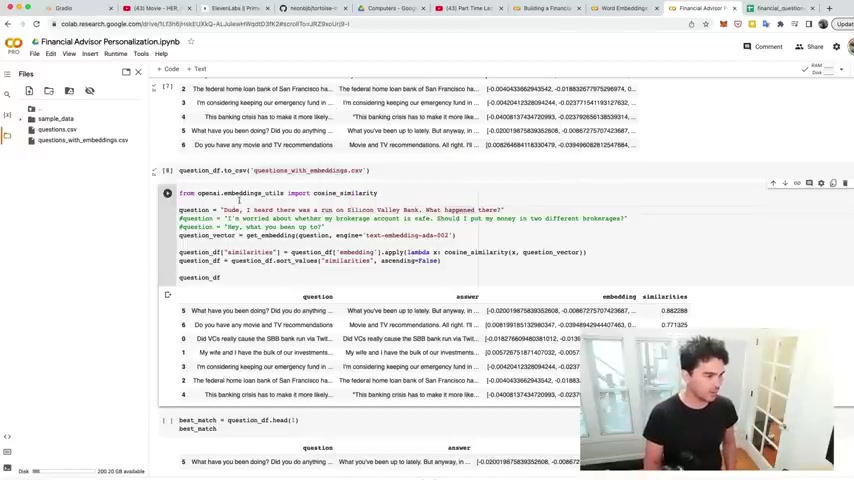
Um So let's start with a question .
Uh This question is , dude , I heard there was a run on Silicon Valley Bank .
What happened there , right ?
So that's a question I'm just putting in here later .
I'm gonna say this with my voice , but now I'm just doing it as a string .
And so what I'm gonna do is calculate the embedding for this question .
Dude , I heard there was a run on Silicon Valley Bank .
I'm gonna get the embedding and so I'm gonna use the cosine similarity function to find the question in this data set that's closest to the question about running a run on Silicon Valley Bank .
And so I'm gonna run that , I calculate the cosine similarity for all these and store it in a column called similarities .
And then I do sort values .
So I sort by the most uh similar , right ?
And so you notice when I sort the values by similarity , right ?
Uh And then I look at the top question that comes up with sure enough , it finds the appropriate question .
So it has these ranked uh and then you notice the TV and movie recommendation thing at the bottom because that's very far in meaning from the question I answered and so we can apply the same concept .
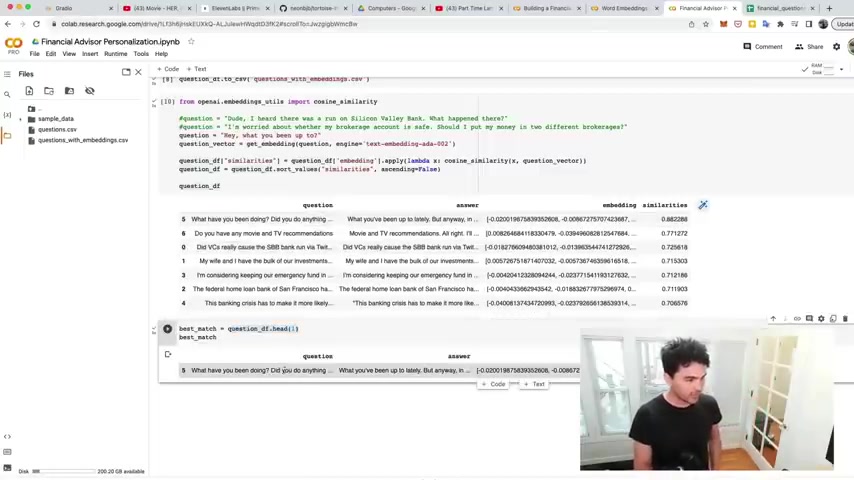
So let's pretend my question is um hey , what you been up to , if I run it this way , you'll see that the top question that it matches is uh what have you been doing ?
Did you do anything this weekend ?
So cool .
So that seems to work right there .
And then , so all I gotta do is in this case , I want the top match .
So I'm gonna say get the head .
So get the first uh row here and boom , just like that .
I have the top answer .
And so that's how it's gonna work in my voice enabled system .
This is what's gonna be happening behind the scenes .
And so what we're gonna do is take this video here um where I created this uh chat GP T API interface where I can transcribe my voice and have it spoken back to me .
Um We're gonna take this concept of cosine similarity in a knowledge database , add it to uh this demo here .
So this demo was kind of arbitrary .
I was just talking to Chad GP T with my voice uh with the API with my voice .
But now I'm gonna add a knowledge base and make it very specific to a use case so that I can talk about things in the present such as Silicon Valley Bank run , which happened , you know what a couple of weeks ago .
So uh we're injecting some additional knowledge uh in here and providing it some context to talk about and how do we know which uh context to inject ?
Well , we just get the tokens that are most relevant to our questions , right ?
And we know there's a limit on the size limit on the number of tokens that can be sent to open A I API s .
And so we need to rank here to find just the small subset of knowledge we need .
Now with the GP D four API , which I now have access to .
You can actually pass in the entire podcast transcript and not even do this stuff .
And you ask a question about that .
The problem is um we passed that many tokens like in an hour long podcast I measured it and it costs like quite a bit per question .
So you might be paying 25 cents to ask a question rather than a fraction of a cent there .
So uh that's the difference .
All right .
So that's how the text based version of the question answering is working under the hood .
Now , what about the user interface and the voice cloning ?
So let's talk about the uh user interface first and the chat GP T API which I discussed in video number nine .
So the source code to that part and the walkthrough is in that video and we're combining these concepts together .
And so if you look under repositories or in the links in the last video , you should be able to find it .
But chat G T api whisper api uh voice assistant and you can follow part time learning on github .
4700 people are following my code .
And I was very happy with this particular project because uh hundreds of people have actually starred and cloned and made their own versions of this uh assistant that I released the source code to .
So the demo is here and there's people even reported a few different issues .
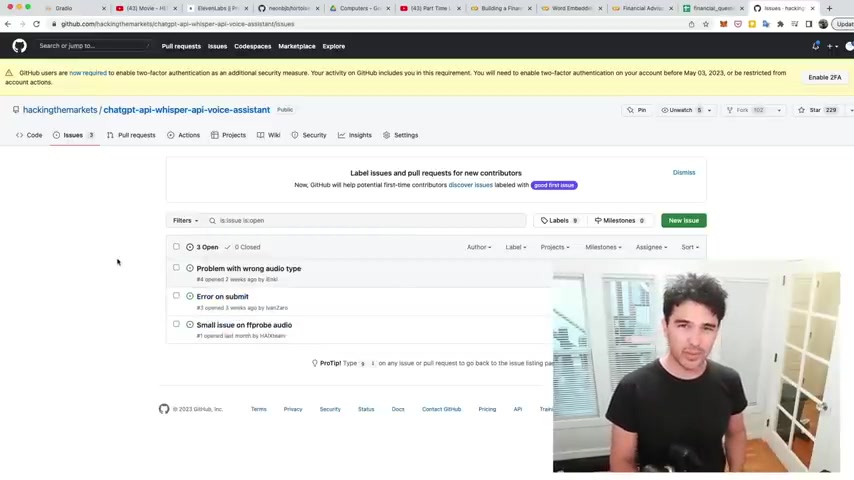
And so if you're having any trouble , uh there's actually one thing that I'm fixing and I'll talk about that in a moment and it's described in one of these issues .
Uh The most common question was um something about invalid audio format and So we'll talk about that in a second .
So we can do is copy this code or clone this code to your local machine , uh your local Python environment .
And so to make this project , I just started by cloning this .
And then I took my other concept of finding uh question answers and word embeddings and combined it with this project .
So uh I'm gonna open up what , what it looks like when I've added these new additions to it .
And so um instead of therapist dot pi , I now have advisor dot pi and I've , I'm just gonna walk you through this code line by line .
And I've already done three different code walk through of the different parts of this .
The only real new part is uh the voice cloning part and we're gonna talk about that and also the images and I'm gonna talk about how I generated those uh the those images that represented our three different personalities .
So here's the code cloned locally .
Let's talk about the changes I made to make this into a uh question answering for a financial advisor , right ?
So let me talk about all the changes I had to make .
So the first file I have is the config dot pi and I just set a few constants here .
So the first thing you need to uh I'm not gonna let you use my open A I API key .
You need to insert your own in the config file and then you see here , we have an 11 labs API key .
And so that's the secret sauce behind how we did the voice cloning here .
So 11 labs is actually a , a start and it allows you to upload different samples of and of audio files of voices and it's able to make them say whatever you want .
As you can see here , I have , I've done my own voice .
You see , I have a Cardi B , I have Jay Z , I have Samantha , which we talked about right here .
And so let's just look at what this looks like .
And so they have an interface right here where you add voice and you name that voice and you drag a bunch of samples .
So about it says don't provide more than five minutes of samples .
And I showed you , you know , you can , I'm not gonna show you how to edit audio and stuff .
That's not what this channel is about , but use whatever tools you have to chop up different samples of audio and you can upload them to an interface uh like this and create this voice and edit it and so forth .
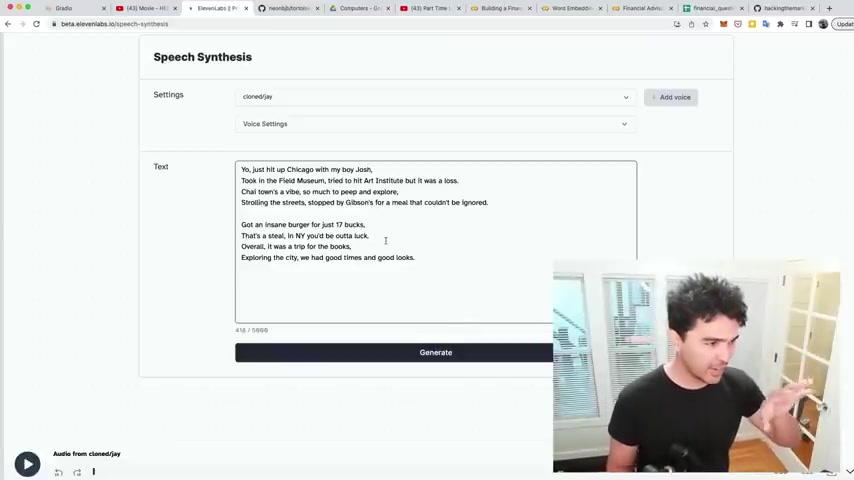
And then once you have your voice samples uploaded , you can actually click use next to it .
And yeah , so this is the output I got from uh my uh program before and I have my Jay Z voice already and you can test out what it sounds like with your voice samples .
Like this .
Yo just hit up Chicago with my boy , Josh took in the field museum tried to hit Art Institute but it was a loss .
Chi Town's a vibe so much to peep and explore stroll in the streets , stopped by Gibson's for a meal that couldn't be ignored .
Got an insane burger for just 17 bucks .
That's a steal in N Y .
You'd be out of luck .
Overall , it was a trip for the books exploring the city .
We had good times and good looks .
And so you can see how I can make it , say it whatever I want here .
So whatever I'm typing in uh this box , but we want this to be done analy generated .
And so what's cool about 11 labs is they actually have an API .
And so if I go to my profile here , you can see there's an API key and if you view that , that's your API key , you put that in the config dot pi and I'm gonna show you how to make API request to 11 labs .
So you can send it arbitrary text with a computer program and have it return an MP3 file to you .
And then you play that using our user interface and that's what facilitates the communication .
And so if you look under resources here , you need to figure out how to use the 11 labs .
API and I played around with this .
This documentation is not very good right now , but I figured out how to do it by just reading and trying things .
And so there's a text to speech API and so for each voice , what you end up with is a voice ID .
So I have a voice ID for Samantha Ben and Jay right there .
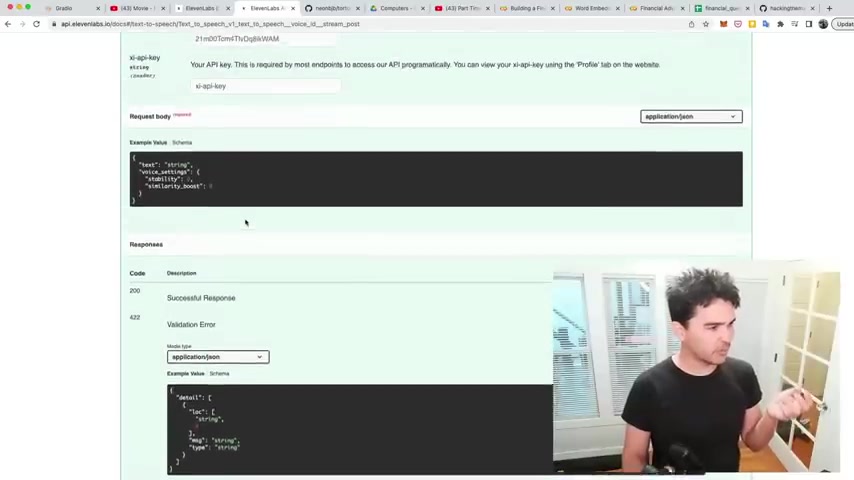
And then what I need to do is send it a specially formatted request .
And so the API request I'm actually making is this uh text to speech voice ID stream .
And so you give it a voice ID and your API key and you can give it some voice settings so you can make it sound very monotone and exactly um like the voice but very monotone way or you can make it vary the voice a lot .
So you saw a couple of times , you'll , you'll notice that my voices were kind of going a little bit wild .
So there's a little bit of randomness , which is nice , but also it can kind of go off the rails a little bit .
So you can experiment with these different settings .
But ultimately , the main gist of this and I'll show you the code .
So you need to , you need to send a specially formatted post request with the Python request library .
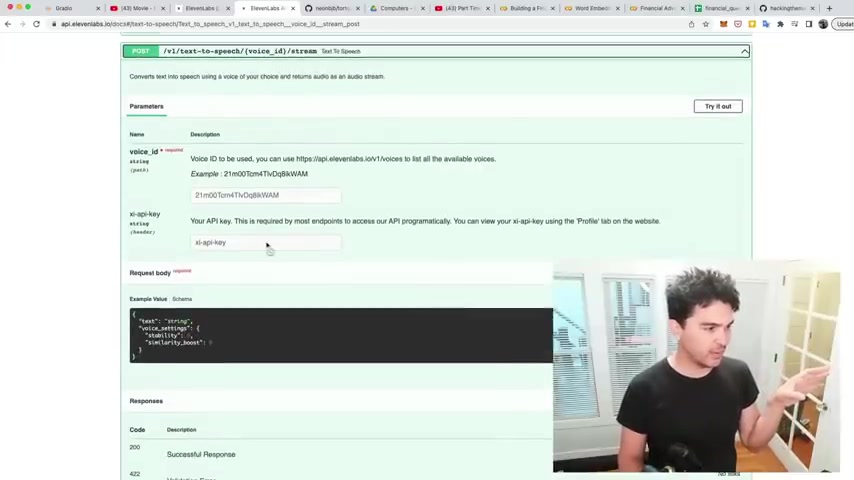
You send it some settings for the voice and the voice id and you send it some text and the string , you want it to actually say and it's going to return a response and that response is actually uh a binary response and you can write that to a file on your , your hard drive and you can actually output that also to radio uh uh to an audio interface .
And that is what let me play that response back uh in the browser to the user or on my mobile phone to the user .
Now , note 11 labs has a great technology and actually clones voices really quickly , but it's not a charity , this actual startup .
So , um there's a free plan here , but uh you probably have to pay for the starter plan if you really want to use this a lot .
And if you really go crazy with it and want to do all kinds of wild stuff , maybe you up to some creator plan and so forth .
But uh you can imagine there's going to be all types of used cases for this for like uh interview practice of uh practicing Spanish and other foreign languages .
There's gonna be a lot of use cases for this stuff .
And so I was willing to pay for this just to try it out and I'm probably gonna do some other stuff with this .
So uh it's worth it for me .
I'm investing money in all of this stuff and I don't have any affiliation with any of this stuff .
This is just the one I found uh that worked uh and was easy to set up and use and I was really impressed with .
Uh so I really like this one I was originally trying to use that resemble A I that was mentioned in the , the , the generated podcast video that I talked about in video , one of this series , it was resemble A I and yeah , screw those people because I tried to ask to use their thing and they're like , talk to our sales person .
It's gonna be $3000 for the enterprise license .
And then this one I could just sign up so 11 labs forget resemble A I .
Um So um so I have a variety of constants in here .
So these are commented out here uh but the actual active advisor I wanna use .
So for Jay Z here , Jay Z has an image that I've added to this images directory .
Uh an advisor voice ID , which comes from um from 11 lamps .
So I just specify what voice to use and then a custom prompt .
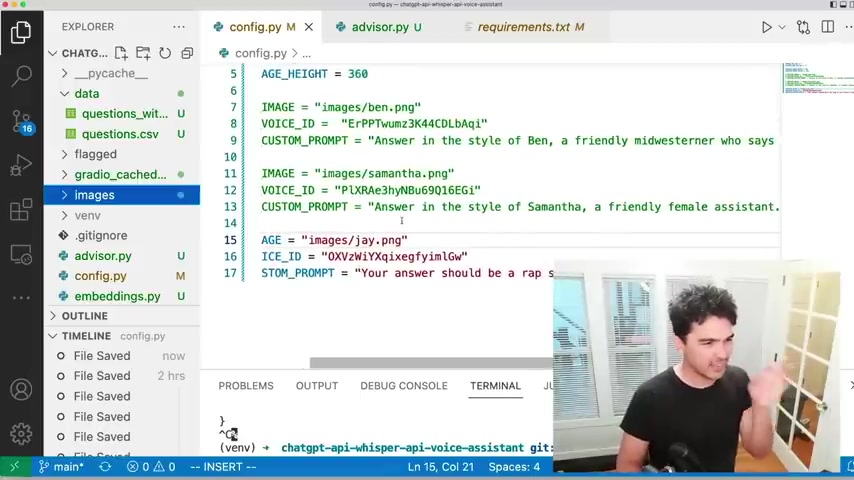
And so I'm adding for each personality .
I'm adding a little bit of extra uh information on the prompt .
So I'm gonna say your answer should be a rap song in the style of Jay Z .
Uh For Samantha , I said , friendly female assistant uh for Ben , I said a friendly miss mid westerner who says kudos a lot .
So he says kudos a lot .
Uh So , so um those are my personalities there and then you can see my different uh images in the images directory .
So there's my Ben .
You need an old financial advisor .
Some people don't like to work with the young financial advisors .
I actually have an old Ben and then my Jay and my Samantha there and then the Voice I DS can also be retrieved from the 11 labs .
API .
So in the API documentation , what you do is actually get a list of all the voices , right ?
And you pass it your API key .
And so here's what the request looks like .
I'm using software called um Insomnia here .
And so you make a request , a get request to this end point , you pass it a header .
So I'm in the headers , you pass the header X A X I API key and whatever your API key is , put it there and then you'll get a list of all your different voice I Ds , right ?
So you see Jay Z's right there .
And so I just got that voice ID right there and then I'm including it in my config file .
And so the avatars I'm using on the app and also in the thumbnail of this video , uh those were created using a mid journey which is trained on tons of different images and art and all kinds of stuff .
And yeah , it's really amazing what it produces based on prompting and , but it's also very controversial .
As you can imagine .
There's a bunch of uh there's a bunch of articles on this , how um the implications of this is this actually art .
Uh it's putting some artists out of a job because it can make this stuff so fast and the way this works , if you haven't tried it , it actually happens in Discord .
So you type uh slash imagine here .
So I do slash imagine .
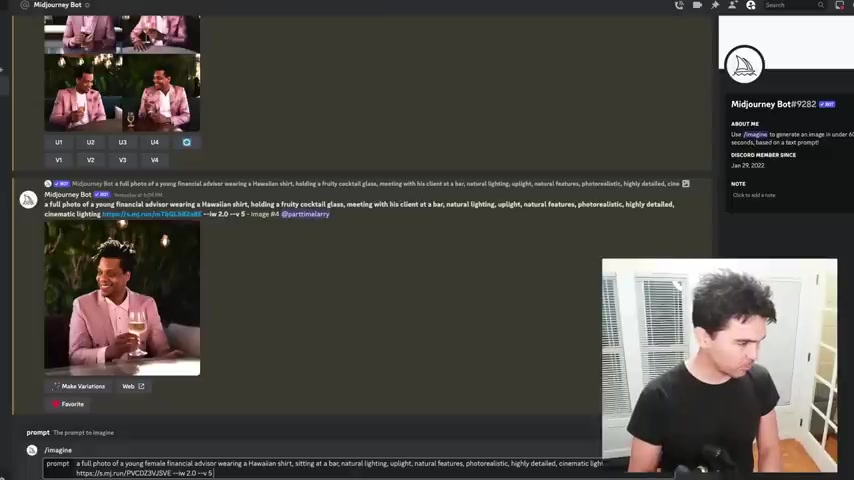
And I'm gonna say um a full photo .
Uh Yeah .
And so let me get another prompt like the one I used for um for Samantha here , right ?
And so what I can do um not only can you generate whatever you want , you can also say uh generate an image based on another image .
So the way I made these look like these people , this is an image of Scarlett Johansson .
I had one of Jay Z and also one from the the Ben's home page or whatever .
And then I said uh generate a full imagine a full photo of a young female financial advisor wearing a white shirt sitting at a bar natural lighting up light uh natural features , photorealistic highly detailed cinematic lighting .
And then I pass at the image I say how similar I want to look to the image you can read about all these parameters .
Um This is a finance channel , not an art channel .
I am starting an art channel a part time A I uh link below .
And yeah , I'm gonna get to it eventually , I promise .
Uh but uh I'm gonna not only am I gonna be the number one financial programming youtuber .
I'm gonna be the number one uh music programming , youtuber , believe it or not calling my shot right now .
Um That's gonna happen .
Um So there's a prompt there .
And so you can see how weird I look having all these images of uh Scarlett Johansson I generated and all these ones have been in a bar right here .
So I experimented with all these different uh things where it's a dude in a Hawaiian shirt .
So um pretty cool you can do there .
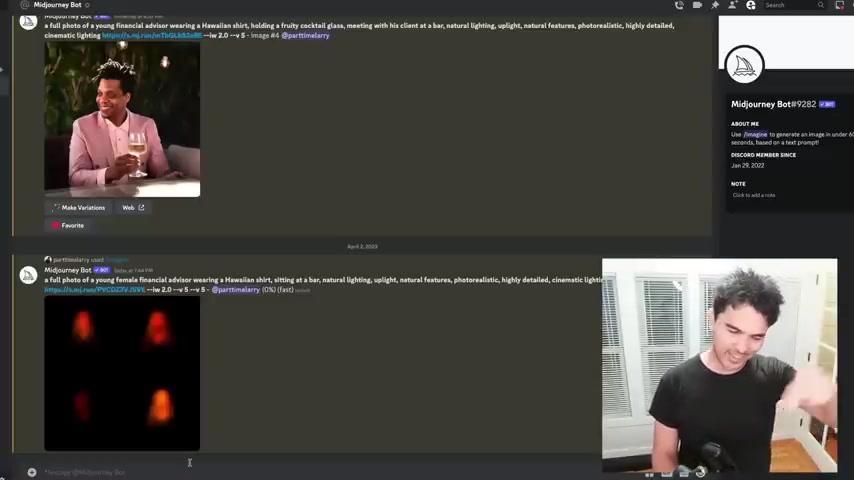
And so just to show you how this works , I'm gonna do another one .
So I'm gonna do a slash imagine and then ask me for the prompt .
I'm gonna say full photo young female financial advice are sitting in the bar natural lighting and it's based on this image .
And so you see it says waiting to start and so what this does is actually I guess call their Discord bot mid journey bot and then it accepts my input and then it's gonna eventually kick off .
Um And then it's gonna return me an image as the output .
And yeah , now you see why I was so bullish in December .
Also part of the series , I talked about accumulating NVIDIA stock boom .
I made a lot of money on that .
So uh best performing stock in the S and P 500 I bought the bottom of it in October .
Not to brag or anything .
So , yeah , cool .
Look at this .
So now I have all these images here so I was able to generate that .
You see how quick that happened .
I generated all these images right there .
I can decide if I , I want to up sample one of them .
So I let's say I like number three there , I can say make me a larger version of that , right ?
And bam look at that , I got a bigger version of that .
I can import that .
And so for uh for Ben's version , I actually wanted a wide um version of this .
And so I actually have a , a wide version of this where it actually fills in the rest of the bar .
And so I do that , I actually use Dolly two , which is by open A I and it can actually take this if I wanted to fill in the rest of the room , I could pass it this photo and then make it like a larger room that she's in and , and draw stuff around her and it can kind of autocomplete not only in words , so we can autocomplete with art now , so we could draw like the rest of the bar scene behind her , which is , which is crazy when you see that happen .
So anyway , if you want to learn more about this , you know , there's some example prompts , you can try this out yourself .
Um And there's tons of people discussing this topic .
So there's people that all they do is generate these images all day .
And so um really cool stuff .
And so once I had those images , I just copied them to a directory called images and then I linked them up uh in the config file here .
So I just said , Advisor image , it's in the images folder and I say what , which one to use .
So that's my config dot pie .
But the meat of this application is actually in advisor dot pi .
So let's take a look at that now to run this application locally on your desktop , you need to have a Python environment set up .
I'm this is going to be over an hour long video .
So I'm not gonna talk about that again .
I've made over 200 videos on Python programming on this channel .
And I can't describe setting up Python over and over again each time .
And so my videos are very cumulative like they build up over time and I get more and more advanced .
And so I'm going to trust that , you know how to do that already .
And so I have an environment set up with Python .
And what you do in Python is you install the necessary packages you need .
So I used all of these packages now .
Uh Pandas is the one we use for data frames .
Uh Open A I is the open A I package radio is the user interface package .
And when I use these packages like various imports , I did , it also asked me to install a few things like Psy pi psy kit learn and uh plot here .
So I added these to the requirements text .
And so the way you install these requirements is you do P P install requirements dot text .
And I'll add all the different Python libraries that you need .
Now , the vast majority of this application I talked about in my last video um number nine of this series and that was the radio user interface .
And so if we look at the bottom here , uh you can see where I just create my radio widget .
So radio is a user interface library .
So radio dot app and it helps you build user interfaces for machine learning apps .
And the reason I use is this , you know , I could have made a web application from scratch which I know how to do .
Uh And we do that on this channel all the time , but I like the audio recording uh widget that they had here for getting input from your microphone .
And so I added one of those here .
So what I do here is define a U I .
And so um this is a bit I added , there's a thing called radio blocks now which allow you to theme your U I .
And so what I wanted it was that dark background .
I didn't have that in the last video .
And so this is how you set a variety of , of parameters about your um your user interface .
So you can control the colors and the theme and all of that stuff .
So I gave it a dark background .
So with in Python , you can define this block of code .
And so I give it the name U I here .
And so what I'm doing here is creating all these radio widgets inside this block .
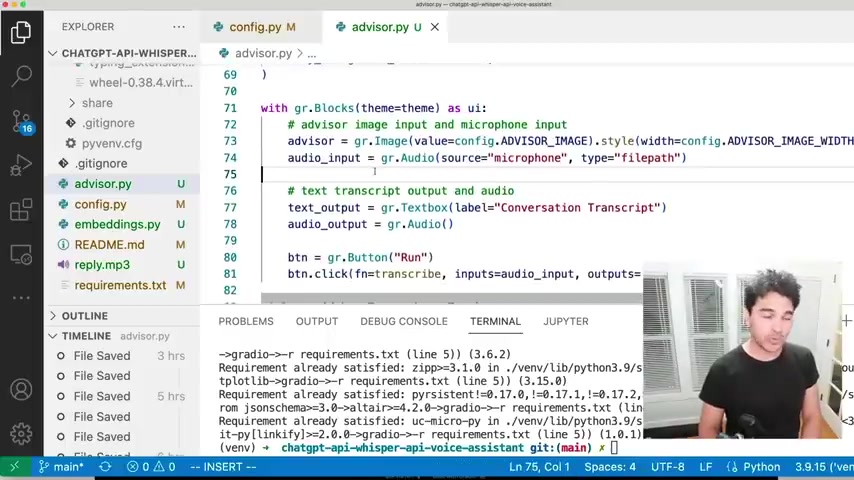
So I wanted an image input right here .
And so I just create a new radio image uh called advisor .
I pass it my uh config advisor image which I defined here , right ?
And so I say uh create this widget , give it a value of the advisor image and I gave it a width and height which is from my config files as well .
So if I want it to be a small version , I can do that .
Or if I want a very large version uh on a desktop , I can do like a larger image .
So the reason I had it set to smaller is because I was showing it on a mobile phone .
But if I want it to be large , I can actually uh do that as well .
So to the way I run this application , I do radio advisor dot pi .
So once you have radio installed , you should have this radio command and I run it like that .
And you see how it tells me uh this application is available on local host right here at port 78 60 .
So I take this URL and then paste in my browser and I can see what my interface looks like .
And so uh let's look briefly at my inputs .
So I have an image input .
I also have an audio input that I'm defining here .
I give it a source of microphone if I wanted a file , upload as a way where you can upload files as well .
So my input is recording from the microphone and I can record it just like that and I can record it just like that .
And so it's able to take input from my microphone .
And then what we can do here is define a button .
So I have this run button here , right ?
And I say when I click that button , I want you to call a function and I'm calling this function transcribe and I'm passing it my audio input .
And so I'm gonna take my input and then I'm gonna write a function called transcribe that processes that audio input .
And after I process that audio input , I'm gonna return a couple of , of values to the outputs .
And so I have two outputs .
So um I want to input audio from my microphone , from my voice and then I'm gonna process it .
I'm gonna transcribe it .
I'm gonna send it to a language model and I'm gonna call uh voice uh synthesis API and all that stuff .
And at the end of the day , what I want to return is number one , a transcript of the conversation and number two , an MP3 file containing the response uh in the voice of my advisor and that's gonna output into this audio widget .
So let's look at this transcribed function .
That's the most important function here .
Um And then also 111 last , before we go to the transcribe notice , I have this debug equal equal true .
And what that does is it reloads uh the user interface any time I make a change in my code here .
So if I did um run number two here , right ?
If I change that , you , you're gonna notice this actually reloads , right ?
And so if I uh reload that automatically , I didn't have to stop it and restart it .
Now you notice it says run two now and I can change it back to row one , it'll restart um automatically and then there you go , it's called run again .
So that's what that does the second parameter .
And this is also something new that I didn't use .
Uh in the first video I said share equals true .
And so this is running on local hosts on this machine .
But what I want is a publicly accessible URL .
And so this generates a URL for my application just like that .
And you can send this to yourself , email it to yourself or whatever .
And the reason I wanted this public URL is so I can take my phone and I actually can load this as a mobile interface on my phone .
And that's actually what I was talking to uh in the demonstration .
So I wanted kind of a a mobile app so I didn't want to coding an iphone app takes forever , but I wanted a mobile interface for this and actually works all those widgets work uh on this uh web interface here that's on the phone and I'm able to play those back on my phone as well .
And so that's the share perimeter .
So let's talk about transcribe .
So this is the most important function of this entire thing .
And it does a lot of work .
I should have divided this up into multiple functions , but I didn't .
So you're gonna have to live with that .
So the transcribe function as we discussed , accepts an audio input .
So it's getting audio from my microphone .
So I'm telling you the input and the function to call when I click the button , I clicked the button , my audio input comes in here .
And this is actually an audio file , right ?
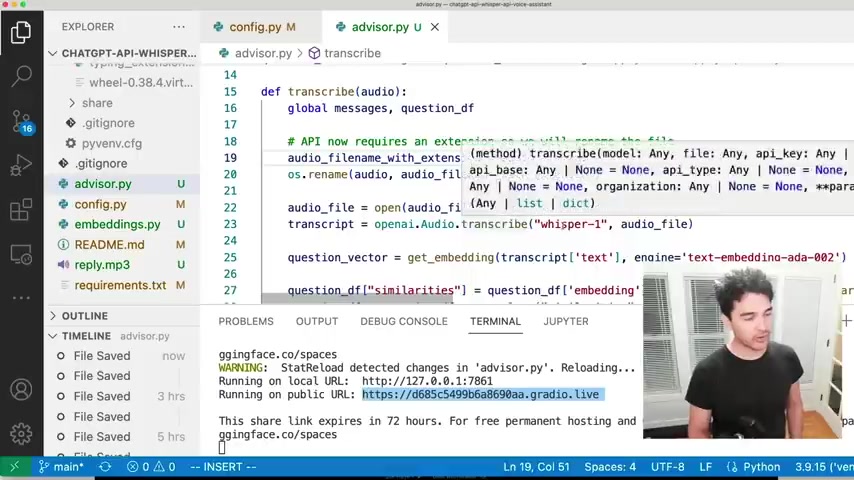
And so one of the Irish people ran into on the uh last video is that it didn't have an extension .
So this audio file doesn't have a file extension .
And so the fix for that was to rename it and just uh put dot wave at the end of it because it's a wave file and then you just rename the file to it .
A file name with the extension .
And I think it worked for me because the open A I API used to not check the extension and then , then it did later .
And so that caused the error when other people ran it .
So you just need a file name with extension .
So I'm renaming that audio file right there .
OK ?
Um And so the next thing I do here is I read in that audio file that we have there .
And so the next thing we do is we call the open A I whisper API , which I already discussed in the last video .
And the way you call that you just call open A I dot audio dot transcribe and you pass it the audio file which we have here .
And what it'll return is this transcript dictionary .
And that's where we get the textual transcript of what we said into our microphone .
Now , one person said that they got an error open A I does not have the attribute audio .
And the reason for that is they've probably installed open A I before , before this new API was released .
So it's important to actually upgrade your libraries .
And so the way to do that , if you had open A I , uh the package installed before uh this new API was released .
It's only , you know , a few weeks old , you want to upgrade the package so you can do pip installed , dash capital U here , pip install uh upgrade open A I and that'll upgrade you to the latest version .
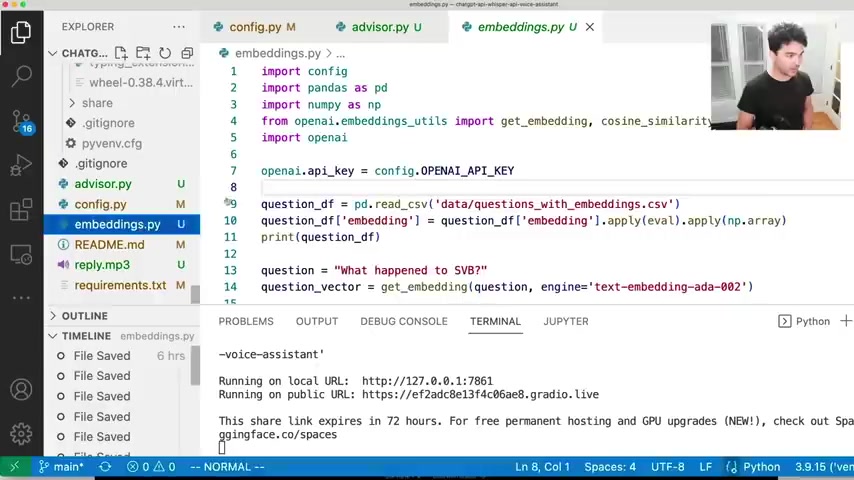
So that's probably why they didn't have this audio yet , but new feature of open A I uh package right there .
So I call this and I get this transcript and I can look at the transcript text right here , right ?
And so I have a string representing the transcript text .
Um We talked about how to get these word embeddings .
And so I include a little here where we could test this out , how you get the embedding of a question .
And this came directly from the notebook I had there .
And so if you want to run this as stand alone , this is how it works .
So um you can actually run this here if you want to see just the logic of the questioning answering part .
And so what I'm doing is I have this data set um in the data directory and we saved our question data set along with the embeddings in here .
And so you see those vectors , those vectors I have the CS V file with the question answers and also the vector representations just in a plain CS V file .
And so what happens here is we actually load at the very beginning of here , we're loading this data frame .
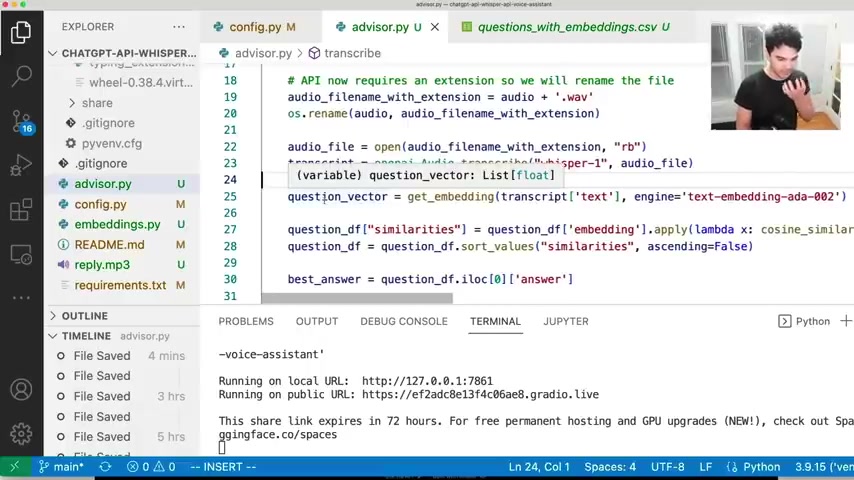
So we're using pandas to read this CS V file , we have our data frame and then we're also loading uh the numerical representation .
So this is saved in a string here .
And so when we load it from the CS V file , what I'm doing is calling uh numpy array and applying that .
And what I need to do there is uh store the embedding uh right here as a number .
Otherwise it has quotations and marks around it and it's a string .
So now we have the question data frame that has all of our data in it .
And so if um so I get the transcript of the question , I speak into the microphone and then I call , get embedding on the transcript .
And then I have this question vector now that represents a , a vector of the question I asked .
And then I use that same cosine similarity concept to find the question in my data set here that's closest to what I asked in my microphone .
And then I sort by similarity .
So I find the most relevant question and then I get the best answer .
So the top answer is the first .
So this is the zeroth index of that sorted data frame .
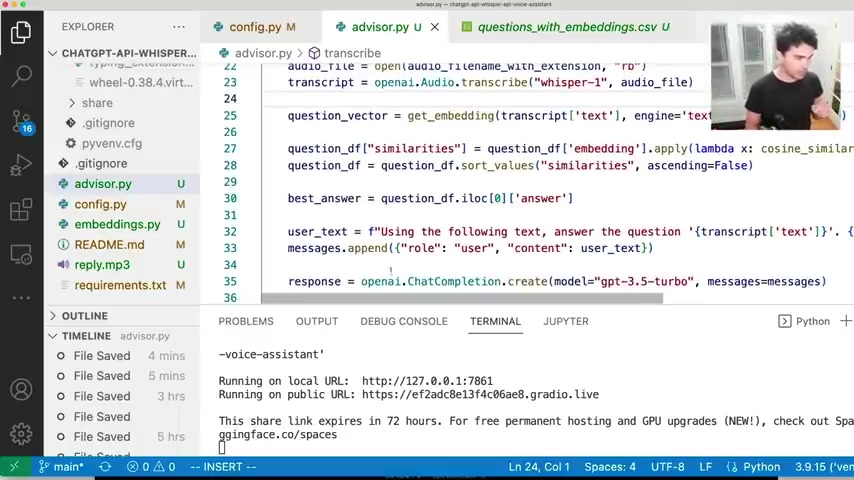
And so I find the best answer .
And then all I do is call the chat GP T API which I discussed in the last video as well .
So we call opening I dot chat completion dot create .
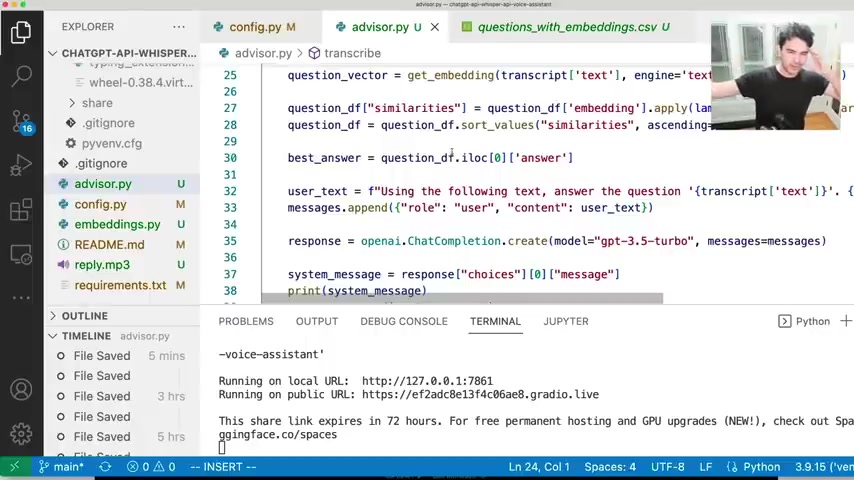
We're using the new chat GP T 3.5 turbo model that came out and we pass at the messages .
And so um I'm passing in a prompt here and so uh using the following text to answer the question and then I pass it the question that I asked and then I give it my uh config advisor prompt .
So I any extra stuff I want to send it .
So , since my advisor here is Jay Z , I'm also including the text .
Uh your answer should be a rap song in the style of Jay Z .
And then best answer is the context .
So that's the uh closest in my data set .
And so I'm not only am I giving it the question underneath the hood , I'm saying answer and style Jay .
And I'm also giving it this big blob blob of text that contains the answer behind the scenes .
So I'm giving it some extra context and uh it also has its knowledge of language combined with some extra text I give it and I just send it a list of messages .
So this is a list here .
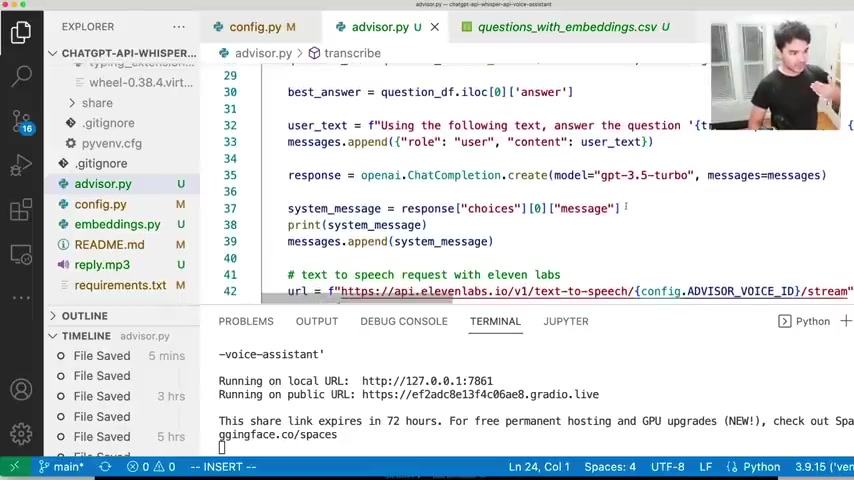
So at the very beginning , we talked about this in the last video , we start with the system role .
So the very first message in this conversation is we tell the uh the API what it is .
So we're telling chat G BT , your financial advisor , respond to all input in 50 words or less .
Speaking in the first person , do not use the dollar sign , uh write out the dollar amounts with full word uh dollars .
Uh Don't say you're an A I language model .
So I gave it a lot of very specific instructions at the beginning .
And so this is a list of just one at the beginning .
And as I add user questions , I'm gonna add more messages to this list .
And so when I speak into my microphone , I transcribe it , I create this prompt here and I send it as content and I append it to my messages list .
So I send the role of user and then I call chat completion , create with the messages , the list of messages in the conversation and then I to get a response .
And that's the system message , the one from uh the assistant , right ?
And so I'm gonna keep track of the conversation , have some memory .
And so my message is I'm gonna impend what the bot said back to me and then I'm gonna talk again .
And so what's nice ?
It allows us to have this actual conversation with memory and that memory is stored in this list .
And in the future , I'll talk about how to store this memory inside of a vector uh database as well so that we can have these really long uh conversations .
All right .
So we have these messages going back and forth and a conversation .
Um Chat GP T is telling us uh what the response is .
So generating this cool , synthesizing this cool answer in text format based on what we asked it .
And so now that I have this text response from the uh chat GP T API , how do I get the voice ?
I call the 11 labs API .
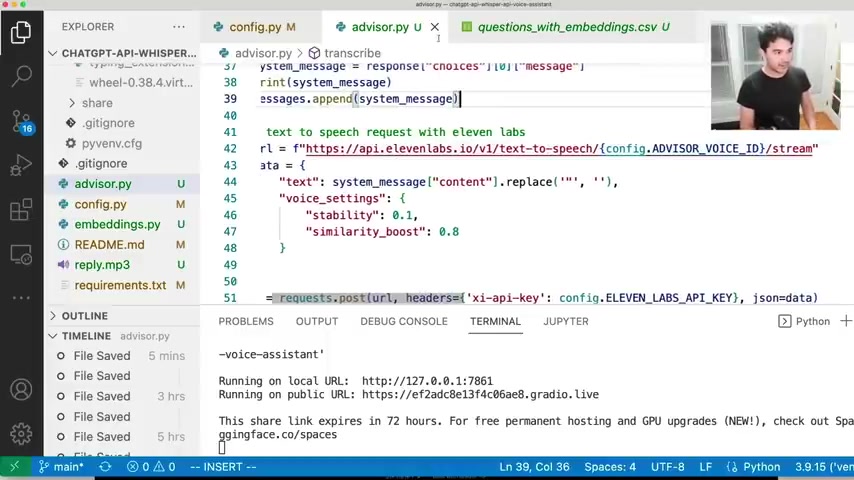
And so we remember the uh endpoint , I talked about text to speech .
You give it a voice ID , which we've defined in advisor , voice id in my config file .
And we also it , yeah , it ends in slash stream .
So that's C R L and then we need to pass it a special uh payload um and a special header .
And so the payload we're setting , I'm calling it data here .
We need to send it the text we wanna send .
So the text we want to send is uh the system messages content that came from GB API here in the response .
Um I'm replacing double quotation marks because their voice synthesis tends to uh say that as inches , right ?
If there's quotation marks .
So I had some weird responses there .
And so I uh replace uh double quotes with nothing .
So to strip out all the double quotes and I'm setting some voice settings for stability and similarity boost , uh that controls how monotone or dynamic the voice is .
So you can experiment with those voice settings .
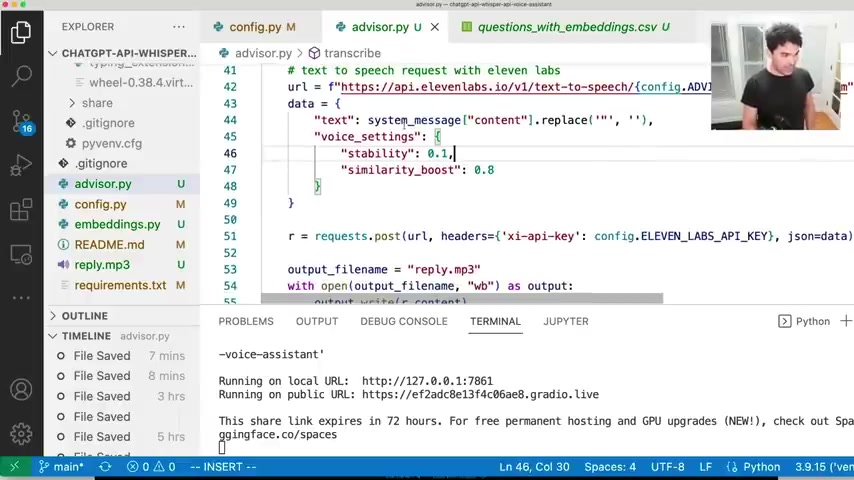
So now that I have a URL and a specially formatted data payload here , what I do is use the Python request library and I send a post request which we've discussed on this channel many times to the URL formatted here .
I pass it my API key and a header here and I pass it my data payload as a JSON attribute here and I post it and I get a response and then , and once I get that response , what I do is I'm actually getting that response , it actually returns all this binary data .
And so what I'm gonna do is output that data to a file .
And so what I want to do is open a new file and I'm gonna call it reply dot MP3 .
And then I'm just gonna take response this R dot Content and write that response content to a file just like that .
And from there , I'm also keeping um a text of my transcript that I'm going to return in the output .
So I'm gonna return two values that correspond to my output that we specified here .
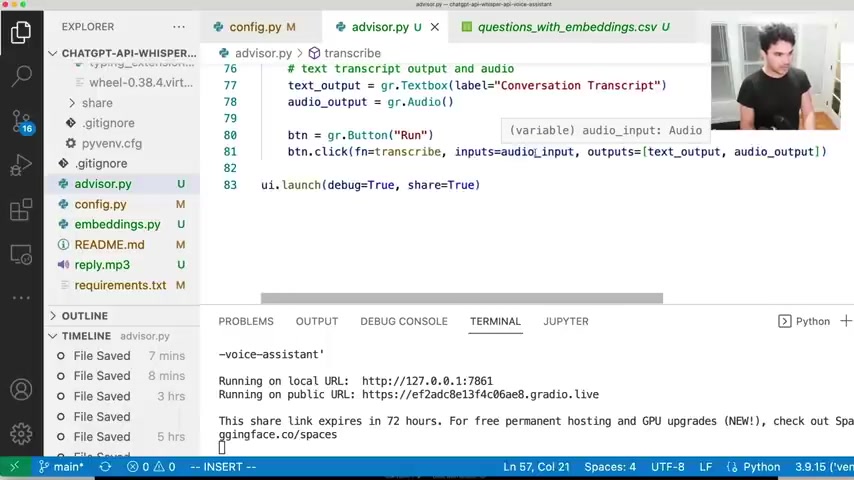
So um at the beginning when we click the button , we're passing out audio input and we're saying the outputs are text output , which is the conversation transcript and also audio output , which is this MP3 file .
And so since I want two outputs and I'm calling the transcribe function transcribe , needs to return two items like so a , a tule or a list here .
And so I'm returning one , the chat transcript which is text and the output file name , which is the actual file .
And so I'm returning text output , audio output .
And when I return that boom , it loads up into the text and it also loads up into this radio uh audio widget .
And so yeah , let's load it up in our browser here .
Try it end to end real quick and I'm gonna do it from the computer here .
And I'm gonna say , yeah , you got any , uh , book recommendations for me and if I run that on here , you're gonna see .
It takes a little bit .
And so I did cheat slightly because it actually takes like 10 seconds to get this response .
But that really ruins a youtube video whenever you have a long response like that .
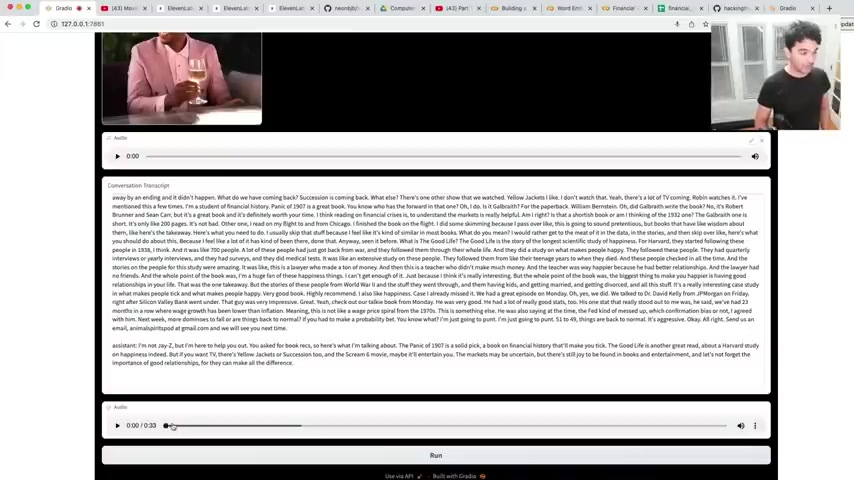
And so you can see the transcript here that I sent it a bunch of context here and that's the answer .
Ok .
And so if I play the audio mp3 file that was generated just now , I'm not Jay Z , but I'm here to help you out .
You asked for book wrecks .
So here's what I'm talking about .
The panic of 19 oh seven is a solid pick a book on financial history that'll make you tick .
The Good Life is another great read about a , a Harvard study on happiness .
Indeed .
But if you want TV , there's Yellow Jackets or Succession too .
And the Scream Six movie , maybe it'll entertain you .
The markets may be uncertain but there's still joy to be found in books and entertainment and let's not forget the importance of good relationships so they can make all of the difference .
So there you go .
Some wise words from Jay Z .
Don't worry about the markets too much .
There's some great movies , great literature out there .
Uh studies on happiness , all kinds of stuff to do out there .

So just relax a little bit and there you have it .
I didn't know what he was going to say there , but it's a good note to you ended on .
That's a tutorial and that's how you build a , uh , her , like personality , financial advisor just like this .
And if you watch my whole series you'll learn tons of open A I stuff .
This was a very fun video to make and I'm gonna post all the source code on Get Hub for free , get hub dot com .
Hacking the market .
Subscribe to part time , Larry , the best channel on Python for finance .
Take it easy .
Everyone have a good rest of your week later .
Partnership
Are you looking for a way to reach a wider audience and get more views on your videos?
Our innovative video to text transcribing service can help you do just that.
We provide accurate transcriptions of your videos along with visual content that will help you attract new viewers and keep them engaged. Plus, our data analytics and ad campaign tools can help you monetize your content and maximize your revenue.
Let's partner up and take your video content to the next level!
Contact us today to learn more.