https://youtu.be/yN7ypxC7838
All Machine Learning Models Explained in 5 Minutes _ Types of ML Models Basics

Welcome to Whiteboard programming where we simplify programming for you with easy to understand whiteboard videos .
And today , I'll be giving you a brief explanation of all machine learning models .
So let's get started broadly speaking , all machine learning models can be categorized as supervised or unsupervised .
We'll uncover each one of them and what all types they have .
Number one supervised learning .
It involves a series of functions that maps an input to an output based on a series of example , input output pairs .
For example , if we have a data set of two variables , one being age , which is the input and the other being the shoe size as output , we could implement a supervised learning model to predict the shoe size of a person based on their age .
Further with supervised learning , there are two sub categories .
One is regression and the other is classification in regression model .
We find a target value based on independent predictors .
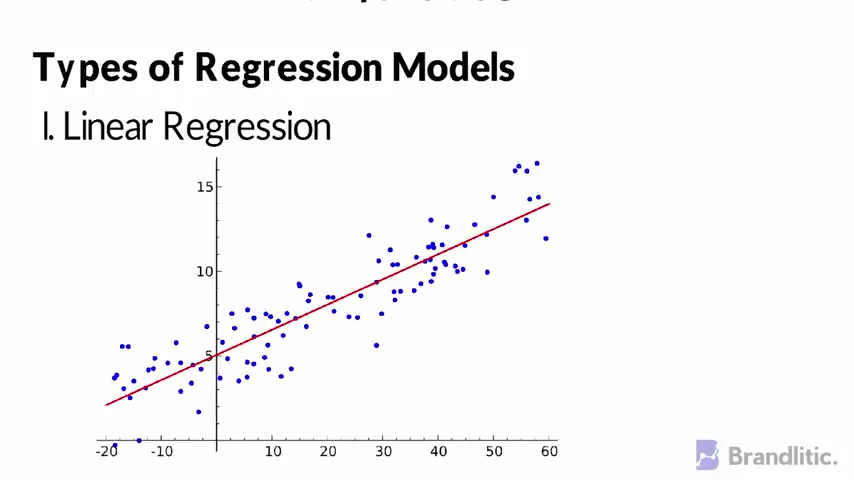
That means you can use this to find a relationship between a dependent variable and an independent variable in regression models .
The output is continuous .
Some of the most common types of regression model include number one linear regression , which is simply finding a line that fits the data .
Its extensions include multiple linear regs that is finding a plane of best fit and polynomial regression .
That is finding a curve for best fit next one decision tree .
It looks something like this where each square above is called a node and the more nodes you have the more accurate your decision tree will be in general next .
And the third type random forest , these are assemble learning techniques that builds off over decision trees and involve creating multiple decision trees using bootstrapped data sets of original data and randomly selecting a subset of variables at each step of the decision tree .
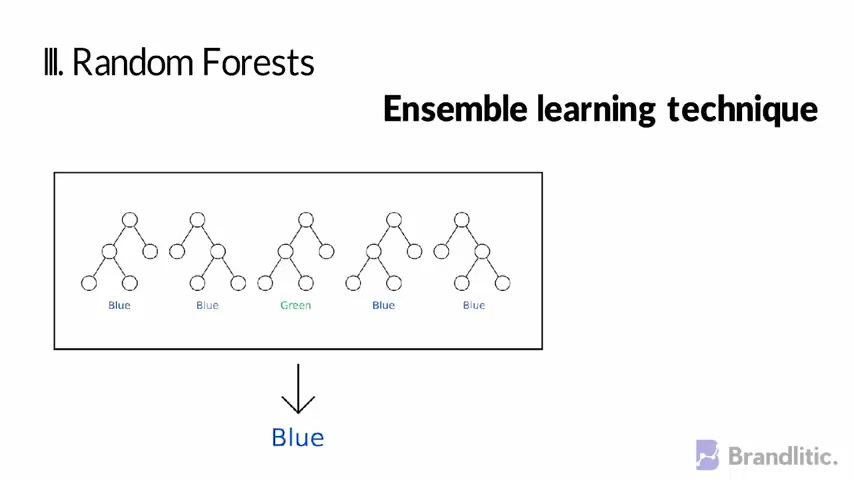
The model then selects the mode of all the predictions of each decision trees .
And by relying on the majority wins model , it reduces the risk of error from individual tree next neural network .
It is quite popular and is a multilayered model inspired by human mind like the neurons in our brain .
The circle represents a node .
The blue circle represents an input layer .
The black circle represents a hidden layer and the green circle represents the output layer .
Each node in the hidden layer represents a function that input goes through ultimately leading to the output in the green circles .
Next classification .
So with regression types being over now let's jump to classification .
So in classification , the output is discrete .
Some of the most common types of classification models include first logistic regression which is similar to linear regression but is used to model the probability of a finite number of outcomes .

Typically two next support vector machine .
It is a supervised classification technique that carries an objective to find a hyper lane in N dimensional space that can distinctly classify the data points next nave base .
It's a classifier which acts as a probabilistic machine learning model used for classification tasks .
The crux of the classifier is based on the base theorem .
Coming up .
Next decision trees , random forest and neural networks .
These models follow the same logic as previously explained .
The only difference here is that the output is discrete rather than continuous .
Now , next , let's jump over to unsupervised learning .
Unlike supervised learning , unsupervised learning is used to draw inferences and find patterns from input data without references to the labeled outcome .

Two main methods used in supervised learning include clustering and dimensionality reduction .
Clustering involves grouping of data points .
It's frequently used for customer segmentation , fraud detection and document classification .
Common clustering techniques include K means clustering , hierarchical clustering , mean shape , clustering and density based clustering .
While each technique has different methods in finding clusters , they all aim to achieve the same thing coming up .
Next dimensionality reduction , it is a process of reducing dimensions of your feature set or to state simply reducing the number of features .
Most dimensionality reduction techniques can be categorized as either feature elimination or feature extraction .
A popular method of dimensionality reduction is called principal component analysis or PC A .
Obviously , there's a ton of complexity .
If you dive into any particular model to help you with each , I'll be publishing new videos .

So be sure to smash that subscribe button to be notified on every upload .
Next .
If this video helped you , be sure to like it and share it with someone who might need it .
Are you looking for a way to reach a wider audience and get more views on your videos?
Our innovative video to text transcribing service can help you do just that.
We provide accurate transcriptions of your videos along with visual content that will help you attract new viewers and keep them engaged. Plus, our data analytics and ad campaign tools can help you monetize your content and maximize your revenue.
Let's partner up and take your video content to the next level!
Contact us today to learn more.